
如何從頭到尾完成一個資料科學(Data Science)專案

大家好,回來台灣也已經兩個月了,一切都非常好,謝謝你們的關心,也再次希望你們都能身體健康。
今天的文章是如何去完成一個Data Science專案,從認識資料到最後呈現你想要給別人看的成果,中間經過的過程,我也將仔細的跟你介紹,當然這一切都是我個人對資料的理解,可能在完成專案的階段大家都是類似的,在每一個階段你會怎麼完成就是你價值的所在了。
那我會根據以下的流程來完成這篇文章,步驟如下,
- 資料集
- 問題設定與目標
- 衡量指標
- 資料概覽
- 探索性資料分析(EDA)
- 特徵工程(Feature Engineering)
- 特徵選擇(Feature Selection)
- 機器學習
- 指標評估
- 呈現結果
東西比較多,但真正的一個Data Science專案就是如此的複雜!
1. 資料集
這個資料集是在UCI上的銀行行銷資料,詳細的資料集可以參考這裡
2. 問題設定與目標
這個資料集是來自一家葡萄牙銀行的直接行銷活動數據,該直接行銷活動是指透過電話進行行銷銀行的定期存款,因此,有沒有認購定期存款便為我們的預測目標。
3. 衡量指標
在選擇該資料集的時候其並沒有一個指定的衡量指標,所以我根據目標去建立衡量指標,我使用AUC當作在這次專案中嘗試去最優化的衡量指標,再透過False Negative, False Positive的判斷,用客觀的方法使其能在真實的商業情境中應用。
4. 資料概覽
該資料比數總共有41188筆,有21個特徵,但不具備缺失值,在開始進行EDA前,我們必須暸解特徵的名稱與其意義,
Age代表目標的年紀,Job代表目標的工作型態,Martial為婚姻狀態,Education代表教育背景,Default代表是否有違約過,Housing代表是否有房子,Loan代表是否有貸款,Contact代表是用什麼裝置聯絡,Month代表是在什麼月份聯絡,Day_of_week代表是在星期幾,Duration代表是在最後一次接觸使用時間,Campaign代表是在這個campaign代表與客戶聯繫了多少次,Pdays代表與上次聯繫差了多久,Previous這次campaign前與客戶聯繫過幾次,Poutcome之前的campaign是否有成功,Emp.var.rate: 雇用變換率 (以季為單位),Cons.price.idx: 消費者物價指數 (以月為單位),Cons.conf.idx: 消費者信心指數 (以月為單位),Euribor3m: 三個月到期的歐元銀行同業拆放利率 (以日為單位),Nr.employed: 在職員工人數
5. 探索性資料分析(EDA)
透過剛剛對整體資料級的資訊概覽以及特徵的簡單定義,我們可以暸解我們大概有哪些資料,以及資料量有多大,透過上述的資訊可以大概判斷可能完成專案的時間。
接下來,我們便開始進行探索性資料分析(Exploratory Data Analysis),在這個階段中,我們的目的是發現資料中的金子,究竟我們的目標是長什麼樣子,變數之中是不是有什麼關係有可能被挖掘出來,用多變數的組合來看會不會讓我們對目標的構成有更好地理解,總之,EDA就是一個能讓我們發揮資料分析價值的地方,能展現你無窮的想像力,讓你的創造力蓬勃發展,不斷的去看各種圖表以及用你的統計知識去解析變數可能所屬的分布。
目標比例
在這次的專案中,很明顯是個分類的問題,我們便習慣想從目標去暸解目標發生次數佔總發生次數究竟是什麼樣子?畫圖的方法我會使用Plotly來完成,我們可以用圓餅圖來快速檢索目標比例
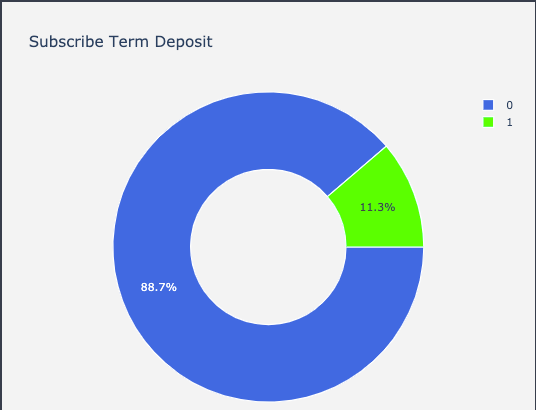
從圖中我們也可以快速知道,透過電話行銷成功讓顧客購買定期存款的比例為11.3%。
接下來我們可以從特徵來做EDA,因為幾乎每個特徵都會被拿來使用EDA去看其潛在的機會,篇幅過長,所以我會從類別型特徵(Categorical Features)和連續型特徵(Continuous Features)各挑一個來做圖,讓各位可以理解要怎麼去觀察特徵和目標變數之間的關係。
類別型特徵: Job (工作型態)
在處理每個變數之前,我們可以有前置的想法去思考說特徵可能會對目標有什麼影響,然後再根據畫圖來驗證或更新我們的想法
所以,在開始畫Job的圖中,可以先嘗試去想想,Job是否會對認購定期存款有差別呢?
在我的認知中,會認購定期存款的人可能表示其為理財相對保守,也極有可能是理財知識不足的人,所以有可能會認購的職業有退休族群,藍領階級,簡單的判斷,那就讓我們開始看看所想的和實際的資料有沒有不一樣。
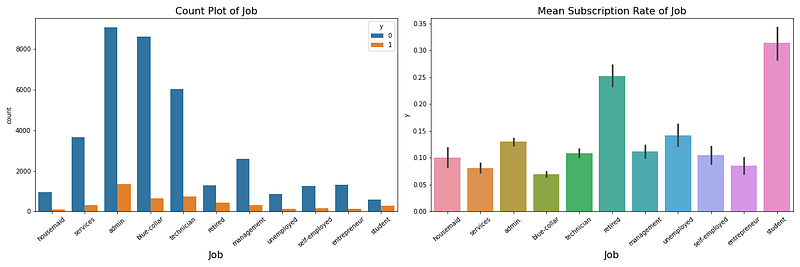
好吧,藍領階級存錢的比例沒有我想像中的高,從這張圖上面獲取的訊息來解讀,我必須修正一下我的初始想法,藍領階級對於定期存款的認購沒有很高的原因可能是來自於比較偏好現金的持有,喜歡手上握有現金的充實感。而退休族群則如預期中的具有很高的比例。
當然,不管最後與你預想的想法有沒有一致,你都應該進行更進一步的確認來證明你的想法,可以是詢問具備該產業知識的同仁,詢問是不是符合你的想法。
連續型特徵: Age (年紀)
那如果換從連續型變數來看對目標變數的影響是如何呢?
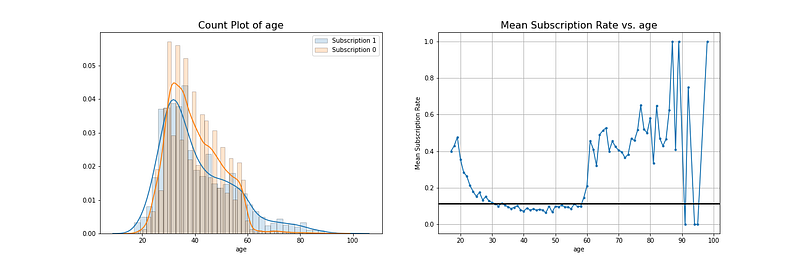
不同的年紀段可能會對未來的規劃有著不同的想法,可以先從左圖得知,行銷對象的年齡主要是在20~60歲之間,大致呈現一個右尾分配,而在中間地帶,也是不認購的比例較高,再看右圖,到30歲前大致都高於總平均,而30到60歲則低於平均,60歲以後則比平均高。
透過在連續型與類別型的變數各舉出一例之後,你可以學習到可以用何種方法來進行分析,找出該變數有可能目標的關鍵原因,這樣日後,當你提出這份專案時,有時候被在意的不是預測結果,而是你在做這個預測結果前發現公司還有哪些在商業面上的突破點。
6. 特徵工程
我個人認為特徵工程是影響你預測結果的最關鍵環節,在最後模型調參(hyperparameter tuning)的時候,實際影響模型的效益不會到非常巨大,但是你在特徵工程環節中所做的一切努力與發現,都有機會在預測結果上獲得非常大的回報。
所以在這特徵工程中,我將舉出我在這次專案中使用的兩個特徵工程方阿,分別是分箱法和二元分類法。
(1) 分箱法
這個方法我覺得直接用例子來說明會比較好,我在’年紀’這個變數上使用了該方法,記得剛剛在做連續型變數時,我真對年紀所做的分析嗎?30~60歲和60歲以後是我可以特別區分開來的特徵,所以我將原本的連續型變數透過分成30歲以前、30~60歲和60歲以後三個類別,這個就是分箱法。
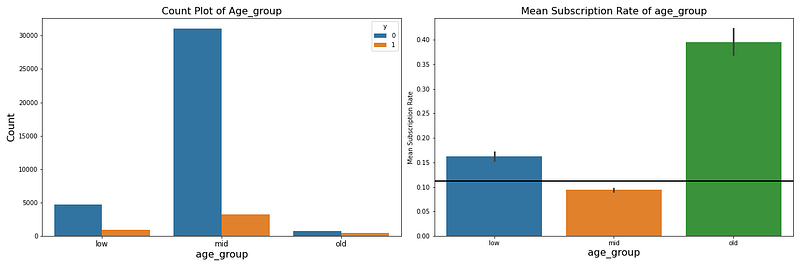
根據年紀的區間去做箱子,可以看到圖表,分箱之後的各區間的平均認購率有相當程度的不同,也許你會覺得並沒有跟原本的數據有很大的不同,但其實60歲以後的老人其實資料量沒有很多,所以有很多是直接1或0,有可能是剛好那一個樣本有認購,這樣就得出可怕的1了!當模型在訓練的時候,當判定到這個年齡,發現在這個年齡的都會認購,模型就會認定只要這個年齡的以後也都會認購,但其實只是因為樣本數不夠大,所以才有如此極端值。
(2) 二元分類法
Pdays代表與上次聯繫差了多久,999代表是之前從未聯繫過,而最高的間隔天數是27天,而在右圖當中,可以看出並不會發現一特定趨勢,間隔天數的增加並不會因此增加或減少認購的比率。
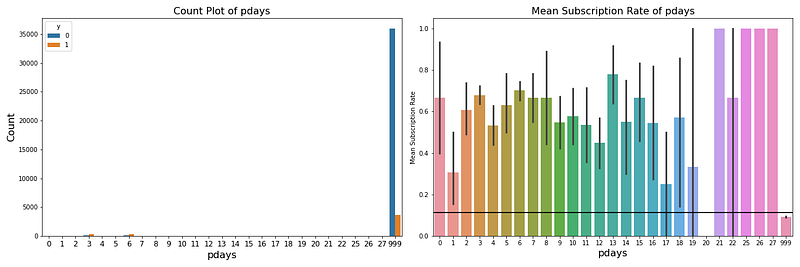
處理這個變數時,我認為在行銷活動中,也許他們打電話的間隔天數不是真的有意義,只會界定是否曾經播打電話給客戶過,所以我將其變成一個二元分類,將尖閣天數分成兩種模式,分成有打過電話(Label: 1),跟沒間隔天數也就是沒打過電話(Label: 2)兩個二元分類。
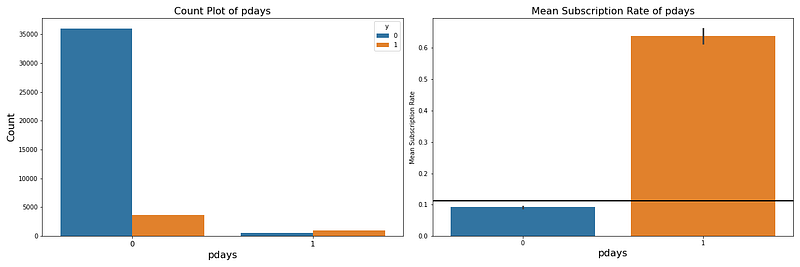
7. 特徵選擇
在來就是特徵選擇的部分,特徵選擇能解決維度爆炸和資料洩漏的問題,之後我會再寫文章分析這兩種不同的問題。
我捨棄了duration(代表是在最後一次接觸使用時間),這個變數是指在完成這次撥打電話總共所使用的時間,這種變數我們不能拿來使用,因為等於是拿未來來預測現在,剩下的我所刪除的變數都可以從我的github上看,我就不全部敘述。
8. 機器學習
經過一系列的分析以及對特徵的處理,我們終於到了建模這一塊,其實在機器學習這塊,你所需要處理的時間不需要太多,有太多的套件已經可以幫你快速跑全部的模型以及調整超參數,你就只需要等待模型跑完就可以看結果了。
儘管有套件可以幫你全部跑完所有的機器學習模型,我認為你還是可以寫一個屬於你的function,讓你在每次建模的時候都可以使用,在這個專案中,因為我想加入plotly當作我建模完進行模型評估的圖,我有參考Dennis Dai的Medium最後針對模型所寫的code,真的寫的很好。
我在這次專案中總共使用了三種模型,分別是Logistic Regression, Random Forest, Gradient Boosting這三種經典的分類模型。
稍微有點長,但是這就是可以屬於自己的函式(Function),在每個專案中都可以使用,我也將展示放Logistic Regression在這個function會有麼效果?
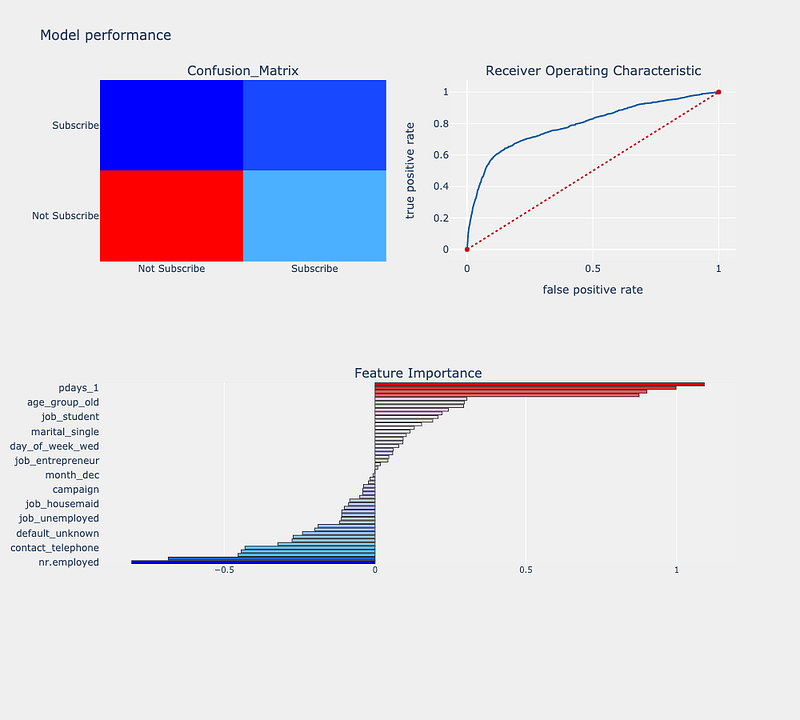
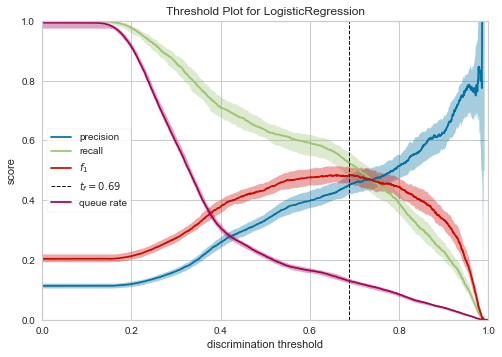
這整套就是運行這個function時會出現的結果,能讓你很快速的檢查模型表現,AUC、ROC、False Positive、False Negative還有特徵重要性。
9. 指標評估
指標評估有不同種方法,你也必須根據題目的問題去設計指標優化的方向,在預測與實際產生錯誤的情況下,會同時有偽陽性(False Positive)和偽陰性(False Negative)的問題,偽陽性是指在預測的結果為正確的情況下,實際的值為錯誤,而偽陰性是指在預測的結果為錯誤的情況下,實際的值為正確。
而在此一專案下,偽陽性是代表我在預期他會訂購定期存款下對其進行電話行銷,而最後從電話中得知該客戶並不會認購我們的產品,而偽陰性則是在打電話前就認為他是不會訂購的,就不會對其進行電話行銷,但其實如果對其進行電話行銷,他是會認購定期存款產品的,所以根據上述情況,我們必須降低偽陰性的結果,因為少一個人認購產品的損失會大大超過客服人員撥打一通電話的成本,故我們要降低閥值,讓越來越多的會被判定為正確,雖然有可能提高偽陽性發生的機會,但是卻可以降低錯失潛在客戶的風險,具體的閥值計算必須透過衡量這兩種結果的成本來得知。
因為在調整閥值時,False Positive和False Negative會有tradeoff的效果,亦指是當嘗試將一方最小化時,勢必會導致另一方增加,我們只能取其最優,或在這個專案下,讓成本最小化,False Positive代表撥電話所花的成本,False Negative為喪失一個客戶的成本,比較下來,False Negative所花費的成本較多,我們應該降低閥值,多撥打電話,才不會錯失可能會購買的潛在客戶。
10. 呈現結果
最後,我是把這一連串的分析和建模都建立成一個PPT,讓我自己能夠好好的檢視在這過程中所做的努力,能在以後需要用來展現做Data Science專案實力時一個很好的產品。你可以根據你自己所喜歡的呈現方式,把你辛苦建立的專案以一個好的方式被建立下來,成為一個能過提升你自己甚至改變職涯的好專案!
非常感謝你/你可以看到最後,好久沒寫文章了,一寫就是這麼長的文章也是蠻爽的,接下來也會有很多的idea等著我去完成,希望我能保持好好寫文章的這種積極度,也謝謝你們長期以來的支持。
再次祝你們都身體健康!
一樣,有任何的問題都可以寄信到我信箱 [email protected]! 如果我沒有回應的話,可以再多寄一次,我怕我漏掉喔,謝謝!





