
Zero-Shot Learning
A year ago, I just heard about Zero-Shot learning and searched the Internet to find out more about it. Unfortunately, it was not possible to find any useful material around which aims to explain the topic plain and simple back then because it was fairly new research topic. There were research papers mostly focusing on technical aspects and only a couple brief explanations around. Still, it has not changed much. So I’ve decided to share my experience/knowledge here, instead of hiding it to myself, after a year of conducting a relevant project on the subject.
What is Zero-Shot Learning?
Zero-Shot learning method aims to solve a task without receiving any example of that task at training phase. The task of recognizing an object from a given image where there weren’t any example images of that object during training phase can be considered as an example of Zero-Shot Learning task. Actually, it simply allows us to recognize objects we have not seen before.
Why do we need Zero-Shot Learning?
In conventional object recognition process, it is necessary to determine a certain number of object classes in order to be able to do object recognition with high success rate. It is also necessary to collect as many sample images as possible for selected object classes. Of course, these sample images should contain objects taken from diverse angles in various contexts/environments in order to be comprehensive. Although there exists lots of object classes that we can effortlessly gather sample images of, there also exists cases that we are not always so lucky.
Imagine that we want to recognize animals that are on the edge of extinction or live in extreme environments (in the depths of the ocean/jungle or hard to reach mountain peaks) that humans are not able to visit whenever they wish. It is not easy to collect sample images of these sort of animals. Even if you would achieve to collect enough images, remember images should not be similar and they should be as unique as possible — . You need to make a lot of effort to achieve that.

In addition to the difficulty of recognizing different object classes with a limited number of images, labeling for some object classes is not as easy as ordinary people can do. In some cases, labeling can only be done after the subject is truly mastered or in the presence of an expert. Fine grained object recognition tasks like recognition of fish species or tree species can be considered as examples of labelling under the supervision of an expert. An ordinary person will call/label all the tree she/he is viewed as tree or all the fish she/he is viewed as fish. These are obviously true answers but imagine that you want to train a network in order to recognize tree or fish species. In that case, all aforementioned true answers are useless and you need an expert to help you with labelling task. Again, you need to make a lot of effort to achieve that.
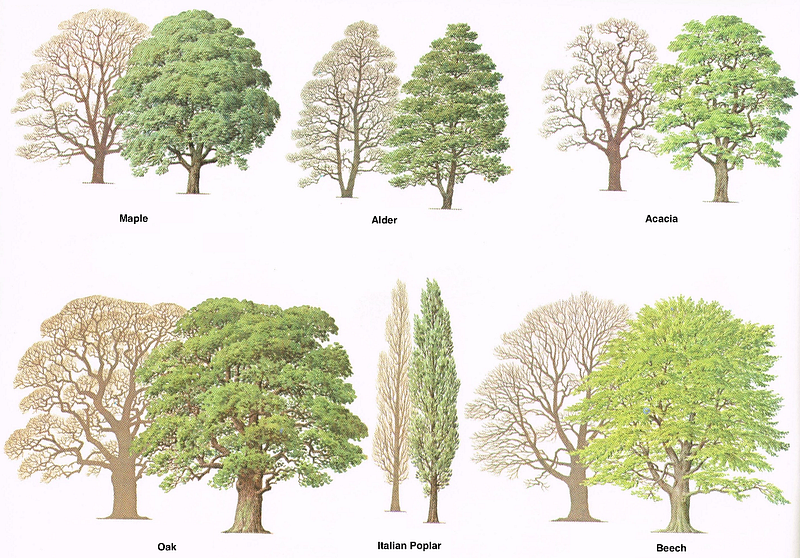
The research paper titled Fine-Grained Object Recognition and Zero-Shot Learning in Remote Sensing Imagery is one of the interesting practical studies about the subject where, in the paper, trees are recognized and classified to species only using their aerial or satellite images which are hard to make sense of but easy to collect when compared to walking around a huge area to take the pictures of trees and label them.
Let’s Get Started
Now that after mentioning what Zero-Shot learning is, let’s implement a Zero-Shot learning model step by step. But before we do that, let’s elaborate our approach.
Approach
We have training and zero-shot classes. Remember that no samples from zero-shot classes will be used during training.Then, how on earth the model trained with training objects will perform recognition on zero-shot objects? In simple terms, how is it possible to recognize objects that have never seen before?
As we all know, to be able to apply any machine learning technique, we should represent data with reasonable features. We should use two data representations and one of the representations should play an auxiliary role. Therefore, we come up with image embedding and class embedding — as auxiliary representation — as our two representations.
Image embedding is nothing special. It is a feature vector extracted from an image using a convolutional network. Convolutional network can be implemented from scratch or a pre-trained convolutional network that had already proven its success, can be used. We will use a pre-trained convolutional model — VGG16 — for image feature extraction process.
Remember that we have training and zero-shot classes. We collect image samples for training classes and naturally, we can get image embeddings for all these image samples. However, we don’t have any image sample for zero-shot classes — we don’t know how they look like — and it is not possible to get image embeddings for zero-shot classes. This is where zero-shot learning method varies from traditional methods. At this point, we need another data representation which will function as a bridge between training and zero-shot classes. This data representation should be extracted from all data samples ignoring that they belongs to training classes or zero-shot classes. Because of that, instead of focusing image itself, we should focus class label which is a common property for all data samples.
Class embedding is the vector representation of a class (class label). It is a representation which we can easily access for each class of objects beside their image representations. We will us Google’s Word2Vecs as class embeddings which will allow us to represent words — class labels — as vectors. In Word2Vec space, two vectors are most likely to be positioned closely if two words — represented with two mentioned vectors — tend to be appear together in same documents or have semantic relations.
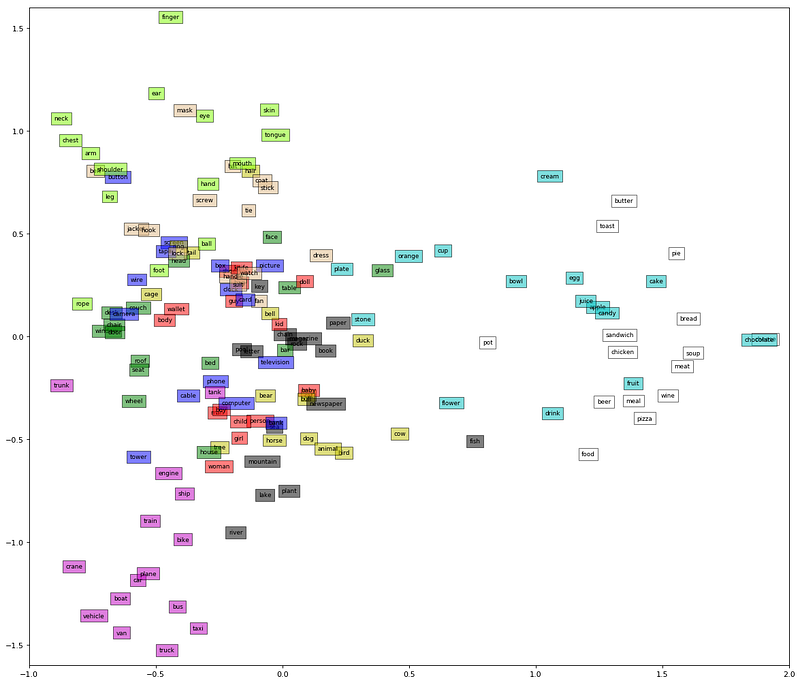
In the example figure above, it can be easily observed that the vectors of classes/words related with eatable objects (indicated with white and turquoise boxes) tend to appear together positionally. However they tend to appear distant from the vectors of classes/words related with body parts (indicated with bright green boxes).
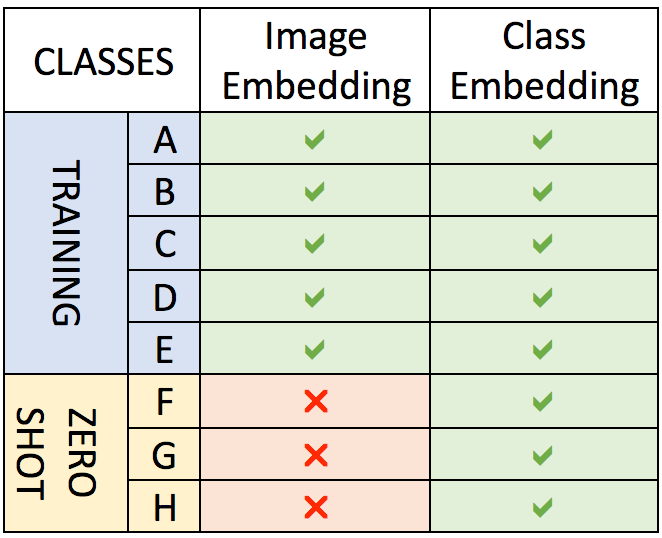
To summarize, for training classes, we have both their image samples and class labels, therefore we have both their image embeddings and class embeddings. However, for zero-shot classes, we only have their class labels — we have never seen any image sample — , therefore we only have their class embeddings. It can be seen much more clearly by looking at the figure on the left side.
At the end of the day, what we simply want to do is this; we will use the image embeddings (image feature vectors) and their related class embeddings (word Word2Vecs) for training classes. This way, the network will basically learn how to map a given input image to a vector located in the Word2Vec space. After training is done, when an image of an object belonging to the zero-shot classes is given to the network, we will be able to obtain a vector as output. Then, by using this output vector (measuring its distance to all class vectors that we have — both training and zero-shot — ), we will be able to perform classification.
Data Collection
As a first job, we need to collect image data which are required during the training phase and at the evaluation phase to measure the Zero-Shot performance after training. I collected data from Visual Genome and decided to use 20 classes in total where there are 15 classes selected for training and 5 classes selected as Zero-Shot classes.
Then, we should determine which object classes are to be selected as training classes and which are to be selected as Zero-Shot classes. For ease of illustration, it will be much more suitable to recognize daily objects instead of preforming and selecting proper classes for a fine-grained object recognition task.
Remember that we are not going to use Zero-Shot classes during training.
Image Feature Extraction and Dataset Formation
After collecting enough image samples (400 samples for each class, both training and zero-shot), now it is time to extract features from these sample images. For this task, we preferred to use a pre-trained image classification network — VGG16 — which is trained on ImageNet.
From the Visual Genome, we obtained images and its corresponding annotations which indicate the locations of objects in images. For each image, coordinates of objects that occur in the image are obtained from corresponding image annotation and objects are cropped. Then, image features are extracted from these cropped images using a pre-trained model, VGG16 in our case . Feature extractor class can be seen below.
Word Embeddings
After we have extracted the image features and formed the datasets, now we should gather the other representations of classes, word embeddings namely. We will use Google Word2Vec representation trained on Google News documents. We will get a Wor2Vec of 300 dimensions for each of the 20 object classes we have specified.
Model Training
Structure of the model must be designed in a way that given inputs (image features) should be map to corresponding outputs (Word2Vecs). Since we have already used a pre-trained convolutional model to obtain image features, now, we need to create a small follow up fully-connected model.
The important point here is creating a custom layer that will be the last layer of the model. The weights of this layer must be determined using Word2Vecs of the training classes and the layer must be untrainable which means that it should not be affected by gradient updates during training, remains unchanged. It will be a simple matrix multiplication placed at the end of the network.
For the categorical classification task, ReLU is used as activation function at each layer except output layer where a probability distribution — softmax function — is used instead.
Below, last epoch information of the training phase can be seen.
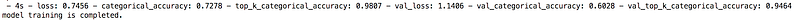
We achieved good-enough scores by using 15 training classes for training.
Zero-Shot Model
At this point our trained model looks like this.
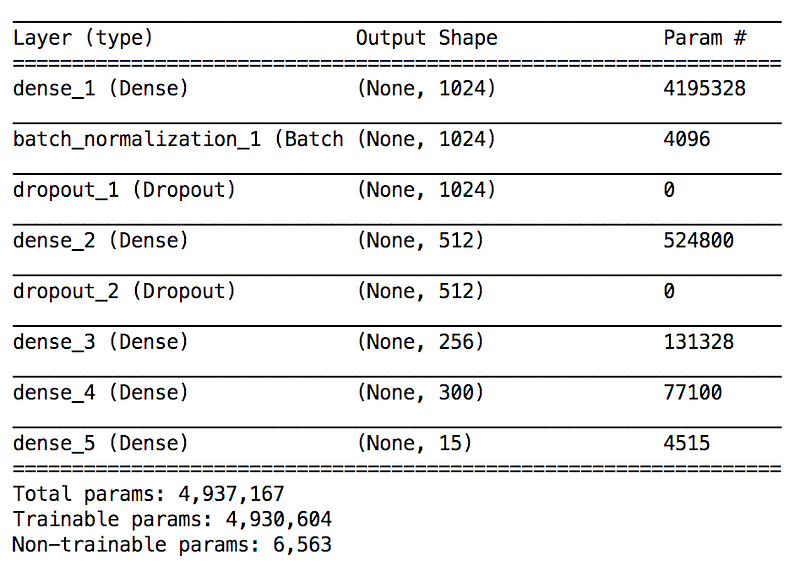
Remember, we planned to use Word2Vecs as a bridge to recognize object classes that we had never seen before and we said that the model should give a vector output for each input image. To be able to achieve that, we need to remove the last layer of the model which was untrainable and custom-defined.
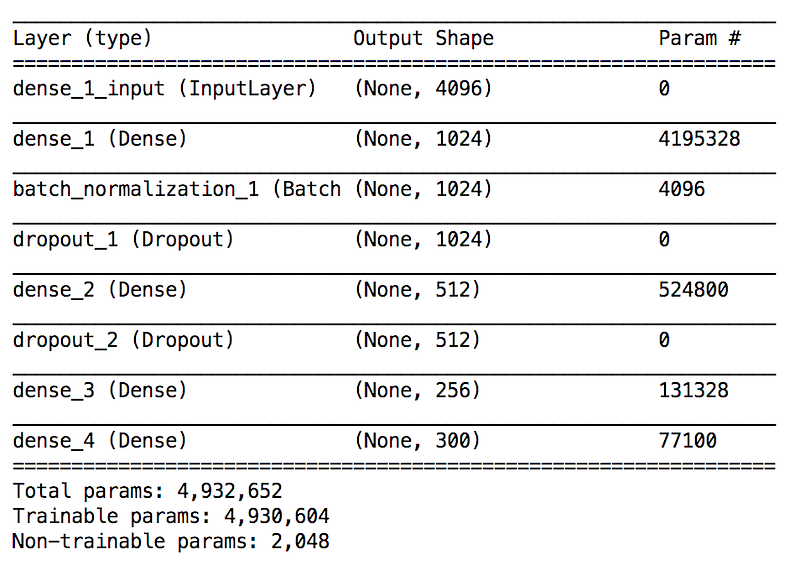
Now that after we delete the last layer of the model, we can now get a 300-dimensional vector which indicates a coordinate in vector space, for each image input. We will map this output vector to the nearest one by comparing it with the vectors of all 20 classes we already have.
Zero-Shot Model Evaluation
We created the Zero-Shot model. Now it is time to measure the performance of it. We will use the samples of Zero-Shot classes that we already determined. We have not used these samples at any stage of model training. Let’s remember these classes: car, food, hand, man and neck. We collected 400 images per each class (2000 images in total) and just by performing Zero-Shot classification — using 300 dimensional output vectors — we will measure the performance of the model.
After we have obtained a vector (Word2Vec) for each image sample, we compare this vector with 20 vectors representing each class of ours. We use euclidean distance metric for this. Then, we declare that the class belonging to vector which is the closest one to our output vector, is the class that we predict.
Now that we’ve performed the evaluation, let’s take a look at the performance of the Zero-Shot model.

Top-5 accuracy is almost 79%. Remember that we are able to classify images that we have never seen before — model does not know how the objects belonging to these classes look like — with these accuracy percentages which is not bad at all! Remember the model is only given the information of where the word vectors of these classes are located in word vector space. It is waaay better than random classification.
Accuracy doesn’t always that great (79%) because it is really hard to classify fine-grained object categories with high accuracy. In our case, I chose relatively discrete daily object classes to express how zero-shot learning algorithm works and can be implemented. That should explain high accuracy. If you remember from introduction part, I gave examples about fine grained object problems like classification of tree/fish species. These are the problems that it would be wise to try zero-shot learning on.
Conclusion
Zero-Shot Learning is a very new area of research, but it is an unquestionable fact that it has a very high potential and it is one of the leading research topics in Computer Vision.

It can be used as a base system for many projects in the future: A helper embedded system for visually impaired people can be developed using Zero-Shot learning. Natural life surveillance cameras can use Zero-Shot learning to detect and count rare animals in their own habitat.
With the developments in robotics field, we are trying to produce robots that are similar to ourselves. Human vision is among the most important characteristics that made us human and we want to transfer this feature to robots. We are able to interpret and recognize an object even we have never seen a sample where at least we can reason about what that thing is. Zero-Shot learning method is similar to human vision system in many ways, therefore it can be used in robot vision. Instead of performing recognition on a limited set of objects, using Zero-Shot learning it is possible to recognize every world object.
Thanks for reading. I hope it is helpful.
Remember to check my GitHub repository for more detailed work and feel free to buy me a coffee :)






