

WordNet: A Lexical Taxonomy of English Words
What is WordNet and why is it useful?
INTRODUCTION
When it comes to Natural Language Processing (NLP), automatically understanding and analysing the meaning of words, as well as pre-processing textual data, can be a challenging task. To support this, we often use lexicons. A lexicon, word-hoard, wordbook, or word-stock is the vocabulary of a person, language, or branch of knowledge. We often map the text in our data to the lexicon, which, in turn, helps us understand the relationships between those words.
A really useful lexical resource is WordNet. Its unique semantic network helps us find word relations, synonyms, grammars, etc. This helps support NLP tasks such as sentiment analysis, automatic language translation, text similarity, and more.
This post aims to show some of WordNet’s features and discusses how you can gain new insights about your language data.
WORDNET
WordNet is a large lexical database of English words. Nouns, verbs, adjectives, and adverbs are grouped into sets of cognitive synonyms called ‘synsets’, each expressing a distinct concept. Synsets are interlinked using conceptual-semantic and lexical relations such as hyponymy and antonymy.
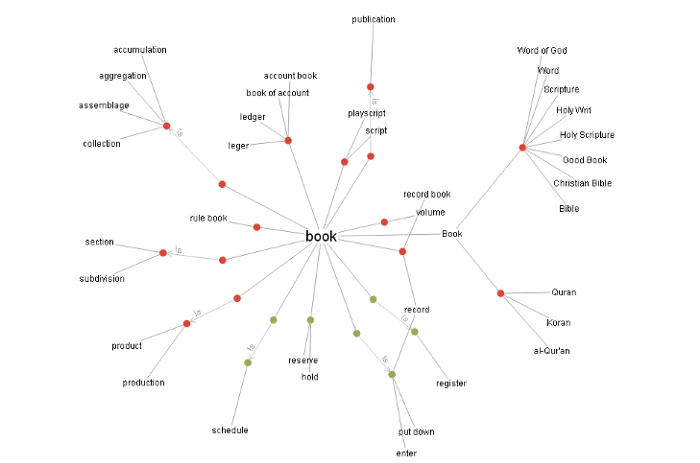
In WordNet terminology, each group of synonyms is a synset, and a synonym that forms part of a synset is a lexical variant of the same concept. For example, in the network above, Word of God, Word, Scripture, Holy Writ, Holy Scripture, Good Book, Christian Bible and Bible make up the synset that corresponds to the concept Bible, and each of these forms is a lexical variant.
WordNet superficially resembles a thesaurus, in that it groups words based on their meanings. However, there are some important distinctions.
- First, WordNet interlinks not just word forms — strings of letters — but specific senses of words. As a result, words that are found near one another in the network are semantically disambiguated.
- Second, WordNet labels the semantic relations among words, whereas the groupings of words in a thesaurus does not follow any explicit pattern other than meaning similarity.
WORDNET IN THE WILD
The Natural Language Toolkit (NLTK) is an open-source Python library for NLP. What’s great about it is that it comes with several corpora, toy grammars, trained models, and the topic of interest for this blog, WordNet. The NLTK module includes the English WordNet with 155,287 words and 117,659 synonym sets.
Import
WordNet can be imported from NLTK using the following:
Words
We can look up words which are a part of the WordNet lexicon using the synset() and synsets()function.
A synset may be defined with a 3-part name of the following form:
synset = WORD.POS.NN
where:
- Word — the word you are searching for.
- Part of Speech (POS) — a particular part of speech (noun, verb, adjective, adverb, pronoun, preposition, conjunction, interjection, numeral, article, or determiner), in which a word corresponds to based on both its definition and its context.
- NN — a sense key. A word can have multiple meanings or definitions. Therefore, “cake.n.03” is the third noun sense of the word “cake”.
The POS and NN parameters are optional.
Definitions and Examples
From the previous example, we can see that dog and run have several possible contexts. To help understand the meaning of each one we can view their definitions using the definition() function.
Likewise, if we needed to clarify some examples of the noun dog and verb run in context, we can use the examples() function.
Similarity
We can also determine the similarity between words. The path_similarity() function returns a score which denotes how similar two words are by traversing through the paths that connects them in the WordNet network.
WordNet includes several different similarity measures. For example, Wu & Palmer’s similarity calculates similarity by considering the depths of the two synsets in the network, as well as where their most specific ancestor node (Least Common Subsumer (LCS)).
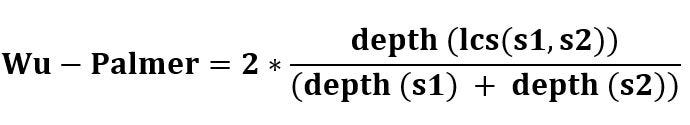
The similarity score is measured between 0 < score and ≤ 1, where 1 indicates that the words are the same. The score can never be 0 because the depth of the LCS is never 0 (the depth of the root of taxonomy is 1).
Let’s consider, for example, the similarities between the verbs run and sprint and the nouns ship and boat. A high score of 0.86 and 0.91 indicates that they are indeed similar to one another. Note, when comparing the similarities between the words ship and sprint, the output is None. This means that a path between these words could not be found.
Why is this useful in NLP?
Language is flexible, and people will use a variety of different words to describe the same thing. So, if you had a large dataset of customer reviews and you wanted to extract those which discuss the same aspects of the product, finding which are similar will help narrow that search.
Hypernyms and Hyponyms
Hypernymy and Hyponymy encode lexical relations between a more general term and specific instances of it.
A hypernym is described a being a word that is more general than a given word. That is, it is its superordinate term: if X is a hypernym of Y, then all Y are X. For example, animal is a hypernym of dog.
Whereas hyponymy is the relation between two concepts, where concept B is a type of concept A. For example, beef is a hyponym of meat.
Why is this useful in NLP?
Knowledge of the hypernymy and hyponymy relations is useful for tasks such as question answering, where a model may be built to understand very general concepts, but is asked specific questions.
Synonyms and Antonyms
Programmatically identifying accurate synonyms and antonyms is more difficult than it should be. However, WordNet covers this quite well.
Synonyms are words or expressions of the same language which have the same or a very similar meaning in some, or all, senses. For example, the synonyms in the WordNet network which surround the word car are automobile, machine, motorcar, etc.
Antonymy can be defined as the lexical relation which indicates ‘opposites’. Further, each member of a direct antonym pair is associated with some semantically similar adjectives. e.g. fat is the opposite of thin; obese’s antonym is also thin as obese and fat belong to the same synset. Naturally, some words do not have antonyms and other words like recommend just don’t have enough information in WordNet.
Why is this useful in NLP?
Again, language is flexible. Synonyms and antonyms can help narrow down the search for similar and opposite texts.
Meronyms and Holonyms
Meronymy expresses the ‘components-of’ relationship. That is, a relation between two concepts, where concept A makes up a part of concept B. For meronyms, we can take advantage of two NLTK functions: part_meronyms()and susbstance_meronyms(). For example, part meronyms of the noun hat include crown and substance meronyms of the noun water include hydrogen.
Holonyms express the ‘membership-of’ relationship, i.e. a relation between two concepts, where concept B is a member of concept A. We can take advantage of two NLTK functions: part_holonyms()and susbstance_holonyms(). For example, part holonyms of the noun car include wheel and substance holonyms of the noun wood include stick.
Entailments
Entailment is a semantic relationship between two verbs. A verb C entails a verb B if the meaning of B follows logically and is strictly included in the meaning of C. This relation is unidirectional. For instance, snoring entails sleeping, but sleeping does not entail snoring.
Multilingual WordNet
WordNet is also a very important translation resource, as it represents one of the largest multilingual dictionary in existence today for the number of languages and the number of words and concepts covered. It is even utilised by Google Translate as a part of the translation process between languages which possess WordNets.
At present, there are versions of WordNet in various stages of development for an enormous range of languages. This includes not just the most widespread and best-known ones such as French, German, Chinese, Spanish or Portuguese, but less well known and minority languages too, such as Albanian, Kannada, Croatian, Basque, Catalan, Galician, and Welsh.
We can return a list of all the available languages in NLTK’s WordNet version using the langs() function, as well as search for the Italian word for dog.
Why is this useful in NLP?
WordNet can be used to perform (crude) language translation.
CONCLUSION
This post covers some of the main features in which WordNet has to offer and how its unique semantic network helps support NLP.
For more on WordNet’s features, see here:





