
YOLOX: Anchor Free YOLO
Most YOLO family, e.g. YOLOv3, YOLOv4, YOLOv5 and YOLOv7, are anchor based detectors. The performance are optimised for anchor based framework. However the predefined anchor size, as a strong prior, may limits the detection performance.
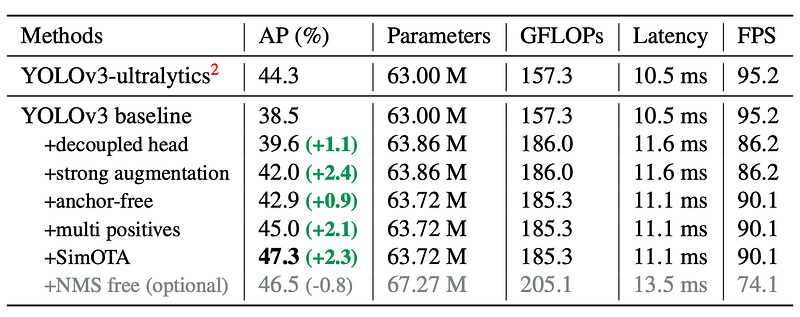
YOLOX is based on YOLOv3-SPP with DarkNet53 backbone and an SPP layer. Apart from make YOLO anchor free, it also applied decoupled head, mosaic/mix-up augmentation, multiple positive and simOTA to boost the performance.
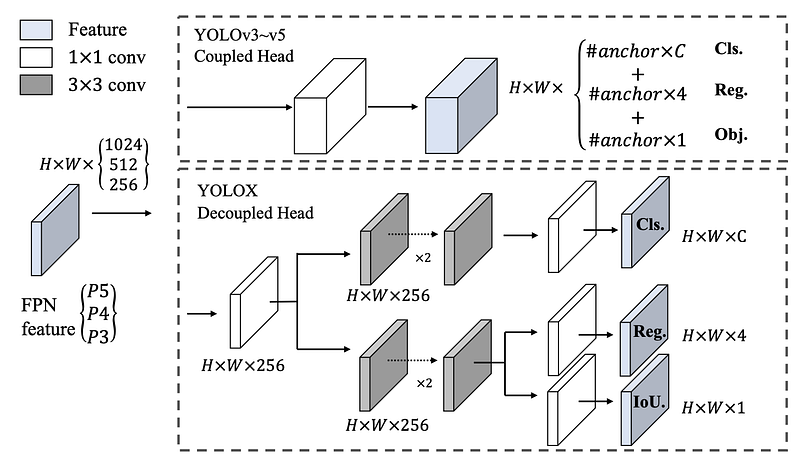
Decoupled head is proposed to resolve the conflicts between regression and classification tasks. YOLOX proposed a lite decoupled head which increase the inference time for only 1ms on Tesla V100. Decoupled head helps model to coverage faster during training.
Strong augmentations: mosaic and mix-up are adopted. This strong augmentation eliminates the need of pre-trained weights with ImageNet. So all YOLOX models are trained from scratch.
Anchor free: Change the head to be anchor free make the model a lot simpler. The output for each pixel is four values, i.e. offset to top left corner and object width/height.
Multiple Positives: Use 3x3 area to allow multiple positive matches during training
SimOTA: OTA[2] is an advance label assignment strategy, that use optimal transport concept to assign labels. Using original OTA, the training time is increased 25%, so simOTA is proposed to use top k best predictions to obtain approximation. The simOTA is summarised as
- calculate the gt-prediction pair cost c_ij based on the classification and regression loss
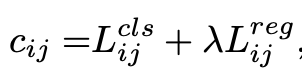
- for each ground truth box gt, k best predictions, that are closest and within the center region, are matched to gt
- note: the k is decided dynamically based on the gt box
End-to-end training: Following [3], end-to-end training are introduced to eliminate NMS from detection framework. However the performance drop quite a bit.
Training details:
- 300 epoch with 5 epoch warm up
- scaled learning rate lr×BatchSize/64, lr=0.01, cosine schedule
- SGD optimiser with momentum 0.9, weight decay 0.0005
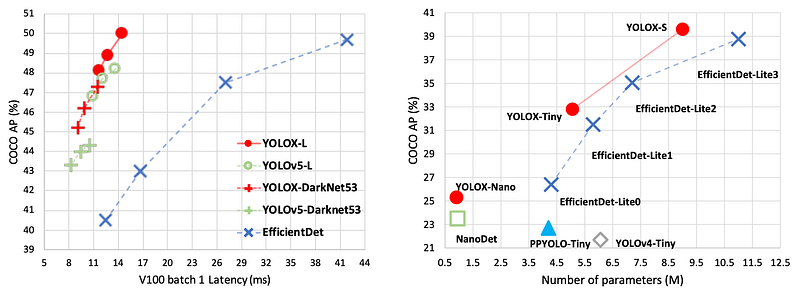
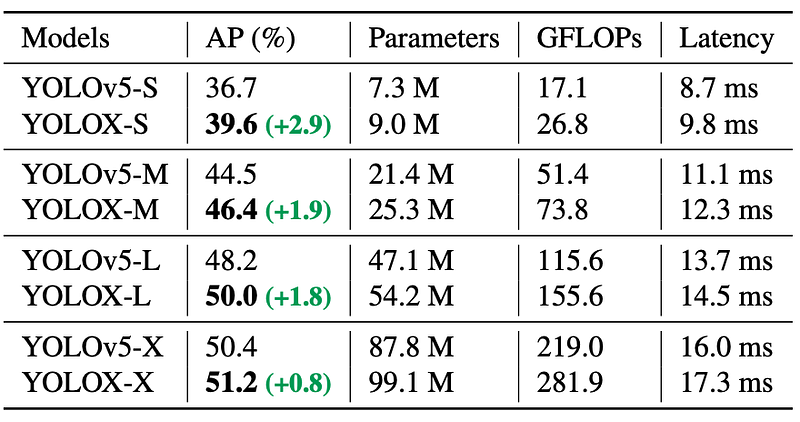
YOLOX vs YOLOv5: YOLOX outperforms YOLOv5 on all model scales with input resolution 640x640.
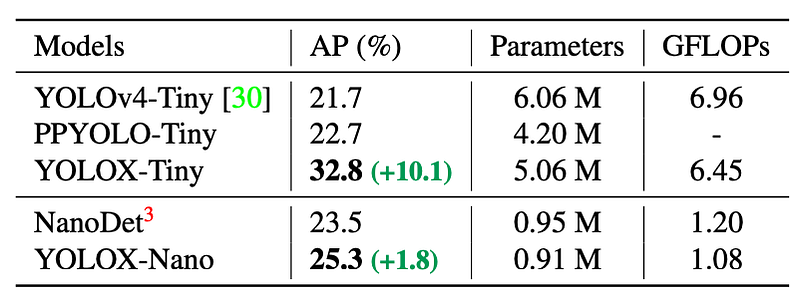
Tiny model: YOLOX-Tiny outperforms all other similar sized models.
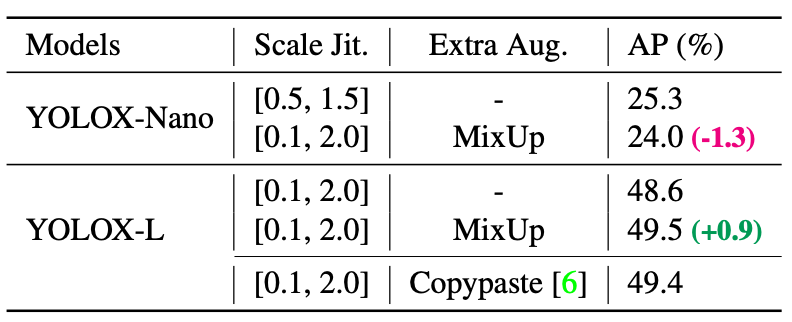
Interestingly, mix-up augmentation improve performance of large model but does not help with tiny model
- Ge, Zheng, et al. “Yolox: Exceeding yolo series in 2021.” arXiv preprint arXiv:2107.08430 (2021).
- Ge, Zheng, et al. “Ota: Optimal transport assignment for object detection.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
- Zhou, Qiang, et al. “Object detection made simpler by eliminating heuristic NMS.” arXiv preprint arXiv:2101.11782 (2021).




