
用Python + Metaflow完美整合一個資料科學專案

大家好,自從上次的我的弱點的文章,有提到我想要增強我在Data Engineering上的能力,這次的文章我就要介紹Netflix內部非常盛行的資料科學流程管理工具Metaflow,這是一個我覺得非常好的一個開源工具,能夠超級快速的建立和管理不管是個人或是一個團隊的資料科學專案。
相信你或者是你的team會同時擁有一個或好幾個不同的專案在身上,每個專案都必須來來回回處理很多事情,同事也必須一直一直的優化,舉例來說,一個資料科學專案的流程可以如下:
(1) 已定義出一明確的商業問題
(2) 根據商業問題嘗試去分析並提出可實行的解決方案
(3) 透過機器學習演算法來完成解決方案
(4) 將模型部署到是server上
(5) 模型被用來預測的新的資料,被透過訓練來保持最新的狀態
(6) 新資料被預測後會對現今的做法產生新的想法
(7) 將新的想法回到(1)
每個需要預測的資料科學專案最終都會追求越來越精準的模型,所以在不斷接受新需求的情況下,又要能快速改到上面流程的某一個步驟,這樣幾乎無終止的輪迴急需要一個快速改動的能力,又想要都可以在同個程式語言上完成這件事,這就促成了Metaflow的誕生。
接下來我會逐一的介紹和實際使用Metaflow,以下是這篇文章的步驟:
(1) Metaflow介紹
(2) 資料集
(3) 原本專案流程
(4) Metaflow範例
(5) 使用Metaflow來建立專案
(6) 結論
1. Metaflow介紹
Netflix給Metaflow的解釋如下:
Metaflow is a human-friendly Python library that helps scientists and engineers build and manage real-life data science projects. Metaflow was originally developed at Netflix to boost productivity of data scientists who work on a wide variety of projects from classical statistics to state-of-the-art deep learning.
這個工具不像其他機器學習演算法可以直接增加你模型的表現,但是可以提高你在專案的生產力,試想,之前你在處理一個專案時,勢必得花許多時間在不斷將過程釐清,以及花上許多時間去程式運行的流暢度,確保每個過程都不可以被忽略,而Metaflow的出現就大大了幫助我們快速的完成這幾項看似簡單,但其時水很深的事情,讓我們能專注在我們所擅長的分析和建模上,Metaflow其實也間接的增加了模型的表現。
2. 資料集
這個資料集我將延續之前如何從頭到尾完成一個資料科學(Data Science)專案所使用的UCI上的銀行行銷資料,之所以一直用同個專案下的同個資料集,這是因為,我希望你可以根據自己的喜好度來使用Pandas或是PySpark,現在再加上Metaflow,你可以從自己的觀點來看這篇文章和之前沒有使用Metaflow的差異,之後如果你需要做其他專案,一定可以大大的增加便利性,能讓你節省很多時間,多做一點分析。
3. 原本專案流程
之前文章中我建立專案的過程是在Jupyter notebook,透過不斷的分析找出可以進行特徵工程或特徵選擇的解決方案,以及最後的建模,當然以分析的方便性來說,Jupyter notebook真的是資料科學家的好朋友,可以很快呈現我們想畫的圖,不用一定要很完整的架構好你的code才能執行,能不斷的試錯,但是當你分析出了可能可以使用的Ingisht,你需要加入到你最新的code中,才能被模型來訓練,而在這個最終需要產出的過程中,總是必須不斷的尋找自己之前的邏輯在哪,那個紀錄某某變數修改的function在哪一個cell,雖然這個動作在長期的訓練下來已經做了無數遍,但是做下一次的時候還是會覺得很痛苦。
4. Metaflow範例
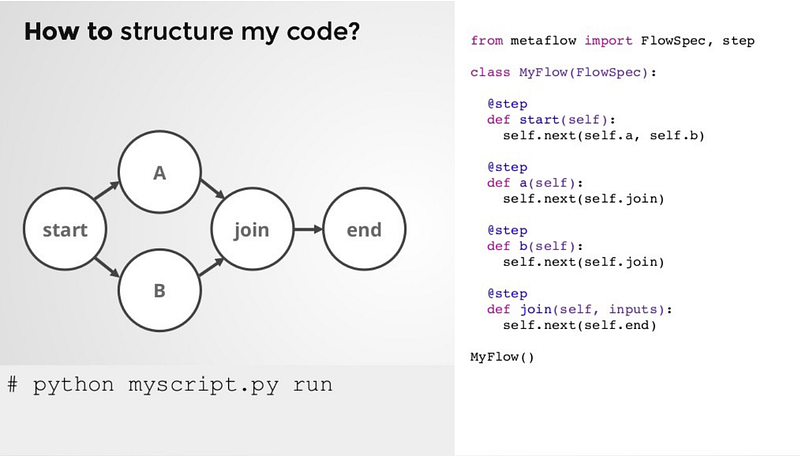
上面的圖片是Metaflow在發布的時候,其展示的圖片,我們可以透過左邊的流程圖看出這個程式碼的運行流程,而右邊就是該流程的code,這個流程如下:
(1) 從Start開始
(2) 進入下一個處理流程,有A, B兩個步驟要處理
(3) 分別完成後整合至Join
(4)最後到End結束
當你把右邊的code打好後,就可以在command line中打上
python myscript.py run來執行這個流程,其就會根據你所下的流程去執行code,最後得出你期待獲得的結果,當然,在真正的Metaflow中不會幫助你產出左邊的圖,但你可以藉由以下的code來檢視你的流程,
python myscript.py show在這篇文章的最後,我也會用這個code展示我這個專案的流程,確保我的code有依據我想要的專案流程來建立。
5. 使用Metaflow來建立專案
那我們開始透過Metaflow來搭配我之前寫的建模流程,各位可以試想一下,現在的我們,已經分析完了資料,知道自己需要做什麼特徵工程或者是相關的特徵選擇,這樣我們就可以開始組織我們的code,之後有新data進來,就可以直接根據我們的code來完成相關的預測了。
首先,資料分析最重要的就是要有資料,我們必須指定資料存放的地址,才能夠在之後run程式時能夠自動地吃到我們的資料。
def script_path(filename):
import os
filepath = os.path.join(os.path.dirname(__file__))
return os.path.join(filepath, 'bank-additional', filename)我會把資料放在bank-additional的資料夾中,這個py檔就放在主資料夾的最外面,等要使用資料時就會進入bank-additional裡去找到那個資料集。
接下來的專案你必須把它包成class的形式,根據每個步驟來撰寫,你可以把步驟寫的非常細,這樣執行起來,如果產生error,你就可以很清楚的知道運行到哪個步驟出現error。
首先必須import必要的library,讓程式知道你要將你的專案轉成Metaflow可以使用的形式。
from metaflow import FlowSpec, IncludeFile, step
import pandas as pd我在程式一開始就加入pandas的原因是因為,在每個步驟中我都需要使用pandas的功能來進行相關的特徵處理,因為每個步驟都必須重新import的話,對於運行速度會有一定的影響。
接下來我會一次呈現我所有的操作流程,
所有跟Metaflow的相關解釋也都放在上面的script裡,最後還得在最下面的地方再加入
if __name__ == '__main__':
BankMarketing()確定只有從command line運行這個py檔時,才會產生結果。
現在連檢視一下我的流程是否跟我的設定一樣。
python Project_metaflow.py show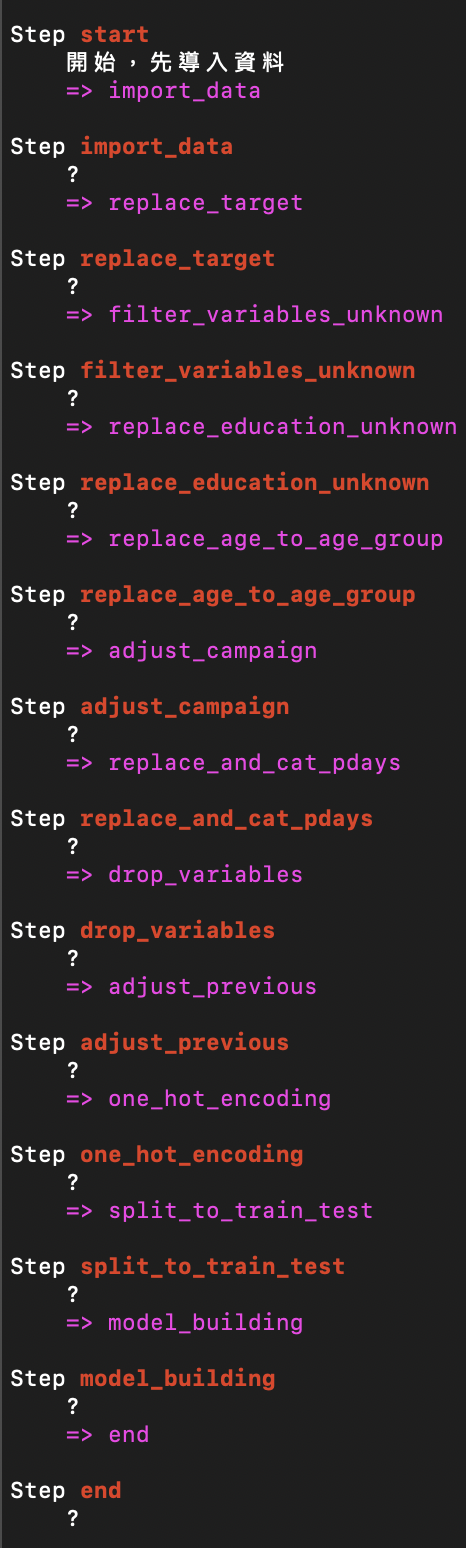
沒錯,跟我的設定一模一樣,中間出現的’?’代表是註釋,你可以加在每個function下,用””” ”””來將這個function描述清楚,就可以很清楚的在上面途中看到這個step是要幹什麼用的了。
那我們就來實際run一次全部的步驟
python Project_metaflow.py run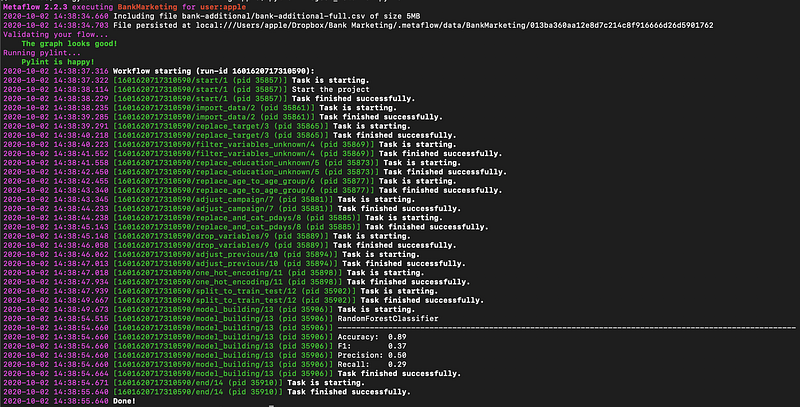
運行成功,可以看到我每個run的開始和結束,還有最後的結果。
這樣就結束啦,以後你碰到任何需要優化的資料科學專案,都可以使用這個非常強的工具提高你的生產力,節省你需要寫非常structured code的時間,讓你可以投入更多時間到分析和認識資料裡,之後我還會有一篇介紹Metaflow的進階功能,和使用限制!
非常感謝你看到最後,我也持續投入對於資料科學流程優化和資料工程的領域,也會一直撰寫文章將這些我所學到的知識分享給你們,讓我們一起努力吧!
同樣的,如果有任何問題,都可以寄信給我,[email protected],歡迎你們的來信!