
Word2Vec Embeddings
Unraveling Speech with Wav2Vec Embeddings: Harnessing Deep Learning for Audio Representation
Introduction:
Word2Vec is a popular technique used in natural language processing (NLP) to learn dense vector representations of words from large text corpora. These vector representations, often referred to as word embeddings, capture semantic relationships between words and are used as input features for various NLP tasks. Word2Vec was introduced by Tomas Mikolov et al. at Google in 2013. The Word2Vec is an unsupervised model where you can give a corpus without any label information and the model can create dense word embeddings.
There are two main architectures for training Word2Vec embeddings:
- Continuous Bag of Words (CBOW):
- Skip-gram:
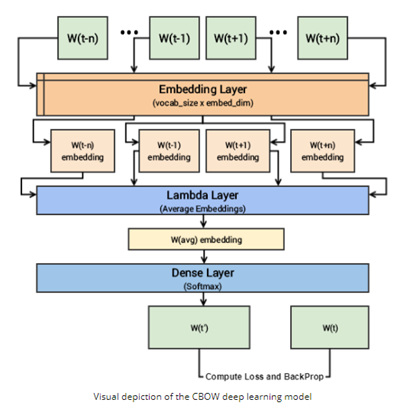
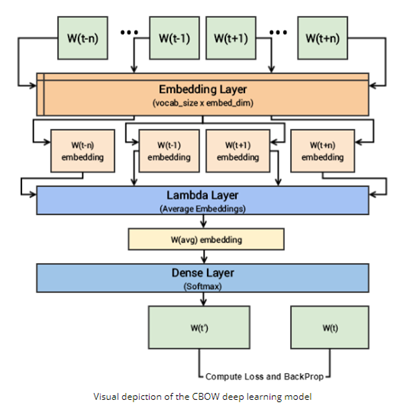
Continuous Bag of Words (CBOW):
- In the CBOW architecture, the model predicts the target word based on the context words surrounding it.
- It takes a fixed-size context window of words as input and tries to predict the target word in the middle of the window. Data is prepared as pairs of ([context words],word_to_predict)
eg, We will see an example of for sentence “Sachin Tendulkar, is regarded as the greatest batsman in the history of cricket”. Now context window size of 2, we will have pairs like ([Sachin, is],Tendulkar),([Tendulkar,regarded],is),([is, as],regarded),([regarded,the],as),([as,greatest],the),([the, batsmen],greatest),([greatest,in],batsmen),([batsmen,the],in),([in, history],the),([history,cricket],of)
Steps in training:
- the context words are passed as input to the embedding layer
- the word embeddings are then passed to a lambda layer, where we average out word embeddings
- We then pass these embeddings to a dense SoftMax layer that predicts our target word. We match this with our target word and compute the loss and then we perform backpropagation with each epoch to update the embedding layer in the process.
Source link: https://editor.analyticsvidhya.com/uploads/32272Picture3.png
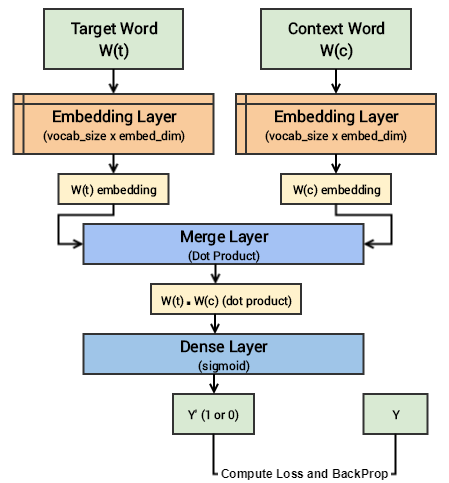
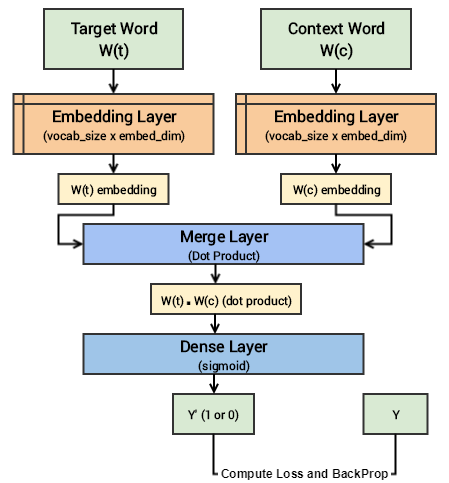
Skip-gram:
- In the Skip-gram architecture, the model predicts the context words given the target word.
- It takes a target word as input and tries to predict the context words within a fixed-size window around it.
Since the skip-gram model has to predict multiple words from a single given word, we feed the model pairs of (X, Y) where X is our input and Y is our label. This is done by creating positive input samples and negative input samples.
Positive Input sample = [(target,context),1]. Negative Input Sample = [(target,random),0].
Here 1 represents the positive sample while 0 represents the negative sample. This way the model is aware of contextual relevant words.
Steps in Model Training:
- Both the target and context word pairs are passed to individual embedding layers from which we get dense word embeddings for each of these two words.
- We then use a ‘merge layer’ to compute the dot product of these two embeddings and get the dot product value.
- This dot product value is then sent to a dense sigmoid layer that outputs either 0 or 1.
- The output is compared with the actual label and the loss is computed followed by
Source: https://cdn-images-1.readmedium.com/max/800/1*4Uil1zWWF5-jlt-FnRJgAQ.png
Code:
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
import nltk
nltk.download('punkt')
# Sample corpus (list of sentences)
corpus = [
"This is the first sentence.",
"This sentence is the second sentence.",
"And this is the third one.",
"Is this the first sentence?",
]
# Tokenize the corpus into words
tokenized_corpus = [word_tokenize(sentence.lower()) for sentence in corpus]
# Train Word2Vec model
model = Word2Vec(sentences=tokenized_corpus, vector_size=100, window=5, min_count=1, workers=4)
# Get word embeddings
word_embeddings = model.wv
# Get the embedding vector for a specific word
word = 'sentence'
embedding_vector = word_embeddings[word]
print("Word Embedding for '{}'".format(word))
print(embedding_vector)Word Embedding for 'sentence' [-5.3622725e-04 2.3643136e-04 5.1033497e-03 9.0092728e-03 -9.3029495e-03 -7.1168090e-03 6.4588725e-03 8.9729885e-03 -5.0154282e-03 -3.7633716e-03 7.3805046e-03 -1.5334714e-03 -4.5366134e-03 6.5540518e-03 -4.8601604e-03 -1.8160177e-03 2.8765798e-03 9.9187379e-04 -8.2852151e-03 -9.4488179e-03 7.3117660e-03 5.0702621e-03 6.7576934e-03 7.6286553e-04 6.3508903e-03 -3.4053659e-03 -9.4640139e-04 5.7685734e-03 -7.5216377e-03 -3.9361035e-03 -7.5115822e-03 -9.3004224e-04 9.5381187e-03 -7.3191668e-03 -2.3337686e-03 -1.9377411e-03 8.0774371e-03 -5.9308959e-03 4.5162440e-05 -4.7537340e-03 -9.6035507e-03 5.0072931e-03 -8.7595852e-03 -4.3918253e-03 -3.5099984e-05 -2.9618145e-04 -7.6612402e-03 9.6147433e-03 4.9820580e-03 9.2331432e-03 -8.1579173e-03 4.4957981e-03 -4.1370760e-03 8.2453608e-04 8.4986202e-03 -4.4621765e-03 4.5175003e-03 -6.7869602e-03 -3.5484887e-03 9.3985079e-03 -1.5776526e-03 3.2137157e-04 -4.1406299e-03 -7.6826881e-03 -1.5080082e-03 2.4697948e-03 -8.8802696e-04 5.5336617e-03 -2.7429771e-03 2.2600652e-03 5.4557943e-03 8.3459532e-03 -1.4537406e-03 -9.2081428e-03 4.3705525e-03 5.7178497e-04 7.4419081e-03 -8.1328274e-04 -2.6384138e-03 -8.7530091e-03 -8.5655687e-04 2.8265631e-03 5.4014288e-03 7.0526563e-03 -5.7031214e-03 1.8588197e-03 6.0888636e-03 -4.7980510e-03 -3.1072604e-03 6.7976294e-03 1.6314756e-03 1.8991709e-04 3.4736372e-03 2.1777749e-04 9.6188262e-03 5.0606038e-03 -8.9173904e-03 -7.0415605e-03 9.0145587e-04 6.3925339e-03]
CBOW is often faster to train and works well with smaller datasets. Skip-gram tends to perform better on larger datasets and can capture more fine-grained semantic relationships. Both CBOW and Skip-gram use shallow neural networks with a single hidden layer to learn word embeddings. During training, the model adjusts the vector representations of words based on their co-occurrence patterns in the input text. Words that appear in similar contexts will have similar vector representations, while words with different meanings or contexts will have dissimilar representations.
Once trained, Word2Vec embeddings can be used as features in various NLP tasks such as text classification, sentiment analysis, machine translation, and more. They provide a dense and semantically meaningful representation of words, enabling better performance on downstream tasks compared to traditional sparse representations like one-hot encoding or TF-IDF. Additionally, Word2Vec embeddings can capture relationships between words such as similarity, analogy, and syntactic/semantic properties



{kind=link}
{kind=link}