
3 Data Science Projects That Got Me 12 Interviews. And 1 That Got Me in Trouble.
3 work samples that got my foot in the door, and 1 that almost got me tossed out.

Analyzing My Data Science Portfolio Projects
Like many graduates, I did not have a job lined up after earning my data science master’s degree; the reason is because I didn’t apply anywhere.
For three months.
I graduated in spring time but didn’t begin my job search, in earnest, until summer.
Either fear or foresight compelled me to believe I wasn’t ready, and that emotion drove me to invest the hours I wasn’t working an hourly job at a local hotel into crafting a marketable, desirable data science portfolio.
When I receive comments and LinkedIn messages with questions related to breaking into the data industry, my first tip is always to create a GitHub-hosted portfolio that you can use as a professional calling card.
Bonus points if you create engaging documentation or share that content on a platform like Medium or LinkedIn to connect with potential hiring managers.
While I’ve written about the importance of having a side project, even as a working professional, and shared my communication tips for presenting data projects, I realized that I’ve never shared the contents of my own portfolio.
My hope is that, for those of you wondering where to start when it comes to displaying your work, you’ll see real examples of what kinds of projects catch a recruiter or interviewer’s eye and why.
Before I share my work and process, I have to acknowledge that while I had no formal tech background, I did have the following traits recruiters and managers found desirable (based on feedback, not my egoism, I swear):
- A master’s degree in data science
- Domain knowledge (I purposely applied for roles within the media, education and hospitality industries, all of which I’ve worked in before)
- Python/SQL/BI development experience (course work, personal projects)
- Communication skills (a huge plus, even for junior engineers or developers)
Note: Needless to say, your results may vary.
Project 1: Udemy Course Data Analysis Dashboard
Update: Since original publication, I’ve created a walkthrough of this project so you can understand not only the code, but the process behind its conception and execution.
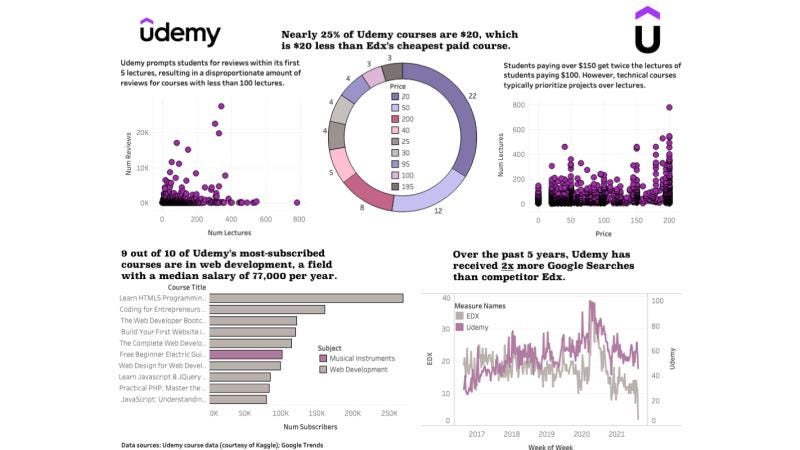
Summary: A static dashboard that combined Google Search data and a dataset from Kaggle to draw insights about course attendance and content demand on the Udemy course hosting platform.
Tech Used:
- SQL
- Tableau
- Python
Datasets:
- Udemy dataset from Kaggle
- Google Trends data
Key insights shared:
- Nearly a quarter of Udemy’s courses cost less than $20, which is $20 less than the average price of competitor Edx
- Over the past 5 years Udemy has received nearly 2x the Search traffic of Edx
- 9 out of 10 of Udemy’s most subscribed to courses are in web development
Why this project works:
- Domain relevancy (I was applying to an education company)
- Demonstrated data visualization best practices
- Showed ability to conduct competitive analysis
Project 2: The K-Word
Summary: After years of headlines involving various ‘Karens’, I decided to investigate trends related to the popularity of the name ‘Karen’ over the past 100 years and create visualizations to turn into a data-driven story.
Tech used:
- Python
- BigQuery (database)
- BigQuery (SQL)
Datasets:
- Social Security baby name data (BigQuery)
- Google Trends
Key insights shared:
- Karen hit its peak in 1957, with an average of 725 Karens born
- Karen has a positive correlation with searches for ‘racist’, ‘nasty’ and ‘manager’ and a negative correlation with searches for ‘kindness’
- Spain, Iraq and Iran are the non-U.S. countries that searched for the ‘Karen’ insult the most
Why this project works:
- Novelty
- Narrative flow
- Use of multiple data sources
- Clear visualization
Pardon the interruption: For more Python, SQL and cloud computing walkthroughs, follow Pipeline: Your Data Engineering Resource.
To receive my latest writing, you can follow me as well.
Project 3: Churn Prediction in Massive Open Online Course Enrollment
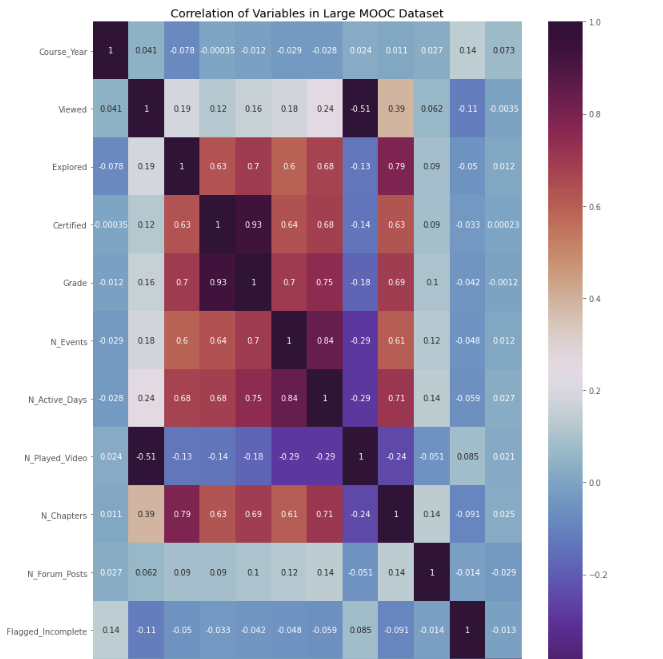
Summary: Using multivariable logistic regression, I created 4 models to determine the likelihood for churn by MOOC students, a group known for their well-documented lack of commitment to educational products.
Tech used:
- Python
- GitHub
Datasets:
- Edx data (Kaggle)
Key insights shared:
- Despite a 90% accuracy, the model precision was considerably lower (high 60%)
- Best predictors of likelihood to churn included: Percentage of course complete, percentage of course audited and whether or not the individual held a bachelor’s degree
- Reduction of features created a more precise model, with accuracy and precision metrics hovering around 95%
Why this project works:
- Tackles a pervasive business problem: Churn
- Demonstrates proficiency in building ML models
- Shows ability to interpret and present model results
And The Project That Got Me in Trouble…
Tragedy Porn
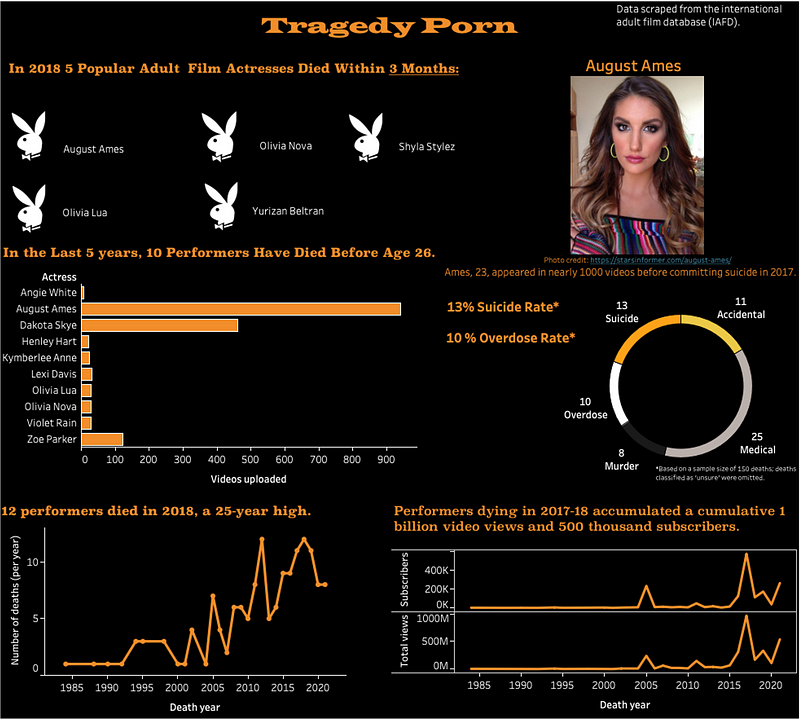
Summary: In 2018 5 adult film stars died within 3 months. Though most of the deaths were underreported, the suicide of porn star August Ames, 23, brought renewed attention to an industry that has experienced a surge in performers dying before age 30 due to suicide, overdoses and violence.
Tech Used:
- Python
- SQL (SQL Lite)
- Tableau
Datasets:
- Custom dataset built by combining data scraped from Wikipedia with Kaggle data
Key insights shared:
- In 2018 5 popular adult actresses died within 3 months of each other
- In the last 5 years, 10 performers have died before age 26
- 12 performers total died in 2018, marking a 25-year high
Why this project works:
- Demonstrated an ability to create a custom, aggregated dataset (a super important skill for any data job)
- Featured data scraped from the web (a very marketable skill)
- Displayed knowledge of visualization best practices
- Tells a clear, easy-to-follow data story that engages an audience
Why It Got Me in Trouble
(By Now, You Can Probably Guess)
I presented this project during a panel interview with senior data analysts.
In the moment they were engaged and asked questions about how I gathered, manipulated and displayed my data.
By all accounts, the interview went well.
Then the recruiter called.
While she was happy to inform me I was advancing to the next interview round, she suggested that I maybe not present a dashboard called ‘Tragedy Porn’ to the company’s executives in the final interview round.
She shared that my interviewers suggested that, while the analysis was solid, the content was a bit controversial (to say the least).
I come from the world of journalism and media where very few topics are off the table, so this was a learning experience for me.
In the end, I did get and then decline an offer from the company.
Overall it was a fine experience with a valuable lesson for any candidate: Know your audience and target your content accordingly.
Recap
Data science portfolios are not to be taken or to be assembled lightly.
Recruiters, interviewers and your future bosses can absolutely distinguish between a thrown-together repo of code vs. a true, well-honed portfolio.
While your goal shouldn’t be to replicate the work I’ve shared here, there are certainly lessons to be learned:
- Make sure your chosen projects focus on analyzing or attempting to solve real business problems (bonus points if these include problems your target organization faces).
- You’ll more than likely be laboring over these projects for many unpaid hours. Pick topics and data that interest you.
- Interpreting and presenting results is an overlooked but highly valuable skill. Learn how to confidently present and answer follow-up questions.
- Do your homework and try to use technology that mirrors what your target organization uses. Many job descriptions I encountered featured heavy Python and SQL needs, hence the focus.
- Know your audience and choose topics accordingly.
Hopefully, if you’re seeking to enter this field, you are passionate about data (or at least interested to the extent that you can do the job without getting too bored).
In addition to sharing your portfolio, don’t be afraid to share the story behind your process with your interviewers.
Managers want candidates that are passionate about data and solving business problems. Show them evidence that these descriptions apply to you.
For more data science skill building, check out my latest work:
Create a job-worthy data portfolio. Learn how with my free project guide.




