
GorMachine Learning | Computer Vision | Object Detection
GorMachine Learning | Computer Vision | Object Detection
YOLO — Intuitively and Exhaustively Explained
YOLO--直观而详尽的解释
The genesis of the most widely used object detection models.
最广泛使用的物体检测模型的起源。

Daniel Warfield 使用 MidJourney 制作的 "Look Once"。除非另有说明,所有图片均由作者提供。
In this post we’ll discuss YOLO, the landmark paper that laid the groundwork for modern real-time computer vision. We’ll start with a brief chronology of some relevant concepts, then go through YOLO step by step to build a thorough understanding of how it works.
在本篇文章中,我们将讨论 YOLO,这篇具有里程碑意义的论文为现代实时计算机视觉奠定了基础。首先,我们将简要介绍一些相关概念,然后一步一步地讨论 YOLO,以全面了解其工作原理。
Who is this useful for? Anyone interested in computer vision or cutting-edge AI advancements.
对谁有用?任何对计算机视觉或人工智能前沿技术感兴趣的人。
How advanced is this post? This article should be accessible to technology enthusiasts, and interesting to even the most skilled data scientists.
这篇文章有多先进?这篇文章应该能让技术爱好者读懂,即使是最熟练的数据科学家也会感兴趣。
Pre-requisites: A good working understanding of a standard neural network. Some cursory experience with convolutional networks may also be useful.
先决条件熟练掌握标准神经网络。对卷积网络有一些粗浅的了解也会有所帮助。
A Brief Chronology of Computer Vision Before YOLO
YOLO 之前的计算机视觉简史
The following sections contain useful concepts and technologies to know before getting into YOLO. Feel free to skip ahead if you feel confident.
以下部分包含了在学习 YOLO 之前需要了解的有用概念和技术。如果您有信心,可以跳过这些内容。
Types of Computer Vision Problems
计算机视觉问题的类型
Computer vision is a class of several problem types, all of which relate to somehow enabling computers to “see” things. Typically, computer vision is broken up into the following:
计算机视觉是由若干问题类型组成的一个类别,所有这些问题类型都与以某种方式使计算机能够 "看到 "事物有关。通常,计算机视觉可分为以下几类:
- Image Classification: the task of trying to classify an entire image. For instance, one might classify an entire image as containing a cat or a dog.
图像分类:尝试对整幅图像进行分类的任务。例如,可以将整幅图像分为猫和狗。 - Object Detection: the task of finding instances of an object within an image, and where those instances are.
物体检测:在图像中查找物体的实例以及这些实例的位置。 - Image Segmentation: the task of identifying the individual pixels within an image that correspond to a specific object. So, for instance, identify all the pixels within an image that correspond to dogs.
图像分割:识别图像中与特定对象相对应的单个像素的任务。例如,识别图像中与狗相对应的所有像素。

计算机视觉的三大子问题。这在某种程度上是一种简化;实际上,在这些子问题中还有一些子问题,但这不在本文的讨论范围之内。本文的主题 Yolo 是一种突破性的物体检测模型。资料来源
Convolutional Neural Networks
卷积神经网络
YOLO employs a form of model called a “Convolutional Neural Network”. A convolutional neural network (CNN for short) is a style of neural network that applies a filter, called a “Kernel” over an image.
YOLO 采用了一种名为 "卷积神经网络 "的模型。卷积神经网络(简称 CNN)是一种在图像上应用滤波器(称为 "核")的神经网络。

卷积网络处理图像的概念图。摘自我关于 CNN 的文章
These “kernels” are simply a block of numbers. If the numbers in the kernel change, the result of the filtering process changes.
这些 "内核 "只是一个数字块。如果内核中的数字发生变化,过滤过程的结果也会随之改变。
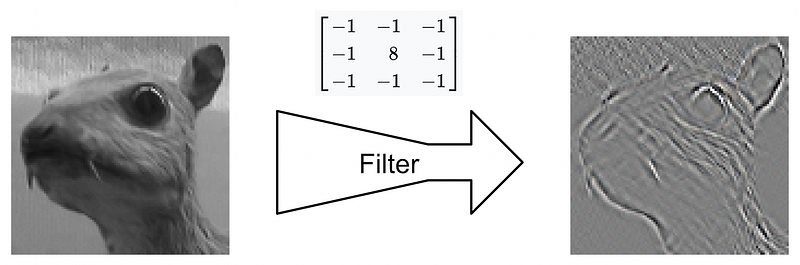
应用于图像的内核就像一个过滤器,可以修改图像。CNN 学会改变内核中的值,以改进正在训练的任务。摘自我关于 CNN 的文章。资料来源
The actual filtering process consists of the kernel being swept through various parts of an image. At a given location, the kernels values are multiplied to the values in the image, and then added together to result in a new output. This process of “sweeping” is how CNNs get their name. In math, sweeping in this way is called “convolving”.
实际的滤波过程包括将内核扫过图像的各个部分。在指定位置,内核值与图像中的值相乘,然后相加得出新的输出结果。这种 "扫描 "过程就是 CNN 名称的由来。在数学中,这种扫频方式被称为 "卷积"。
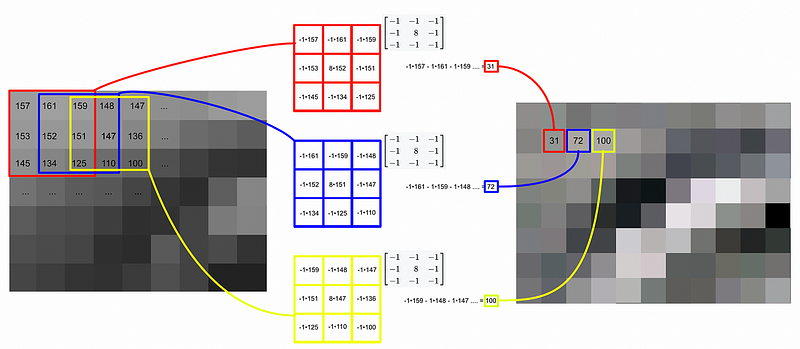
将内核卷积到图像上的过程。摘自我关于 CNN 的文章。
For computer vision tasks, CNNs typically apply convolution and information compression over successive steps to break down an image into some dense and meaningful representation. This representation is then used by a classic neural network to achieve some final task.
在计算机视觉任务中,CNN 通常通过连续的步骤进行卷积和信息压缩,将图像分解为一些密集而有意义的表示。然后,传统的神经网络利用这种表征来完成最终任务。
The most common way a CNN compresses an image down into a meaningful representation is by employing “max pooling”. Basically, you break an image up into N by N squares, then out of those squares you only preserve the highest value.
最常见的 CNN 压缩图像的方法是采用 "最大池化"。从根本上说,就是将图像分割成 N 乘 N 的方块,然后在这些方块中只保留最高值。
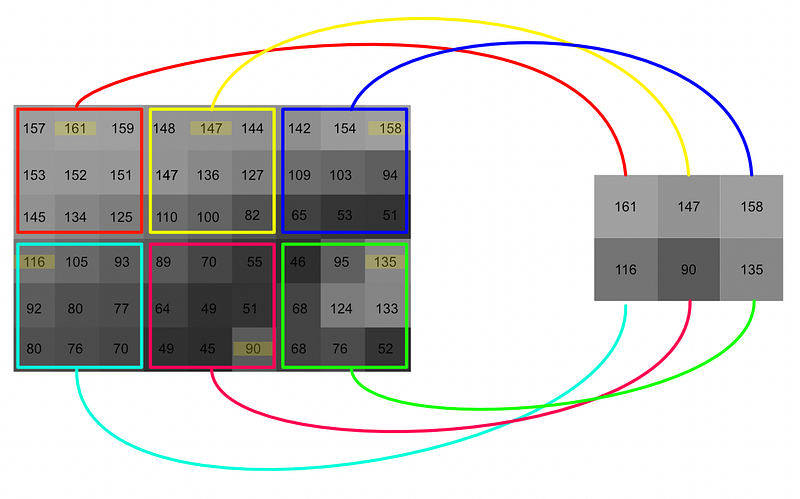
最大集合的概念图,摘自我关于 CNN 的文章。
After a model has filtered (convolved) and down sampled (max pool) an image over numerous iterations, the result is a compressed representation that contains key information about the image. This is often passed through a dense network (a classic neural network) to produce the final output.
一个模型经过多次迭代,对图像进行过滤(卷积)和向下采样(最大池)后,得到一个包含图像关键信息的压缩表示。这通常会通过一个密集网络(典型的神经网络)产生最终输出。
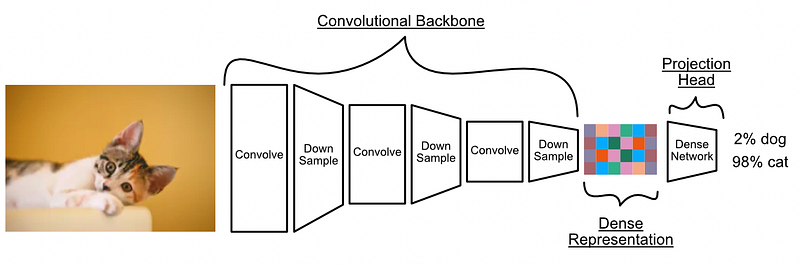
卷积网络如何实际解决问题的示例。该模型通过卷积和向下采样(最大池化)对图像进行处理,直到生成抽象而密集的图像表征。然后通过神经网络产生最终输出。这种模型的卷积部分通常被称为 "主干",而末端的神经网络通常被称为 "头部"。摘自我关于 CNN 的文章。
If you want to learn more about convolutional networks, I wrote a whole article on the topic:
如果你想了解更多关于卷积网络的信息,我写过一篇关于这个主题的文章:
If you’re interested in the structure of CNNs, and how backbones and heads can be used in advanced training processes, you might be interested in this article:
如果您对 CNN 的结构以及如何在高级训练过程中使用骨干和头部感兴趣,您可能会对这篇文章感兴趣:
Early Object Detection with Sliding Window
利用滑动窗口进行早期物体检测
Before approaches like YOLO, “sliding window” was the go-to strategy in object detection. Recall that the goal of object detection is to detect instances of some object within an image.
在使用 YOLO 等方法之前,"滑动窗口 "是物体检测的常用策略。回顾一下,物体检测的目标是检测图像中某些物体的实例。
计算机视觉的三大子问题。
In sliding window, the idea is to sweep a window across an image and classify the content of the window with a classification model.
滑动窗口的原理是在图像上扫过一个窗口,然后用分类模型对窗口的内容进行分类。

概念演示将不同窗口分类为是否包含一只狗的过程。我们向一个分类模型展示图像中的几个 "窗口",该模型经过训练,可以识别图像中是否包含一只狗。我们可以记录下模型认为包含狗的窗口,从而创建一个可能包含狗的窗口系列。
Once classifications have been calculated, a final bounding box can be defined by simply combining all the classified windows.
计算出分类结果后,只需将所有已分类的窗口组合在一起,即可定义最终的边界框。

通过滑动窗口进行多次分类后,就可以计算出整体的边界框。在本例中,我们只需找到包含模型预测有狗的所有窗口的边界框。
There are a few tricks one can use to get this process working better. However, the sliding window strategy of object detection still suffers from two key problems:
有一些技巧可以让这一过程更好地运行。然而,物体检测的滑动窗口策略仍然存在两个关键问题:
- It’s very computationally intensive (you may have to run a model tens, hundreds, or even thousands of times per image)
计算量非常大(每幅图像可能需要运行数十、数百甚至数千次模型) - The bounding boxes are inaccurate
边界框不准确
Selective Search and R-CNN
选择性搜索和 R-CNN
Instead of arbitrarily sweeping some window through an image, the idea of selective search is to find better windows based on the content of the image itself. In selective search, first small regions within an image that contain a lot of similar pixels are found, then similar neighboring regions are merged together over successive iterations to build larger regions. These large regions can be used to recommend bounding boxes.
选择性搜索的理念是根据图像本身的内容找到更好的窗口,而不是任意地在图像中扫过某个窗口。在选择性搜索中,首先要在图像中找到包含大量相似像素的小区域,然后通过连续迭代将相似的邻近区域合并在一起,以建立更大的区域。这些大区域可用于推荐边界框。

选择性搜索,在图像中创建精细区域,然后反复组合这些区域,构建更大的区域提案。资料来源
With selective search, instead of finding random windows based on sweeping, bounding boxes are suggested by the image itself. Several approaches have used selective search to drastically improve object detection.
在选择性搜索中,我们不是根据扫描结果随机寻找窗口,而是由图像本身提出边界框。有几种方法利用选择性搜索大大改进了物体检测。
One of the most famous models to use this trick is R-CNN, which trained a tailored convolutional network based on proposed regions in order to enable high quality object detection.
使用这种技巧的最有名的模型之一是 R-CNN,它根据提议的区域训练了一个定制的卷积网络,以实现高质量的物体检测。
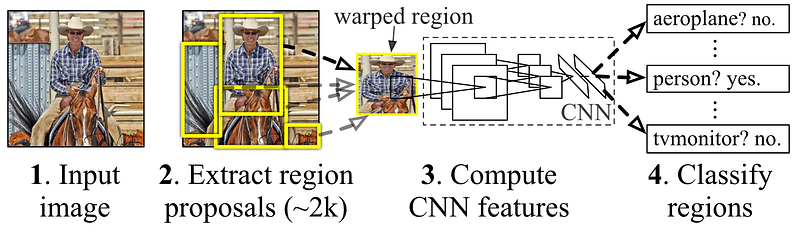
R-CNN 论文中的示意图,该论文使用选择性搜索提出区域,并使用定制的 CNN 根据这些区域进行预测。资料来源
R-CNN was a mainstay in computer vision for a while, and spawned many derivative ideas. However, it’s still very computationally intensive.
R-CNN 一度是计算机视觉领域的主流,并催生了许多衍生想法。不过,它的计算量仍然非常大。
YOLO blew the paradigm of R-CNN out of the water, and inspired a fundamentally new way of thinking about image processing that remains relevant to this day. Let’s get into it.
YOLO 颠覆了 R-CNN 的模式,从根本上启发了图像处理的新思路,至今仍具有现实意义。让我们进入正题。
YOLO: You Only Look Once
YOLO:你只能看一次
The idea of YOLO is to do everything in one pass of a CNN, hence why it’s called “You Only Look Once”. That means a single CNN, in a single pass, has to somewhow find numerous different instances of objects, correctly classify them, and draw bounding boxes around them.
YOLO 的理念是在 CNN 的一次处理中完成所有工作,因此被称为 "You Only Look Once"。这意味着,一个 CNN 在一次处理过程中,必须找到大量不同的对象实例,对其进行正确分类,并在其周围绘制边框。

YOLO 在行动中的一个例子,摘自 YOLO 论文。
To achieve this, the authors of YOLO broke down the task of object detection into two sub-tasks, and built a model to do those sub-tasks simultaneously.
为此,YOLO 的作者将物体检测任务分解为两个子任务,并建立了一个模型来同时完成这些子任务。
Subtask 1) Regionalized Classification
子任务 1)区域化分类
YOLO breaks images up into some arbitrary number of regions, and then classifies all those regions at the same time. It does this by modifying the output structure of a traditional CNN.
YOLO 将图像分解成任意数量的区域,然后同时对所有这些区域进行分类。它通过修改传统 CNN 的输出结构来实现这一目的。
Normally a CNN compresses an image into a dense 2D representation, then a process called flattening is applied to that representation to turn it into a single vector, which can in turn be fed into a dense network to generate a classification.
通常,CNN 会将图像压缩为密集的二维表示,然后对该表示进行称为扁平化的处理,将其转化为单一向量,再将其输入密集网络以生成分类。

传统 CNN 如何预测图像中是否有狗与图像中是否没有狗的概念图。卷积和最大池化可创建图像的高密度表示,然后将其扁平化并通过神经网络。
Unlike this traditional approach, YOLO predicts classes for sub-regions of the image rather than the entire image.
与这种传统方法不同的是,YOLO 预测的是图像的子区域而不是整个图像的类别。
In YOLO, the convolution output is flattened like normal, but then the output is converted back into a 2D representation of shape S x S x C where S represents how finely the image is subdivided into regions and C represents the number of classes being predicted. Both S and C are configurable parameters which can be used to apply YOLO to different tasks.
在 YOLO 中,卷积输出会像正常情况一样被扁平化,但随后输出又会被转换成 S x S x C 的二维表示形式,其中 S 表示图像被细分为多个区域的程度,C 表示被预测类别的数量。S 和 C 都是可配置的参数,可用于将 YOLO 应用于不同的任务。

YOLO 预测图像子区域内类别的概念图。如果有两个类别(C=2,"狗 "和 "无物体"),图像在长度和宽度上被分成 7 份(S=7),那么 YOLO 的类别预测输出就会像上图一样,在每个网格空间内预测出所有类别。实际上,输出不一定要有这样的输出形状,只需要每个输出都有一个点就可以了。因此,该模型的最终输出将是一个长度为 S x S x C 的向量。
Provided this model is trained correctly (we’ll cover that later), a model with this structure could classify numerous regions within an image in a single pass.
如果这个模型训练得当(我们稍后会介绍),具有这种结构的模型可以一次性对图像中的许多区域进行分类。
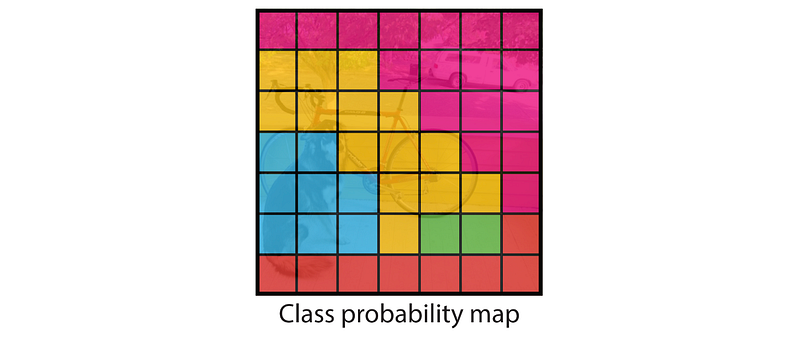
YOLO 预测图像子区域内各种类别的示例。摘自 YOLO 论文。
Not only is this more efficient than R-CNN (due to only one inference generating classes for an entire image), it’s also more performant. When R-CNN makes a prediction it only has access to the region proposed by selective search, which can make R-CNN bad at discerning irrelevant background objects.
这不仅比 R-CNN 更有效(因为只需一次推理就能为整幅图像生成类),而且性能也更高。当 R-CNN 进行预测时,它只能访问选择性搜索提出的区域,这可能会使 R-CNN 无法辨别不相关的背景对象。

一个糟糕的背景检测示例。由于 R-CNN 无法对整个图像进行推理(它只能得到图像的一小部分区域),因此它可能会随机创建一些在图像上下文中没有意义的边界框。资料来源
CNNs have something called a “perceptive field”, which means that CNNs by themselves suffer a similar issue. A particular spot within a CNN can only see a small subset of the image. In theory this might cause YOLO to also make poor choices about predictions.
CNN 有一种叫做 "感知场 "的东西,这意味着 CNN 本身也存在类似的问题。CNN 中的一个特定点只能看到图像的一小部分。理论上,这可能会导致 YOLO 也做出错误的预测。
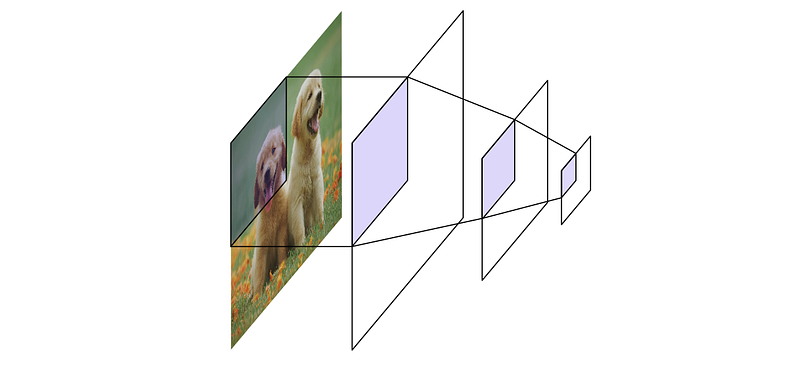
由于 CNN 的抖动方式,最终的密集表示包含特定区域的信息。这一概念通常被称为 "感知场",因为密集表示的左上方只能 "感知"(包含基于输入图像左上方的信息)。
However, YOLO passes the dense 2D representation through a fully connected neural network; allowing information with each perceptive field to interact with one another before making the final prediction.
然而,YOLO 通过一个完全连接的神经网络传递密集的二维表征;允许每个感知领域的信息在做出最终预测之前相互影响。
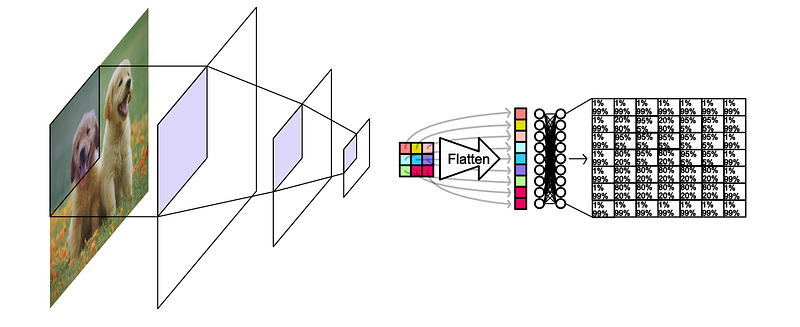
虽然 CNN 的密集表示是针对特定区域的,但由于结果是通过密集网络得出的,因此任何特定区域的最终输出都是基于图像中所有区域的信息。
This allows YOLO to reason about the entire image before making the final prediction, a key difference that makes YOLO more robust than R-CNN in terms of contextual awareness.
这使得 YOLO 能够在做出最终预测之前对整个图像进行推理,而这正是 YOLO 在上下文感知方面比 R-CNN 更稳健的关键所在。
Subtask 2) Bounding Box Prediction
子任务 2)边框预测
In theory we could use the predicted regions from the previous step to draw bounding boxes, but the results wouldn’t be very good. Also, what if there were two dogs next to each other? It would be impossible to distinguish two dogs from one wide dog, because both would just look like a bunch of squares labeled dog.
理论上,我们可以使用上一步的预测区域来绘制边界框,但效果不会很好。另外,如果有两只狗挨在一起呢?我们不可能将两只狗和一只宽大的狗区分开来,因为两只狗看起来就像一堆贴着狗标签的方块。
想象一下使用这些预测来绘制边界框的情景。虽然这样做总比什么都不做要好,但所有的边界框都会比它们所代表的物体大得多,而且无法捕捉到彼此相邻的同一物体的单个实例。摘自 YOLO 论文。
To alleviate these issues YOLO predicts bounding boxes as well as class predictions.
为了缓解这些问题,YOLO 在预测类别的同时也预测边界框。
YOLO assigns a “responsibility” to each square in the S x S grid. Basically, if a square contains the center of an object, then that square is responsible for creating the bounding box for that object.
YOLO 为 S x S 网格中的每个方格分配一个 "责任"。基本上,如果一个方格包含一个对象的中心点,那么该方格就负责为该对象创建边界框。
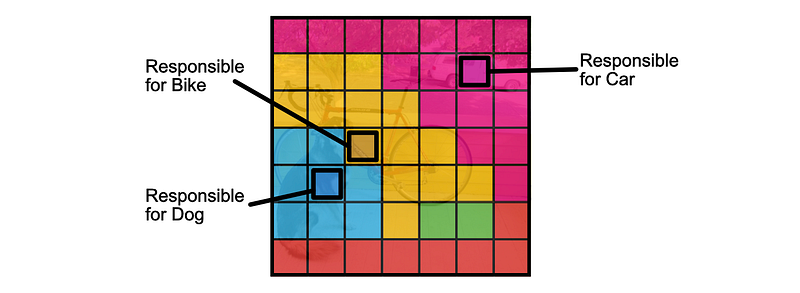
YOLO 中 "责任 "的概念图。以狗为中心的 SxS 正方形对狗 "负责",同样也对自行车和汽车 "负责"。摘自 YOLO 论文。
The responsible square for a given object is in charge of drawing the bounding box for that object.
指定对象的责任方格负责绘制该对象的边界框。
On top of the S x S x C tensor for class prediction (which we covered in the previous section), YOLO also predicts an S x S x B x 5 tensor for bounding box prediction. In this tensor S represents the divisions of the image (as before), and B represents the number of bounding boxes each S x S square can create. The 5 represents:
除了用于类别预测的 S x S x C 张量(我们在上一节中已经介绍过),YOLO 还会预测一个用于边界框预测的 S x S x B x 5 张量。在这个张量中,S 代表图像的分区(如前所述),B 代表每个 S x S 正方形可以创建的边框数量。5 代表
- Bounding box width
边界框宽度 - Bounding box height
边界框高度 - Bounding box horizontal offset
边界框水平偏移 - Bounding box vertical offset
边界框垂直偏移 - Bounding box confidence
边界框置信度
So, in essence, YOLO creates a bunch of bounding boxes for each square in the S x S grid. Specifically, YOLO creates B bounding boxes per square.
因此,从本质上讲,YOLO 为 S x S 网格中的每个方格创建了一堆边框。具体来说,YOLO 会为每个方格创建 B 个边界框。

YOLO 预测的所有边界框,其中边界框的厚度与边界框的 "置信度 "输出相对应。根据 "B "参数的指定,YOLO 可以预测每个正方形中的无数个边界框。摘自 YOLO 论文。
If we only look at bounding boxes with high confidence scores, and the classes of the grid square those bounding boxes correspond to, we get the final output of YOLO.
如果我们只查看高置信度的边界框,以及这些边界框所对应的网格方格的类别,我们就能得到 YOLO 的最终输出结果。
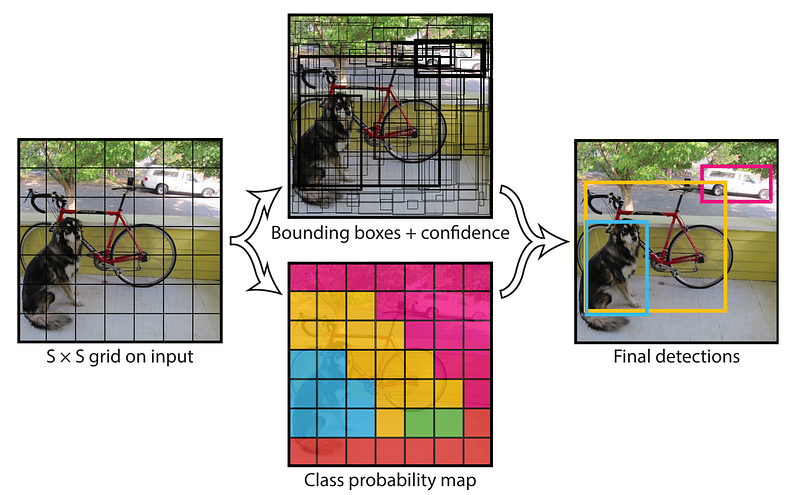
我们可以使用边界框预测和区域类别概率来创建最终的边界框。
We’ll re-visit the idea of “confidence” when we explore how YOLO is trained. For now, let's take a step back and look at YOLO from a higher level.
当我们探讨如何训练 YOLO 时,我们将再次讨论 "信心 "这一概念。现在,让我们退一步,从更高的层面来审视 YOLO。
The Architecture of YOLO
YOLO 的建筑
The cool thing about YOLO is that it does object detection in “one look”. In one pass of the model both subtasks of class prediction and bounding box prediction are done simultaneously.
YOLO 最酷的地方在于它可以 "一眼 "完成物体检测。在模型的一次传递中,类预测和边界框预测这两项子任务同时完成。
We unify the separate components of object detection into a single neural network. — The YOLO paper
我们将物体检测的各个组成部分统一到一个神经网络中。- YOLO 论文
Essentially, this is done by YOLO outputting the S x S x C class predictions and the S x S x B x 5 bounding box predictions all in one shot, meaning YOLO outputs S x S x (B x 5 + C) things.
从本质上讲,这是通过 YOLO 一次输出 S x S x C 类预测和 S x S x B x 5 边框预测来实现的,也就是说,YOLO 输出的是 S x S x (B x 5 + C) 事物。
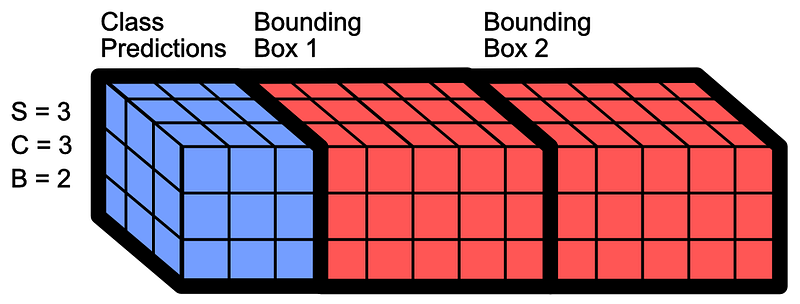
如果 S=3(图像的分割)、C=3(类别的数量,例如 "狗"、"猫 "和 "背景")和 B=2(每个分割内有多少个 "x"、"y"、"宽"、"高 "和 "置信度 "的边界框),就会输出 YOLOs 的示例。请记住,这种数据形状主要用于演示目的。YOLO 输出的形状可以是三维的(S、S、B*5+C),也可以是长度为 S*S*(B*5+C) 的向量。无论哪种方法,其功能都是相同的,归根结底只是一个实施细节问题。
Now that we understand the subtasks YOLO solves, and how it formats an output to solve those problems, we can start making sense of the actual architecture of YOLO.
既然我们已经了解了 YOLO 要解决的子任务,以及它如何格式化输出以解决这些问题,我们就可以开始了解 YOLO 的实际架构了。
As we’ve discussed, YOLO is a convolutional network that distills an image into a dense representation, then uses a fully connected network to construct the output.
正如我们已经讨论过的,YOLO 是一种卷积网络,它将图像提炼为密集表示,然后使用全连接网络构建输出。
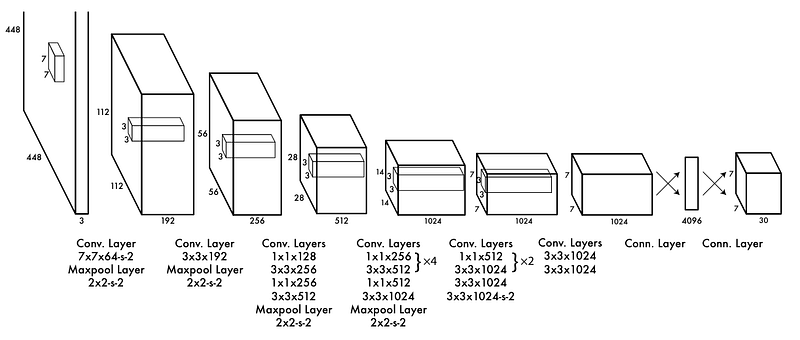
YOLO 的架构图。资料来源
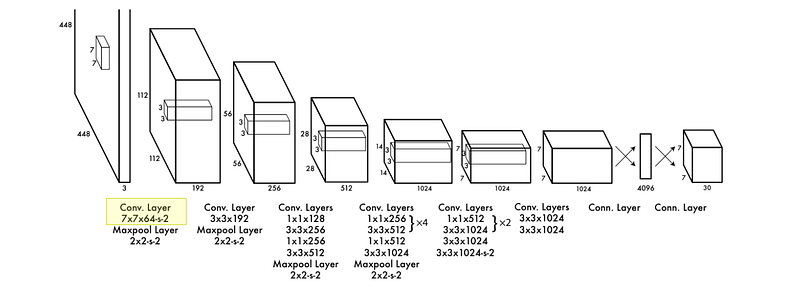
In reality, the diagram above is somewhat of a simplification of the actual architecture, which is written out below the diagram. Let’s go through a few layers of YOLO to build a more thorough understanding.
实际上,上图在一定程度上简化了实际架构,实际架构写在下图中。让我们通过 YOLO 的几个层次来建立更透彻的理解。
First of all, the input image is an RGB image, meaning it has some width and height and three color channels. It looks like YOLO is designed to receive a square RGB image of width 448 and height 448. If you want to do YOLO on a smaller or larger image, you can just resize the image into 448 x 448.
首先,输入图像是 RGB 图像,这意味着它有一定的宽度和高度以及三个颜色通道。看起来,YOLO 是为接收宽度为 448、高度为 448 的正方形 RGB 图像而设计的。如果你想在更小或更大的图像上运行 YOLO,只需调整图像大小为 448 x 448 即可。
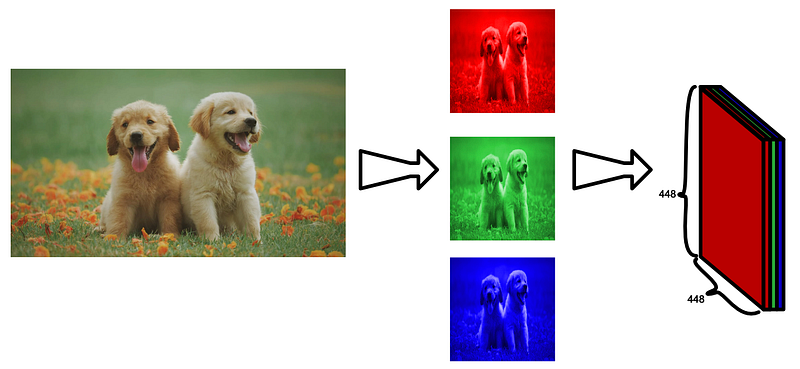
将图像转化为 YOLO 输入的概念图。图像被压缩成 448x448,然后每个颜色通道代表输入的某个深度。
The first layer of YOLO is listed as 7x7x64-s-2 , which means we have a convolutional layer with 64 kernels of size 7x7 that have a stride of 2.
YOLO 的第一层被列为 7x7x64-s-2,这意味着我们的卷积层有 64 个大小为 7x7 的内核,跨距为 2。
When a convolutional model has multiple kernels, each of those kernels consists of different learned parameters, and they work together to make the final output.
当一个卷积模型有多个内核时,每个内核都由不同的学习参数组成,它们共同完成最终输出。

多个内核共同构建输出的概念图。摘自我关于 CNN 的文章
In this particular layer, the kernels have a width and a height of 7, and instead of moving by one space at a time, it moves by two.
在这个特殊的图层中,内核的宽度和高度都是 7,而且不是每次移动一个空格,而是移动两个空格。

长度为 1(左)、2(中)和 3(右)的步长概念图,所有步长均适用于大小为 2 的内核。摘自我关于卷积网络的文章。
So, the first convolutional layer consists of 64 kernels of size 7x7 and a stride of 2.
因此,第一个卷积层由 64 个核组成,大小为 7x7,步长为 2。
我们刚刚讨论过的 "YOLO "的第一层含义。资料来源
After the first convolutional layer, the data is passed through a max pool of size 2x2 with a stride of 2.
在第一个卷积层之后,数据会通过一个大小为 2x2、步长为 2 的最大池。
回想一下,最大池化处理会占用一些数据窗口,并只保留最大值,这实际上就是降采样。在我们讨论的图层中,这些窗口是 2x2,而不是图中所示的 3x3。摘自我关于 CNN 的文章。
The kernel of stride 2 reduces the dimension of the input by 1/2, the max pool of stride 2 reduces the dimension of the input by another 1/2, and the 64 kernels converts our 3 color channels to 64 kernel channels. This results in a tensor of shape 112 x 112 x 64 .
步长 2 的内核将输入的维度减少了 1/2 ,步长 2 的最大池又将输入的维度减少了 1/2 ,而 64 个内核则将我们的 3 个颜色通道转换为 64 个内核通道。这样就得到了一个形状为 112 x 112 x 64 的张量。
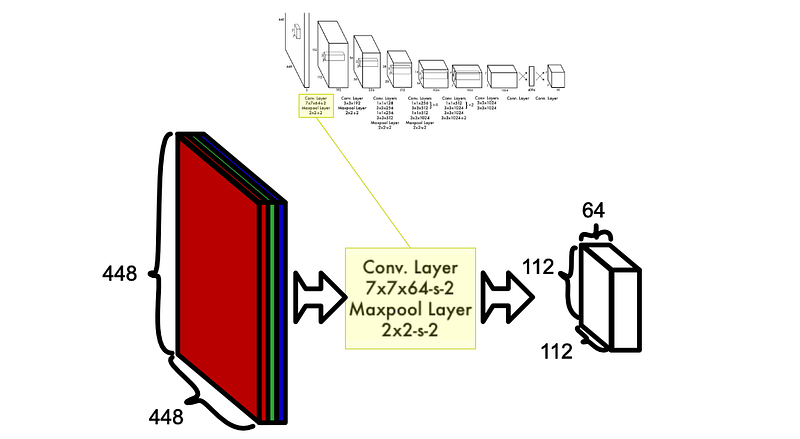
YOLO 的前两层作用于输入。卷积和最大池化都将特殊维度减少了一半,应用 64 个核将数据深度变为 64 dpeth。
The YOLO architecture has many layers, many of which behave fundamentally similarly. I won’t bore you with an exploration of every single layer, but there are a few design details which are worth highlighting.
YOLO 架构有许多层,其中许多层的行为基本相似。我就不一一介绍了,但有几个设计细节值得强调。
The idea of a 1 x 1 convolution is interesting, and kind of flies in the face of a normal intuition around convolution. If a kernel is only looking at one pixel, what’s the point?
1 x 1 卷积的想法很有趣,而且有点违背卷积的一般直觉。如果内核只关注一个像素,那还有什么意义呢?
Recall that a convolution applies a kernel not only to some n x n region of the image, but also all input channels.
回想一下,卷积不仅将核应用于图像的某个 n x n 区域,而且还应用于所有输入通道。
虽然卷积通常被画成一个在输入上传播的二维矩阵,但实际上内核是三维的,适用于输入的所有通道。我在关于 CNN 的文章中详细介绍了核的维度。这段动画展示了应用于三个输入通道的 3x3 内核。在这种情况下,1x1 内核是一个应用于所有输入通道的向量。
So a 1 x 1 convolution is essentially a filter that operates over only the channel dimension, and not the spatial dimension.
因此,1 x 1 卷积实质上是一种只在通道维度而非空间维度上运行的滤波器。
You may also wonder “why did the researchers who made YOLO settle on all of these numbers? Why 192 filters vs 200 here? Why a stride of 2 here and a stride of 1 there?”
您可能还会问:"为什么制作《YOLO》的研究人员会确定所有这些数字?为什么这里是 192 个过滤器,而这里是 200 个?为什么这里的跨度是 2,而那里的跨度是 1?
回顾一下 YOLO 的结构图。一个很自然的问题可能是:"为什么研究人员会得出这些数字?资料来源
The honest truth is that researchers usually use a combination of what others have done combined with concepts that seem cool to them. YOLO could probably have some of its network details changed without a major impact on performance. If you choose to build a model like this yourself, you often start with a baseline model and play around with different parameters to see if you can get something better.
老实说,研究人员通常会把别人做过的东西和自己觉得很酷的概念结合起来使用。YOLO 也许可以改变一些网络细节,而不会对性能产生重大影响。如果你选择自己建立一个这样的模型,通常会从一个基线模型开始,然后尝试使用不同的参数,看看是否能得到更好的结果。
One design constraint that YOLO does inherit from many CNNs is the concept of an information bottleneck. Throughout successive layers, the total amount of information is reduced. This is a pervasive concept in machine learning; that by passing data through a bottleneck you force a model to trim away irrelevant information and distill an input into its essence.
YOLO 从许多 CNN 中继承的一个设计限制因素是信息瓶颈的概念。在连续的层中,信息总量会减少。这是机器学习中的一个普遍概念;通过瓶颈传递数据,可以迫使模型剔除无关信息,并将输入信息提炼为精华。
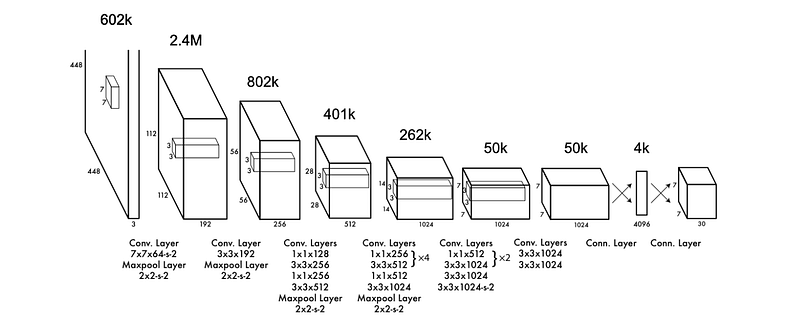
YOLO 每一层用于描述图像的数字总量。可以看出,YOLO 最初允许以更大的形式表示图像,但连续的层数会迫使同一图像以越来越小的形式表示。这就迫使卷积层协同工作,将图像提炼为其本质。
YOLO very heavily reduces the spatial dimension, while expanding the channel dimension, essentially implying that YOLO heavily breaks down a given region of an image, but increases the number of representations for that region.
YOLO 大幅降低了空间维度,同时扩大了通道维度,这意味着 YOLO 大幅分解了图像的特定区域,但增加了该区域的表示数。
Training YOLO
培训 YOLO
We’ve covered the nature of the output, as well as the structure of the model. Now let’s explore how the model is trained.
我们已经介绍了输出的性质以及模型的结构。现在,让我们来探讨如何训练模型。

加入 IAEE
YOLO is trained, like many AI models, via “back-propagation”. Back propagation generally consists of:
与许多人工智能模型一样,YOLO 也是通过 "反向传播 "进行训练的。反向传播一般包括
- Calculating how wrong the prediction is
计算预测的错误程度 - Calculating the influence each parameter had on the current output
计算每个参数对当前输出的影响 - Using the wrongness of the model, with the influence of the parameters, to update the parameters.
利用模型的错误性以及参数的影响来更新参数。
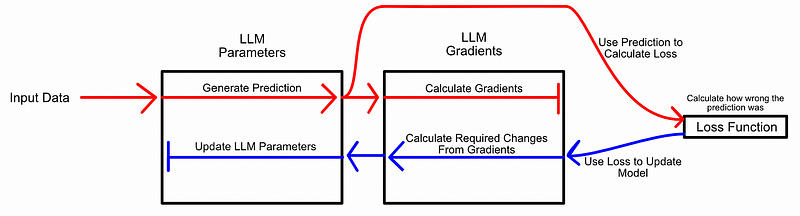
反向传播概念图。在该图中,"梯度 "代表模型参数对输出结果的影响程度,而 "损失函数 "则代表模型的错误程度以及错误的方式。这个特定的图表基于 LLM(大型语言模型),但这个概念对于 YOLO 等计算机视觉模型来说是完全一样的。摘自我关于 LoRA 的文章
Going over back propagation in depth is out of scope for this article, and also isn’t necessary. Many machine learning engineers and researchers rely on frameworks like PyTorch to do a lot of this stuff for them. The only critical thing we need to understand for our purposes is something called a “Loss Function”.
深入讨论反向传播超出了本文的范围,而且也没有必要。许多机器学习工程师和研究人员都依赖 PyTorch 等框架来完成这些工作。就我们的目的而言,我们唯一需要了解的关键东西是一种叫做 "损失函数 "的东西。
The loss function governs how “wrongness” in a model is defined, which governs the entire training process. The whole point of training is to optimize the model to get better results from the loss function.
损失函数决定了如何定义模型中的 "错误",也决定了整个训练过程。训练的全部意义在于优化模型,以便从损失函数中获得更好的结果。
Because YOLO has such a complex output, the loss function is pretty complicated.
由于 YOLO 的输出非常复杂,因此损失函数也相当复杂。
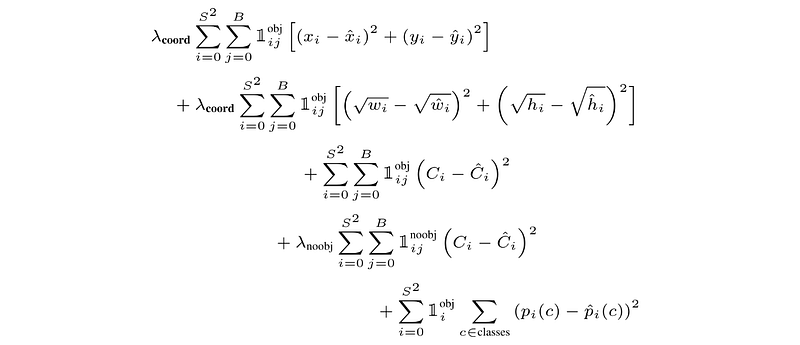
YOLOs 损失函数,资料来源
I know the math might seem a bit daunting, but we’ll take it step by step. As we explore the loss function, keep in mind that we’re training the model based on an annotated dataset. That means we know all classes and bounding boxes ahead of time. Our loss function calculates our models predictions versus these known values, which means reducing the loss from the loss function means our model is better.
我知道这些数学运算看起来有点令人生畏,但我们会一步一步来。在我们探索损失函数的过程中,请记住,我们是在注释数据集的基础上训练模型的。这意味着我们提前知道了所有类别和边界框。我们的损失函数计算的是模型相对于这些已知值的预测结果,这意味着减少损失函数的损失意味着我们的模型更好。

来自 Pascal VOC 数据集的示例,YOLO 在该数据集上接受了训练。数据来源
The loss can be conceptualized as a product of two things, how bad the model is at predicting classes, and how bad the model is at predicting bounding boxes.
损失可以概念化为两方面的乘积,一是模型预测类别的能力有多差,二是模型预测边界框的能力有多差。
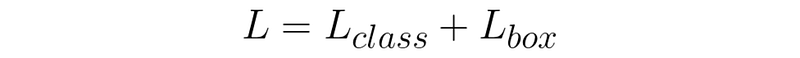
YOLO 的总损失由两部分组成:类别预测损失和边界框预测损失。
Let’s unpack each of these losses, one at a time.
让我们逐一解读这些损失。
Class Loss
班级损失
The expression for class loss is the following:
类损失的表达式如下
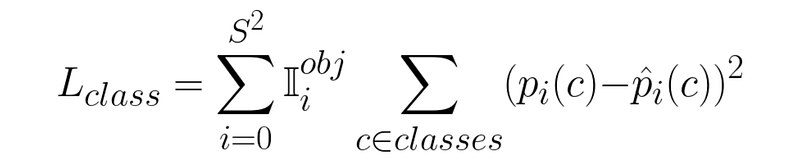
Working through this loss function element by element. Σ (capital sigma) means addition. The first Σ means we’ll be iterating through all of the S x S grids in the image and adding up a value from each grid square.
逐个元素计算这个损失函数。Σ(大写西格玛)表示加法。第一个 Σ 表示我们将遍历图像中所有的 S x S 网格,并将每个网格方格中的数值相加。
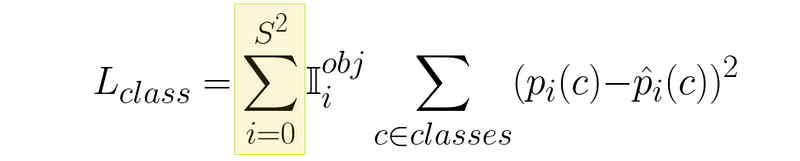
回顾一下,YOLO 将图像划分为 S x S 的网格。类损失的计算方法是将每个方格的损失相加。摘自 YOLO 论文。
Not every square has an object in it though. YOLO only learns class predictions from squares that have an object inside of them.
但并不是每个方格中都有一个对象。YOLO 只从有物体的方格中学习类别预测。
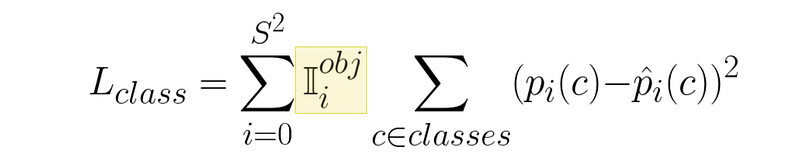
So, together, you can think of this expression as summing the loss from all the squares that have an object inside of them.
因此,我们可以把这个表达式看作是将所有包含一个物体的正方形的损失相加。
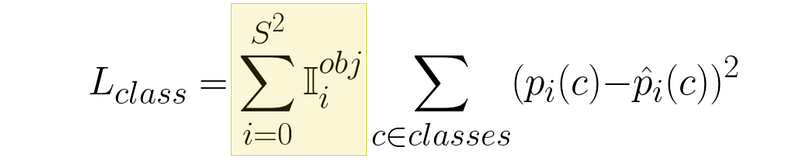
该表达式将所有包含一个类的方格的类损失相加。
the loss from all the squares that have an object inside of them is this expression:
所有方格内有物体的损失就是这个表达式:
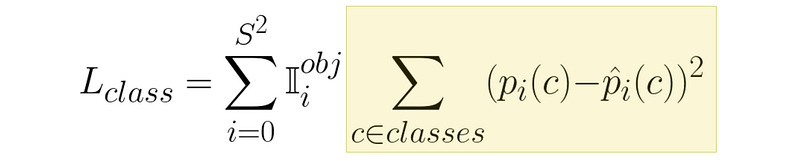
This essentially says “for all classes, subtract the predicted probability by the actual probability, then square it”. For example, if the predicted classes for a given square were this:
这主要是说 "对于所有类别,用实际概率减去预测概率,然后将其平方"。例如,如果某个方格的预测类别是这样的:
dog = 0.9
cat = 0.05
zebra = 0.05But the square actually contains a zebra
但实际上,广场上有一匹斑马
dog = 0
cat = 0
zebra = 1Then the class loss for that particular square would be
那么该方格的类损失为
(0.9-0)^2 + (0.05-0)^2 + (0.05-1)^2Looking at it from a high level, the class loss looks at all the squares that contain an object, and adds up how wrong all the class predictions were for all of those squares.
从高层次来看,类损失会查看包含某个对象的所有方格,并将所有方格的类预测错误率相加。
Bounding Box Loss
边框损失
the bounding box loss can be further broken down into two distinct loss functions. One for the “confidence” of a bounding box, and one for the bounding box coordinates.
边界框损失可以进一步细分为两个不同的损失函数。一个是边界框的 "置信度 "损失函数,另一个是边界框坐标损失函数。

Recall that the bounding boxes have a x and y coordinate, a width and height , and a confidence.
回想一下,边界框有 x 坐标、y 坐标、宽度、高度和置信度。
各种边界框,其中最有信心的边界框更加大胆。摘自 YOLO 论文。
The coordinate loss is pretty straight forward, if you understand the class loss.
如果了解了类损失,坐标损失就很简单了。
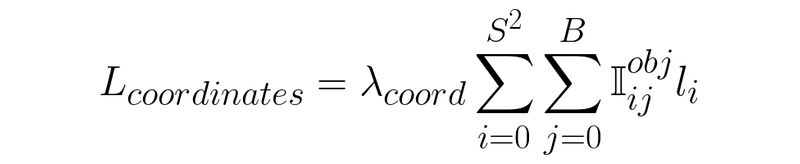
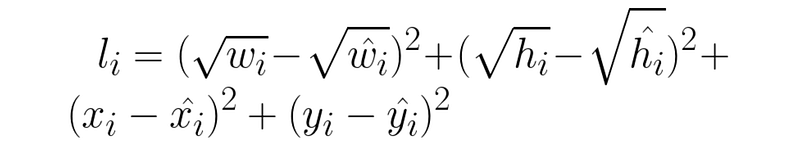
first of all, the only reason this loss function is broken up into two parts is because it’s long, not because it’s especially complicated.
首先,把这个损失函数分成两部分的唯一原因是它很长,而不是因为它特别复杂。
Immediately we see a very similar expression to one we discussed recently.
我们马上就会看到一种与我们最近讨论过的非常相似的表达方式。
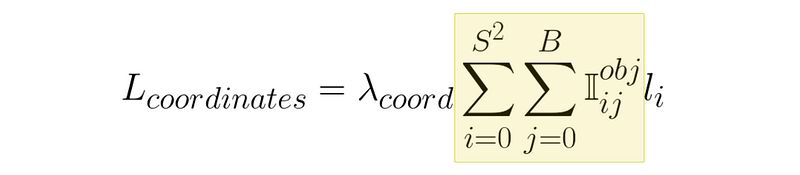
this sums the loss for all squares, in the image (s) and all bounding boxes in each of those squares (B). But, it only ads the loss if an object exists in that square and that particular bounding box is responsible for that object.
这是图像中所有方格(s)和每个方格中所有边框(B)的损失总和。但是,只有当该方格中存在一个物体,且该特定边框对该物体负责时,它才会计算损失。
The coordinate loss for a particular bounding box is very straight forward. It’s just like the difference of class probabilities discussed in the previous section, but for the bounding box dimensions (width, height, x, and y)
特定边界框的坐标损失非常简单。它就像上一节讨论的类概率差异一样,只是边界框的尺寸(宽、高、x 和 y)不同而已
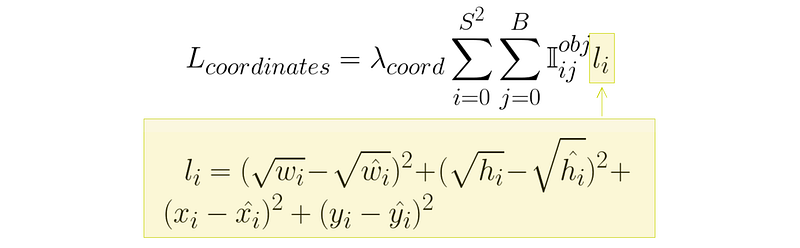
我们将在下一节讨论为什么宽度和高度是平方根,以及为什么损耗按 λ 缩放。
So that’s the actual bounding box coordinates. Recall that bounding box loss comprises of both the coordinates and the confidence, where the confidence is some value that allows a bounding box to say “I should be responsible for this particular object”.
这就是实际的边界框坐标。回想一下,边界框损失包括坐标和置信度,其中置信度是某个值,它允许边界框说 "我应该对这个特定对象负责"。
The confidence loss is calculated with the following expression:
置信度损失的计算公式如下
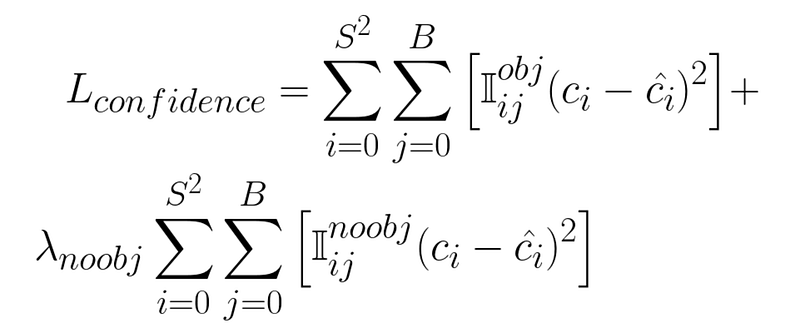
We have the same Σ expressions we’ve seen previously, where we’re adding the loss across all cells and all bounding boxes in each cell.
我们有之前看到的相同的 Σ 表达式,我们将所有单元格和每个单元格中所有边框的损失相加。
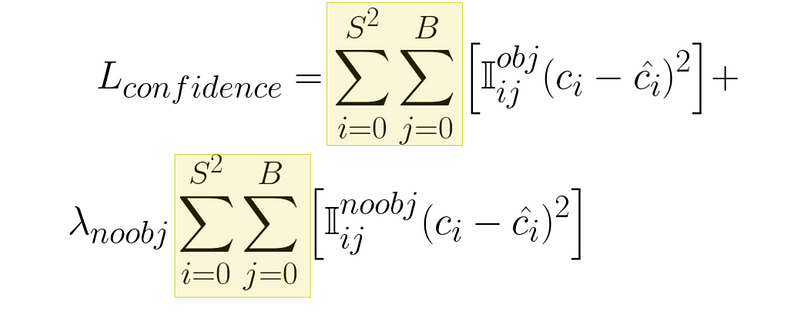
Except, this time, we have two separate filters. One for if the bounding box is supposed to be responsible for an object, and one for if the bounding box is not supposed to be responsible for an object.
只不过,这次我们有两个不同的过滤器。一个是针对边界框是否应该对某个对象负责,另一个是针对边界框是否不应该对某个对象负责。
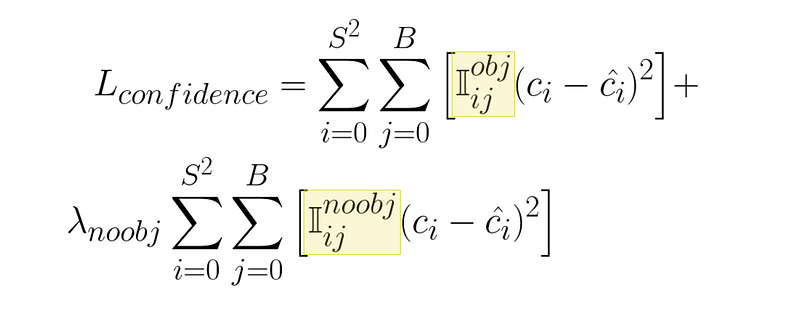
A question might arise at this point. It’s simple what class probabilities should be, it’s whatever the dataset says a class is for a given cell in an image. It’s also simple what the bounding box dimensions should be, it’s whatever the dataset says they should be. But how do we compute what the confidence score of a bounding box should be? How do we say this bounding box should have been responsible, and this one should not have, for a given training example?
这时可能会出现一个问题。类别概率应该是多少很简单,就是数据集所说的图像中给定单元格的类别。边界框的尺寸也很简单,数据集说是多少就是多少。但我们如何计算边界框的置信度分数呢?对于给定的训练示例,我们如何判断这个边框应该负责,而这个边框不应该负责?
This is done by assigning whatever bounding box happens to have the highest “Intersection Over Union” (IOU) as responsible. The IOU is the intersection over union, and is essentially a measure of how well two bounding boxes overlap.
具体做法是将 "交集大于联合"(IOU)最高的边界框指定为负责边界框。IOU 即为 "交集大于联合",本质上是衡量两个边界框重叠程度的标准。
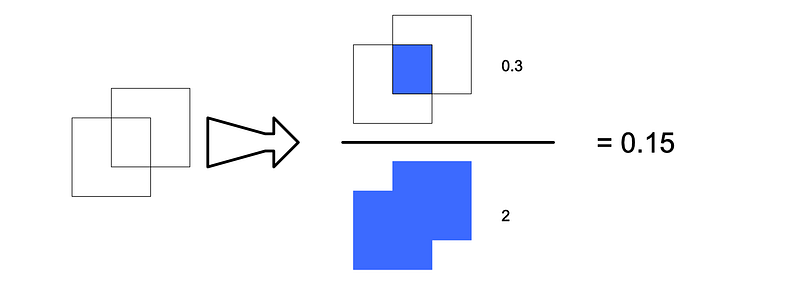
对于两个边界框,IOU 是两个区域的交集除以两个边界框的总面积
So, during training, the bounding box that should be responsible for detecting an object is whichever one already happens to be best at detecting that object. All other bounding boxes in that cell should not be responsible for that object.
因此,在训练过程中,应该负责检测某个物体的边界框,就是碰巧最擅长检测该物体的边界框。该单元中的所有其他边框都不应对该物体负责。
In YOLO, the confidence should be 0 if a bounding box is not responsible for an object, otherwise the confidence should be the IOU of the bounding box with the ground truth bounding box.
在 YOLO 中,如果某个边界框不负责某个对象,置信度应为 0,否则置信度应为该边界框与地面实况边界框的 IOU。
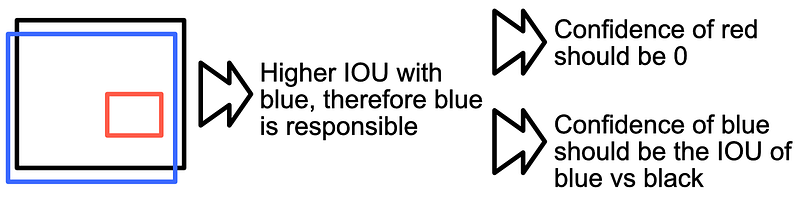
试想一个来自训练数据集的地面真实边界框(黑色),模型在相应的网格单元中预测出两个边界框(蓝色和红色)。因为蓝色方格的 IOU 最大,所以蓝色方格应该对这个特定的边界框负责。因此,蓝色边界框的置信度应该是它与地面实况边界框之间的 IOU。红色边框不负责某个边框,因此其置信度应为零。
It’s useful to reflect on bounding box dimension loss at this point. While, at any given step, the confidence should be whatever IOU the bounding box has vs the ground truth, over successive training steps the bounding boxes should be getting better. So, one would expect the model to learn to increase the confidence scores of bounding boxes as the model learns to predict better bounding boxes.
在这一点上,对边界框维度损失进行反思是非常有用的。在任何给定的步骤中,置信度应该是边界框相对于地面实况的欠条,而在连续的训练步骤中,边界框的置信度应该会越来越好。因此,当模型学会预测更好的边界框时,我们会期望模型学会提高边界框的置信度得分。
There’s a fascinating quirk of this system. Basically, because YOLO can choose which bounding box should be appropriate, it usually ends up making multiple bounding boxes each of which specialize in certain sized objects.
这个系统有一个迷人的怪癖。基本上,由于 YOLO 可以选择适合的边界框,因此它通常会制作多个边界框,每个边界框专门用于特定大小的物体。
Anyway, that’s the loss function. Take a look at it, in all it’s glory, and reflect on how this one function is used to guide the training of the entire model.
总之,这就是损失函数。请看一看它的全貌,并思考一下这一个函数是如何用来指导整个模型的训练的。
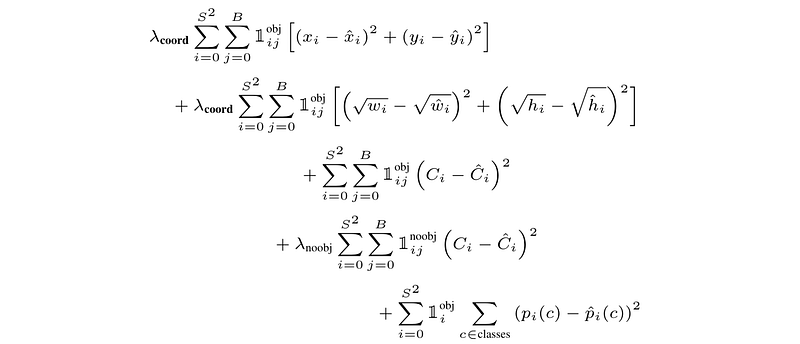
x 和 y 是边界框位置,w 和 h 是边界框大小,C 是边界框置信度,p(c) 是给定类别的预测概率。我们将在下一节介绍 λ 以及其他一些细微差别。摘自 YOLO 论文。
Intricacies of Training YOLO
培训 YOLO 的复杂性
While discussing the loss function I glossed over two intricacies; λs (lambdas) throughout the loss function, and the fact that the width and height of bounding boxes are square rooted.
在讨论损失函数时,我忽略了两个错综复杂的问题:整个损失函数中的λ(λ),以及边界框的宽度和高度都是平方根的事实。
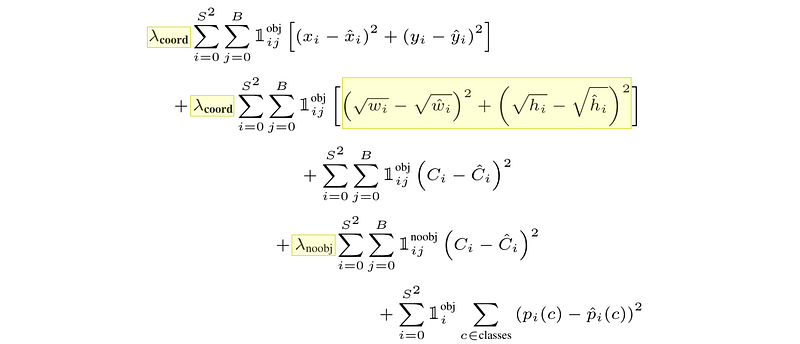
损失函数中的λ和平方根。数据来源
The λs in the loss function are scaling parameters that tune the loss function to better train the model. If we think about some image that might appear in the dataset, most grid cells probably aren’t responsible for an object.
损失函数中的λ是缩放参数,用于调整损失函数,以更好地训练模型。如果我们考虑一下数据集中可能出现的一些图像,大多数网格单元可能并不代表一个物体。
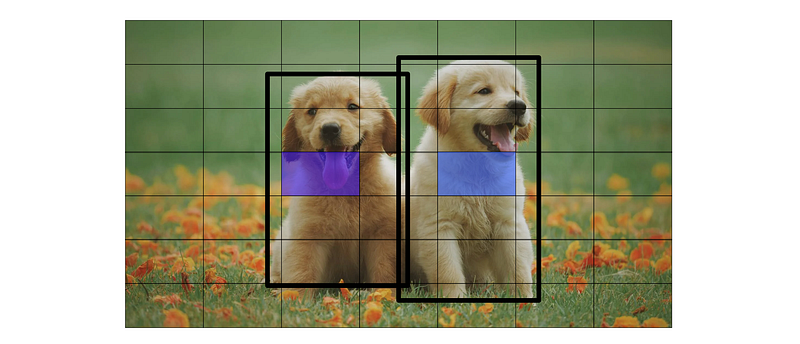
在这幅图中,所有方格中只有两个方格负责一个物体。
Two quirks might arise from this reality:
这一现实可能会产生两个怪现象:
- Instead of learning the difficult task of object detection, the model might just learn that most bounding boxes should have a confidence of zero, and would thus set all confidences to zero.
与其学习困难的物体检测任务,该模型可能只会学习大多数边界框的置信度应为零,并因此将所有置信度设为零。 - There are
(S x S x B)predicted bounding boxes, but only a few of them matter. The model is trying to minimize the entire loss function, so if the loss by bounding box dimensions is a small number, it’s possible the model will hardly try to improve bounding box predictions throughout the training process.
预测的边界框有 (S x S x B),但只有少数几个是重要的。模型试图最小化整个损失函数,因此如果边框维度的损失很小,那么在整个训练过程中,模型可能几乎不会尝试改进边框预测。
The λ parameters solve both of these problems. By making λ_noobj smaller, and making λ_coord larger, the training function can be tuned to make squares that contain objects more important, and increase the importance of correct bounding box predictions. The authors of YOLO settled on the following:
λ 参数可以解决这两个问题。通过使 λ_noobj 变小和使λ_coord 变大,可以调整训练函数,使包含对象的方格变得更加重要,并增加正确边界框预测的重要性。YOLO 的作者采用了以下方法:
λ_noobj = 0.5
λ_coord = 5Another topic we glossed over is the square root of the width and height of the bounding boxes. Refer to the following examples of ground truth and predicted bounding boxes:
我们忽略的另一个问题是边界框宽度和高度的平方根。请参考以下实际边界框和预测边界框的示例:

两个不完善的预测边界框(红色)与地面实况边界框(蓝色)的对比示例。源 1、源 2
Most people would consider the left example to be worse than the right example, because the bounding box width is more wrong on the length than the right. However, both bounding boxes are both equally inaccurate. The difference between the width of the ground truth and the predicted bounding box is around 180 pixels for both images.
大多数人会认为左边的示例比右边的示例更糟糕,因为边界框宽度在长度上比右边的错误更多。然而,这两个边界框同样不准确。两幅图像的真实边框宽度和预测边框宽度相差约 180 像素。
As humans, we don’t care about absolute difference of bounding box size, we care about relative difference of bounding box size. The bounding box on the left is smaller, so the acceptable error in width and height is smaller. The YOLO loss function takes the square root of the width and height to reduce the impact of larger bounding boxes, thereby making it more important to accurately predict small bounding box sizes.
作为人类,我们并不关心边界框大小的绝对差异,我们关心的是边界框大小的相对差异。左边的边框较小,因此宽度和高度的可接受误差也较小。YOLO 损失函数取宽度和高度的平方根,以减少较大边界框的影响,从而使准确预测较小边界框尺寸变得更加重要。
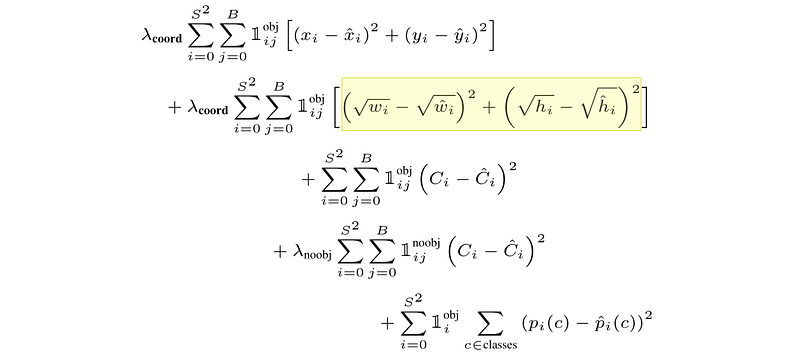
Inference
推论
So, we’ve trained YOLO. We gave it a bunch of images with bounding boxes, and computed the loss to inform the model how to update its parameters via back propagation.
因此,我们对 YOLO 进行了训练。我们给了它一堆带边框的图片,并计算了损失,以告知模型如何通过反向传播更新参数。
Now that we have a trained YOLO model, let’s explore how to use it.
现在我们已经有了一个训练有素的 YOLO 模型,让我们来探讨一下如何使用它。
After we run an image through YOLO, we get back a tensor like this:
将图像通过 YOLO 运算后,我们会得到这样一个张量:
YOLO 的输出。
First of all, we can figure out what classes YOLO thinks corresponds to each grid cell by simply finding the maximum class prediction in each grid cell.
首先,我们只需找出每个网格单元中的最大类别预测值,就能知道 YOLO 认为每个网格单元对应哪些类别。
示例中的类概率。摘自 YOLO 论文。
Each of those grid cells has a bunch of bounding boxes with confidence scores.
每个网格单元都有一堆带有置信度分数的边界框。
各种边界框,其中最有信心的边界框更加大胆。摘自 YOLO 论文。
We can simply set some confidence threshold, like 0.8, to only preserve highly confident bounding boxes. And thus we have our output.
我们可以简单地设置一些置信度阈值,比如 0.8,以只保留置信度高的边界框。这样,我们就得到了输出结果。

高置信度边界框。摘自 YOLO 论文。
There are some quirks to this strategy, however. While YOLO can output multiple bounding boxes per square, facilitating the detection of small and close-by objects.
不过,这种策略也有一些怪异之处。虽然 YOLO 可以在每个方格中输出多个边界框,从而方便检测小型和近距离物体。

YOLO 的概念图,预测每个 SxS 网格单元中多个项目的边界框。资料来源
Unfortunately, a common issue is that multiple bounding boxes might be very confident about the same object.
遗憾的是,一个常见的问题是,多个边界框可能对同一个对象非常自信。

同一物体上的多个包围盒。资料来源
First of all, we can define a threshold for bounding boxes that overlap too much. If the IOU between two bounding boxes is above 70%, for instance, then we can say they’re trying to predict the same object.
首先,我们可以为重叠过多的边界框定义一个阈值。例如,如果两个边界框之间的欠条超过 70%,我们就可以说它们在试图预测同一个物体。
Once we’ve identified a group of bounding boxes as attempting to predict the same thing, we can apply “non-max suppression”. Basically, we just disregard all but the bounding box with the highest confidence.
一旦我们确定一组边框试图预测同一件事,我们就可以应用 "非最大抑制"。基本上,除了置信度最高的边框外,我们可以忽略其他所有边框。

这三个边界框的置信度都超过 70%,因此被认定为预测同一事件。我们只能保留置信度最高的边框(蓝色),而忽略置信度较低的边框(红色)。
Conclusion
结论
And that’s it. In this article we covered YOLO, an object detection model that unified object detection into a single task, allowing it to be both computationally efficient and highly performant. In understanding how YOLO achieved this, we explored the architecture of the model (including its large output tensor), the loss function, and some realities about training and inferencing the model.
就是这样。在这篇文章中,我们介绍了 YOLO,这是一种将物体检测统一为单一任务的物体检测模型,它不仅计算效率高,而且性能卓越。在了解 YOLO 如何实现这一目标的过程中,我们探讨了该模型的架构(包括其庞大的输出张量)、损失函数以及有关模型训练和推理的一些实际情况。
This article focuses on the first YOLO paper. There have been many improvements made to YOLO since it’s publication. I’m planning on covering that in another IAEE article.
本文主要介绍第一篇 YOLO 论文。自《YOLO》发表以来,已经有很多改进。我计划在另一篇 IAEE 文章中对此进行介绍。
If you’re interested in YOLO, and want to learn more about some of the ethical concerns it raises, I have an opinion piece on that.
如果你对 "YOLO "感兴趣,并想进一步了解它所引发的一些道德问题,我有一篇相关的评论文章。
Join IAEE
加入 IAEE
At IAEE you can find:
在 IAEE,您可以找到
- Long form content, like the article you just read
长篇内容,如您刚刚阅读的文章 - Thought pieces, based on my experience as a data scientist, engineering director, and entrepreneur
根据我作为一名数据科学家、工程总监和企业家的经验所撰写的思考文章 - A discord community focused on learning AI
专注于学习人工智能的迪斯科社区 - Lectures, by me, every week
每周由我主讲

加入 IAEE


