
Yelp/Proximate Places Search System Architecture
Please clap and share if you like this article.
Yelp is the largest review website in the United States. Users can give their comments for hotels, restaurants, shopping malls, tourism, and other fields from all over the world. Users can rate those businesses, submit their reviews, share their experiences on the Yelp website. The Yelp concept is similar to foursquare in Europe. The Yelp app allows 142 million users to search for local businesses and services and rate them. In the end, the Yelp rating review increase local sales up to 5–9%, which equates to roughly $8,000 dollars annually. It is successful because it streamlines production lines, making consumers directly with demand.
Functional Requirements
- The system can store information about different places so that users can rate and review based on the other user's feedback
- Users can edit the basic information of the places or add new places with a brief description or delete the old places
- Users can give ratings (1 to 5 stars) and reviews (text and images) to places
- The system will detect users nearest location (longitude/latitude), users can search all the proximate places within a given radius for any locations
- Users can create an account, log in and logout from the account.
New Features
- Wait-time Prediction
Non-Functional Requirements
- The system must be highly available with the real-time search experience
- The system must have low latency
- The system must allow read-heavy and support a high number of search requests, up to 200 search requests per second
- The system can be scalable, up to 40 million places.
Scale Estimation
Total number of places in the system = 200 million
Total requests per second = 100k
Scalability =20% growth per year
Target Goals
- Manage 500 million scale
- Able to handle 250 k requests per second
Database Schema
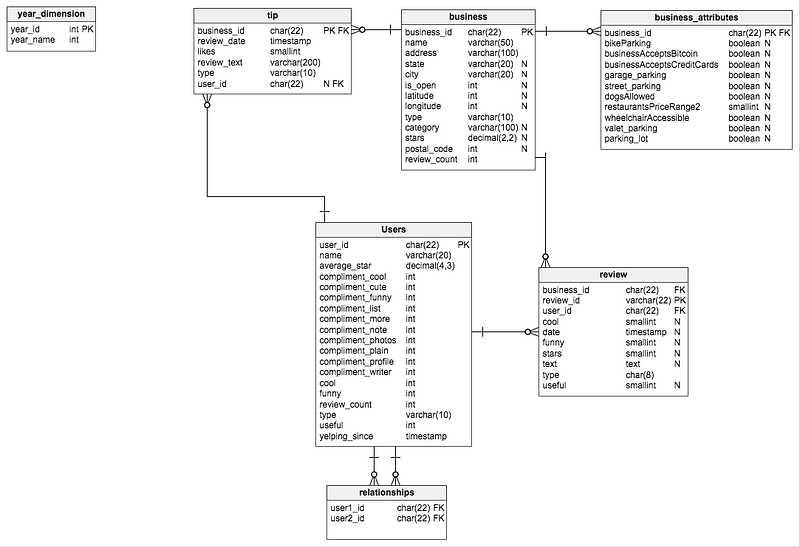
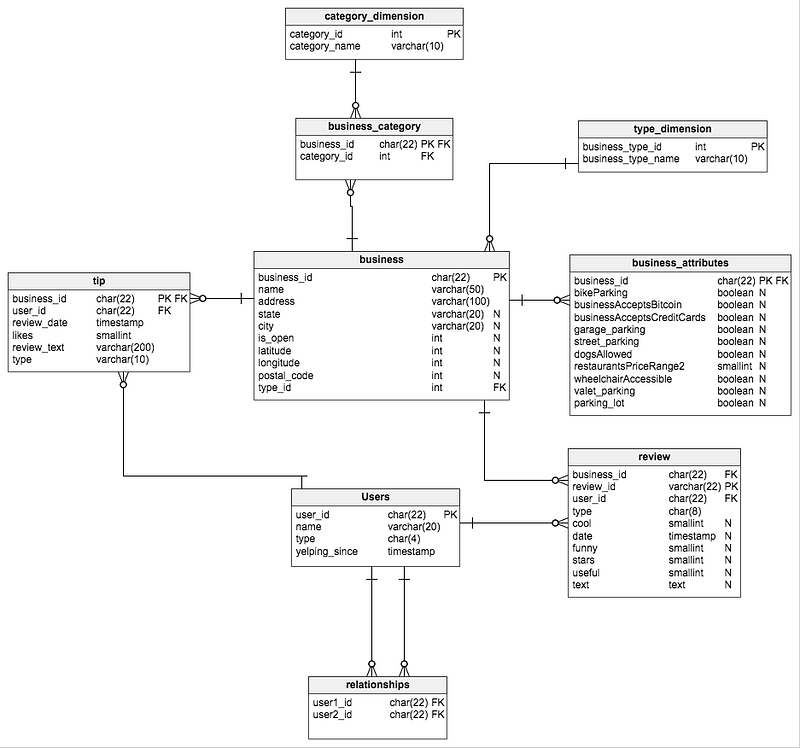
- User Profile Data: User ID, Name, Email, Mobile Number, sex
- POI (point of interest)/ the relationship Profile: Place ID, Name, Category, GPS location, Photo link, description, place review, and rating
- Review: Review ID, USer ID, Place ID, Rating, Photos, review text
- Business Category: Business attribute
System API
- Search API
- Add places/Business API
- Add Reviews API
- Business Match API
- Event Lookup API
- Event Search API
- Featured Event API
- Phone Search API
- Transaction Search API
AI-autogenerated Review
System Design Concepts
- SQL based Storage
- Places, reviews, user details are the main metadata that must be stored in SQL DB. Location (latitude and longitude) can be indexed for search optimization. Nearby places search will be seen in real-time.
- Each place will be stored in a separate entry, identified by LocationID.
- When the nearby places search is used, the given location (X, Y) within a radius “D”, we can query like where latitude between X-D and X+D and longitude between Y-D and Y+D.
- Each index will return a huge list of places, so the query process won’t be efficient.
2. Grid
Fixed Grid Size
- divide the whole maps into grids and group them into a grid ID.
- Each grid ID will store all the places residing within a certain range of latitude and longitude
- Based on a given location, we can find all the nearby grids and then query these grids to find nearby places
- Each grid size must be equal so that the distance of each grid size is standard
- Can run slow because some places are not uniformly distributed among grids
- For the thickly dense area with a lot of places and sparsely populated with few places, the same grid size cannot give the approximately same number of places
Using Dynamically Adjusting Grid Size/QuadTree

Heuristic Rule
- Don’t put more than 500 places in a grid, so that users can search fast
- When a grid reaches its limit, break the grids into 4 smaller grids of equal size and distribute places fairly among them
- Small grids for the thickly dense area with a lot of places and large grids for sparsely populated with few places
- What if the area keeps growing new places in a grid, so it will break the 500 places limit in a grid
- Also, It will reach the memory limit of the server
3. Data Partitioning
Sharding Based On regions
- Further category the places into regions (like Zip codes) such that all places belonging to a region will be grouped together
- Places and user’s locations will be tagged by their respective region. While querying for or storing the nearby places, the region server will be working
- What if a region has a lot of queries on the server? it will make the performance slow
- Over time, some regions can store many places but some don’t. It will cause memory issue while regions are growing.
- We must repartition our data by using consistent hashing
Sharding based on LocationID
- The hash function will be used to map each LocationID to a server for the places
- Calculate the hash of each LocationID to find a suitable server to store the place
4. Replication and Fault Tolerance
- Replication is for the read purpose. So that we have replicas of the QuadTree server, we can distribute read traffic.
- Implement master-slave configuration, where replicas will serve only read traffic, and all write traffic will go to the master, then be copied to slaves
- What if the QuadTree server dies? We can have a secondary replica to take control after the failover
- What if the primary and secondary QuadTree server dies at the same time? We can allocate a new server and rebuild the same QuadTree by the brute-force solution which will update the whole DB and filter LocationIDs using our hash function.
- HashMap, where “key” would be the QuadTree server number, and the “value” would be a HashSet containing all the places being kept on that QuadTree Server (key = locationID)
- Write operation = map the place ID onto one of the partitioned databases using a hashing function
- Photos will be uploaded into external cloud DB such as Amazon S3
- Path link is stored in the DB
- Read Operation = Pass on the user’s query to the geo-hashing server
5. Cache
- Install a cache in front of DB
- Memcache will be used
- The least recently used (LRU) will be used
6. Load Balancing (LB)
- add load balancing at clients and application servers
- The Round Robin approach will be adopted
- If a server is dead, the lb will take over and stop sending any traffic to the server
- But Round Robin LB will not stop sending new requests to the server if a server is overloaded
- A more intelligent LB will be needed
7. Ranking
- Add popularity or relevance features
- Keep track of the overall popularity of each place
- How many stars do users give averagely
8. Yelp Recommendation Algorithm
- Sentiment Analysis model using LSTM and GloVe
- Recommendation Engine: a real-time recommendation generator (Databricks + Apache Spark + AWS)
- Content-Based
2. Collaborative Filtering
3. Social Network
4. Location-Based
https://www.researchgate.net/publication/344768108_Sentiment_Analysis_based_on_GloVe_and_LSTM-GRU
The High-level System Architecture Diagram
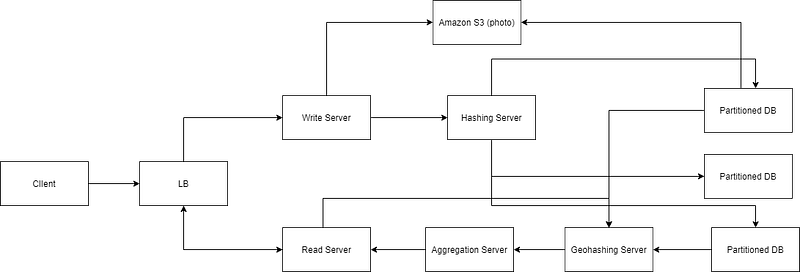
Wait-Time System Architecture
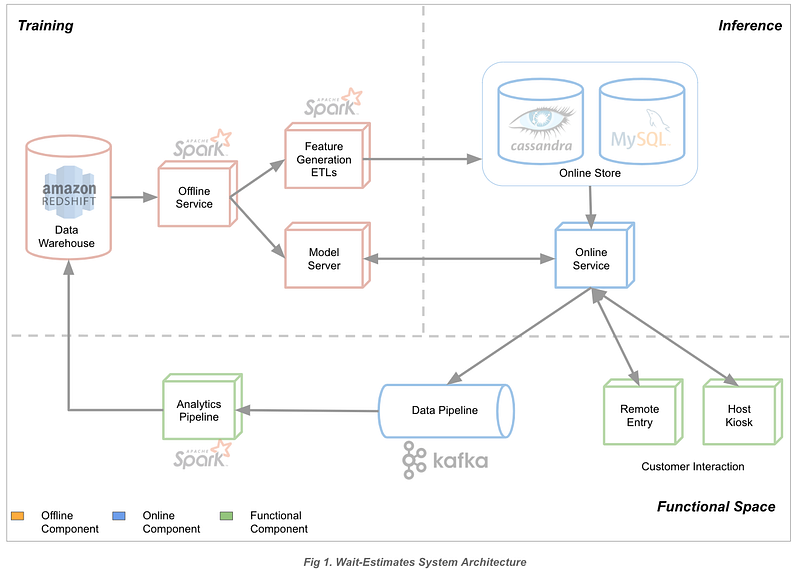
The Detailed System Architecture
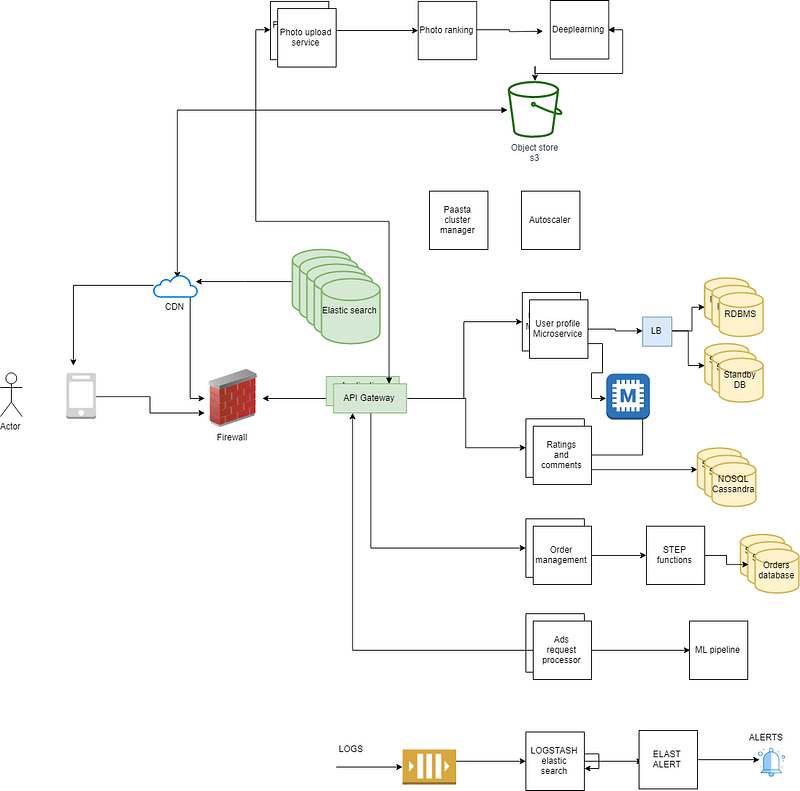
Many doubts may come out to your mind after reading this article.
- How can we solve the problem of grid imbalance?
- How can we solve the system problem to achieve high availability and fault tolerance?
Further Study
References
If you’ve found any of my articles helpful or useful then please consider throwing a coffee my way to help support my work or give me patronage😊, by using
Last but not least, if you are not a Medium Member yet and plan to become one, I kindly ask you to do so using the following link. I will receive a portion of your membership fee at no additional cost to you.





{kind=link}