
YOLO-World Unveiled: The Future of Instant, Training-Free Object Detection

On the 31st of January, 2024, the AI Lab at Tencent unveiled its groundbreaking model known as YOLO-World, a cutting-edge tool capable of identifying objects in real time across an open vocabulary without the need for prior training.
YOLO-World enables the identification of any object through simple prompt inputs. For access to the model, visit the YOLO-World GitHub page.
The innovation of YOLO-World addresses a critical gap in existing zero-shot object detection technologies by enhancing processing speed. Unlike the slower Transformer-based models that are common in the field, YOLO-World employs a quicker CNN-based architecture derived from the YOLO framework.
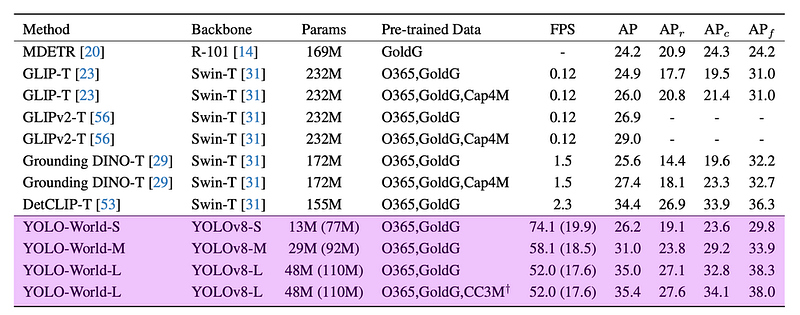
Refer to the YOLO-World research document for a detailed comparison of YOLO-World against contemporary open vocabulary techniques, focusing on speed and accuracy metrics tested on the LVIS dataset and analyzed using NVIDIA V100 GPUs.
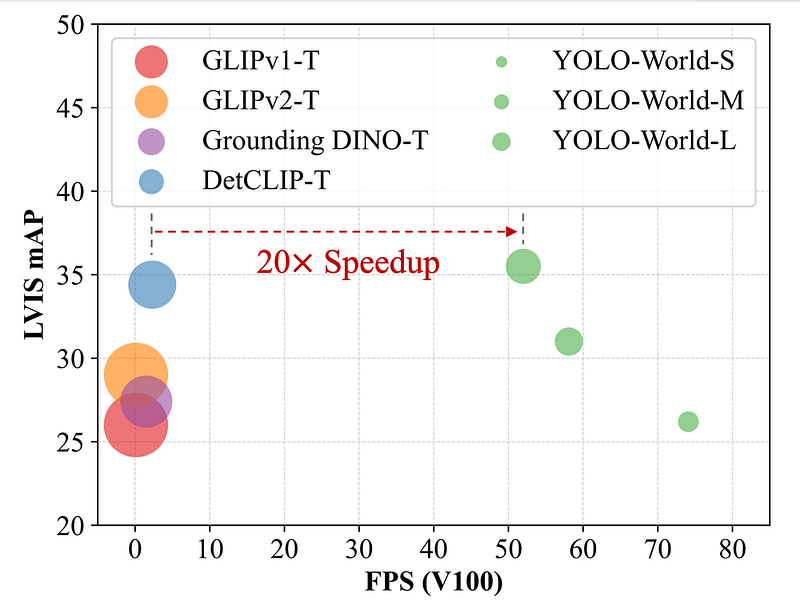
This article will explore the essence of YOLO-World, delve into the evolution of zero-shot object detection, and evaluate the model’s performance as described in the YOLO-World publication.
Evolving from Conventional to YOLO-World Detection Methods
Conventional Object Detection Frameworks
Conventional models for object detection, such as Faster R-CNN, SSD, and YOLO, are built to recognize objects within a specific array of categories determined by their training data. For example, models trained with the COCO dataset are confined to recognizing 80 different categories.
This restriction limits their use to scenarios that directly align with the training data. Expanding or modifying the set of recognized classes requires retraining or adjusting the model with a new dataset designed for the desired categories.
The Advent of Open-Vocabulary Object Detection
In response to the constraints of fixed-vocabulary detectors, the concept of open-vocabulary object detection (OVD) emerged, aiming to identify objects outside the pre-established categories. Initial efforts in this area, such as GLIP and Grounding DINO, sought to expand the detection vocabulary through extensive image-text data training, thereby enabling the recognition of previously undetectable objects with simple model prompts.

These models, however, are generally larger and demand more computational resources, as they require the concurrent processing of image and text data for predictions. This complexity can introduce delays, detracting from their utility in time-sensitive applications. For an introduction to using GroundingDINO, refer to this instructional guide.
Understanding YOLO-World
YOLO-World represents a significant leap in open-vocabulary object detection technology, proving that streamlined detectors like those in the YOLO lineup can deliver robust performance in open-vocabulary tasks. This breakthrough is particularly relevant for applications demanding efficiency and speed, such as those on the edge.
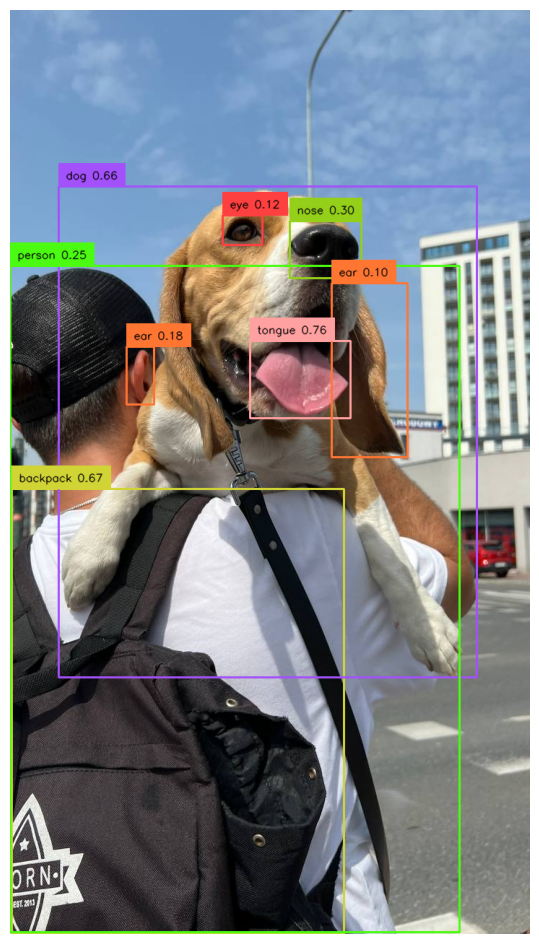
YOLO-World is equipped with grounding capabilities, enabling it to interpret the context of prompts for accurate detections without needing specific class training. It leverages a vast training set of image-text pairs and grounded images to understand and respond to various prompts, such as “person wearing a white shirt.”
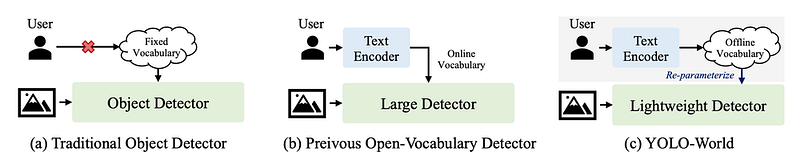
By introducing a “prompt-then-detect” methodology, YOLO-World circumvents the need for on-the-fly text encoding, instead utilizing an offline vocabulary generated from user prompts for detection.
This method significantly diminishes computational demands, allowing for the flexible adjustment of the detection vocabulary to meet diverse requirements without compromising performance, thereby broadening the model’s applicability in real-world scenarios.
YOLO-World’s Architectural Components
YOLO-World integrates three principal components:
- The YOLO detector, based on Ultralytics YOLOv8, captures multi-scale image features.
- A Transformer-based text encoder, pre-trained by OpenAI’s CLIP, transforms text into embeddings.
- The Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN) facilitates cross-modality fusion between image features and text embeddings.
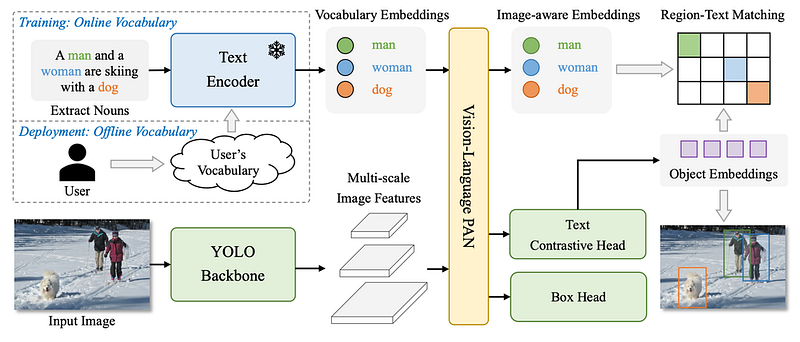
The model employs the Text-guided Cross Stage Partial Layer (T-CSPLayer) and Image-Pooling Attention mechanisms to enhance the interaction between text and image features, optimizing detection accuracy.
Performance Insights into YOLO-World
YOLO-World outpaces prior zero-shot detection models, offering a blend of efficiency and accuracy previously unattainable. It is presented in three sizes, demonstrating impressive performance metrics on the LVIS dataset without relying on acceleration technologies.
Concluding Remarks
YOLO-World marks a pivotal advancement in object detection technology, offering unparalleled speed and efficiency in open-vocabulary applications, thereby unlocking new possibilities in video processing and edge deployment scenarios.




