
XLNet: Autoregressive Pre-Training for Language Understanding
Understanding Transformer-Based Self-Supervised Architectures

State of the art Language Models like BERT, OpenAI GPT have been stellar in Natural Language Processing in recent times. These models are based on the Transformer architecture, which has driven RNN-based and Convolution-based models out of the business.
In this article, we’ll be discussing the XLNET model, which was proposed in a recent paper: XLNet: Generalized Autoregressive Pretraining for Language Understanding. This model has addressed certain drawbacks of BERT and has successfully overcome them by outperforming BERT in 20 tasks.
If you’re interested in knowing the concept behind BERT or Transformers, consider giving this (BERT) and this (Transformer) a read.
So, What’s Wrong With BERT?
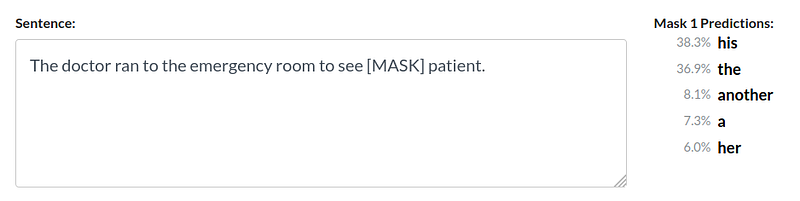
Input Noise
One major issue with BERT is essentially its pre-training objective on masked sequences i.e the Denoising Autoencoding objective. Masking the sequences greatly helps in understanding the trends in the language corpus, however, while fine-tuning, the sequences aren’t expected to be masked.
However, the artificial symbols like [MASK] used by BERT during pre-training are absent from real data at fine-tuning time, resulting in a pretrain-finetune discrepancy.
Independence Assumption
BERT maximizes the joint conditional probability p(x_t | x_hat), where x_t is the masked term and x_hat is the sequence of tokens. It is read as, probability of a masked token x_t to occur at the ‘t’th position, given all the tokens in that sequence x_hat.
This gives the intuition of an independence assumption that each of the masked tokens are reconstructed separately. We’ll clear this in a later section.
XLNET
As opposed to BERT, XLNet is an auto-regressive model. This essentially removes its dependency on denoising the input.
However, autoregressive models are mostly criticized for their unidirectional nature. Hence, to overcome this, XLNet proposes a novel Permutation Language Modeling objective that overcomes this unidirectionality.
Permutation Language Modeling
As mentioned previously, XLNet proposes a mechanism that takes the good stuff from both worlds (i.e. autoencoding and autoregressive). It doesn’t have the denoising of inputs as in the autoencoding objective and removes the unidirectionality from a traditional autoregressive objective.
To achieve this, while factorizing the joint probability p(x_t | x_(i < t)), instead of using a fixed forward or backward factorization order as in traditional autoregressive models, XLNet maximizes the log-likelihood of a sequence w.r.t all possible permutations of the factorization order.
Specifically, for a sequence x of length T, there are T! different orders to perform a valid autoregressive factorization. Intuitively, if model parameters are shared across all factorization orders, in expectation, the model will learn to gather information from all positions on both sides.
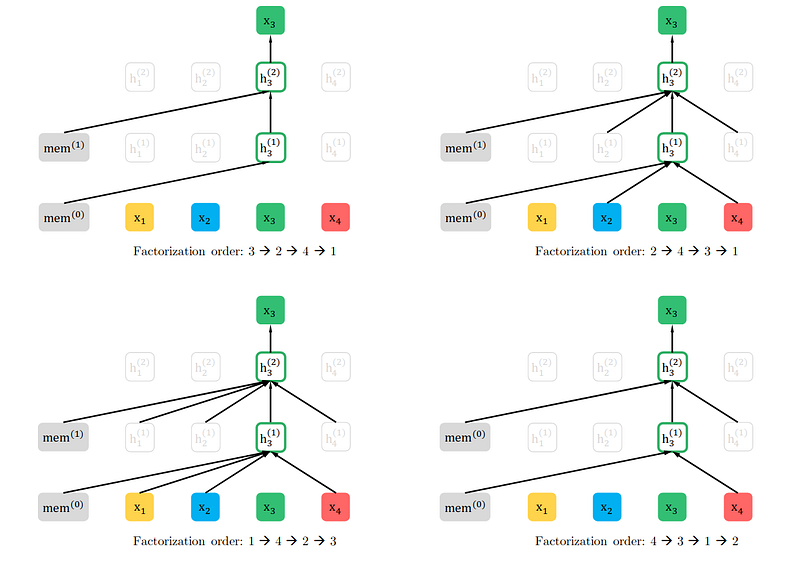
To elaborate more on this objective, let’s take an example. Consider the above figure with a sequence x with 4 tokens. For simplicity, we consider the attention computation only for x_3. Observe the permutation order stated under each of the figures above.
- While taking the order 3 -> 2 -> 4 -> 1, 3 happens to be the first token from the sequence. Hence, none of the other tokens contribute to its attention computation. Because they do not precede 3 in the current permutation.
- In the order 2 -> 4 -> 3 -> 1, 3 is preceded by 2 and 4, hence they contribute to its attention computation.
- Similarly, for 1 -> 4 -> 2 -> 3 and 4 -> 3 -> 1 -> 2, the corresponding x_(i < t) contributes to the attention computation of x_t.
More formally:

Note that, while training, it is not correct to actually obtain the permutation of the sequence, as the sequences can’t be permuted while fine-tuning on the downstream task or during inference. Hence, the attention mask in the Transformer is properly manipulated to obtain the correct permutations; which also makes sense because the proposed architecture talks about permuting over the factorization order and not the sequence order.
Two-Stream Self-Attention for Target-Aware Representations
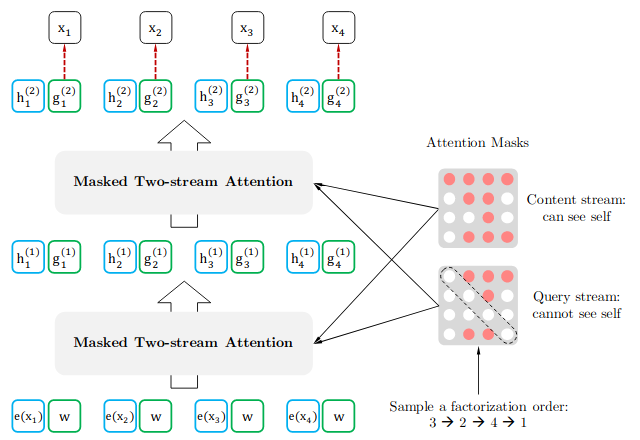
The regular Transformer parametrization may not work with the permutation language model. To understand this, let’s consider the standard formulation of the distribution using softmax which is given by:
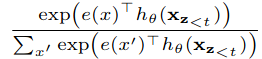
Here, the term h_θ(x_(z_(< t))), is the hidden state of the transformer for x_(z_(<t)). This term, is in no way dependent on the position that it predicts i.e. z_(<t). This means, that whatever position is being predicted, this distribution will be the same; thus posing the inability to learn useful trends.
Hence, to overcome this, the XLNet paper proposes a re-parametrization for the next token distribution to be target aware:
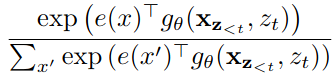
A modified representation g_θ is used, which additionally takes the target position z_t as the input. So, two hidden states are used instead of one:
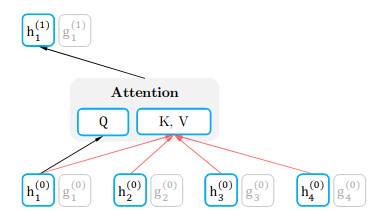
- The content representation, which is essentially the same as the standard Transformer hidden state. This representation encodes both; the context x_(z_(<t)) as well as the original token x_(z_t).
Mathematically:
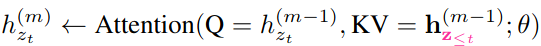
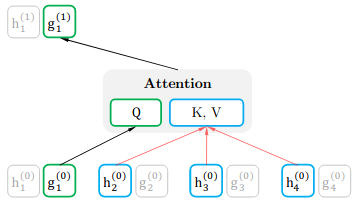
- The query representation, that has access only to contextual information x_(z_(<t)) and the position of the target z_t.
Mathematically:
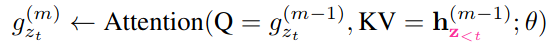
Note that, initially the content stream (h_i) is essentially the corresponding embedding vector (e_x_i), and the query stream (g_i) is a trainable vector (w) initially. These are updated over each layer using the above expressions.
Partial Prediction
Keeping aside all the benefits that permutation LM has, we gotta accept that it is expensive. It is a challenging optimization problem due to permutation.
Hence, to solve this, in a given sequence z, only a subsequence z_(>c) is selected for prediction, where c is called the cutting point. We consider only z_(>c) since it has the longest context in that sequence.
Moreover, another hyperparameter K is used such that, K ~ |z|/(|z|−c). And we select only 1/K tokens for prediction. For unselected tokens, their query representations aren’t computed, which saves speed and memory.
We compare this partial prediction to that of the BERT. BERT uses partial prediction because masking all the tokens doesn’t make any sense. XLNet does partial prediction because of the optimization difficulty. For example: let’s have a sequence: [Deep, Learning, is, great]. Say both BERT and XLNet opt to predict the tokens [Deep, Learning]. Also suppose that XLNet factorizes the sample as [is, great, Deep, Learning]. In this case,
BERT maximizes:
- L(BERT) = log p(Deep | is great) + log p(Learning | is great)
XLNet maximizes:
- L(XLNet) = log p(Deep | is great) + log p(Deep | Learning is great)
This clearly explains how XLNet captures more dependency i.e. between Deep and Learning. No doubt that BERT learns most of the dependencies; but XLNet learns more. Also, this is an example of the independence assumption in BERT which was covered in the previous section.
Taking Ideas from Transformer XL
Finally, a mention of the Transformer XL model from where XLNet borrows the ideas of relational encoding and the segment recurrence mechanism which enables Transformer XL to operate on very long sequences.
Fun Fact: Transformer XL can attend sequences that 80% longer than RNNs and 450% longer than vanilla Transformer and it is 1800+ times faster than vanilla Transformers during evaluation.
Conclusion
We’ve covered another state of the art model, XLNet, and have discussed the concept behind it.
XLNet’s code is open-sourced by the authors, you can find it here.
You can find the pre-trained weights and an easy to use API for the model architecture by huggingface transformers.
New: I have written a paper summary and critique for XLNet. You can take a look if interested: https://docs.google.com/document/d/1nePIW67OqW1HPrIkoXUB-N8hK2A07-3pnmtRVMQMKTA/edit?usp=sharing




