
Word2Vec (CBOW, Skip-gram) In Depth
- Word2Vec is an important model for natural language processing (NLP) developed by researchers at Google.
- Word2Vec is a group of related models used to produce word embeddings, which are dense vector representations of words in a continuous vector space.
- A two-layer network to generate word embedding given a text corpus.
- These embeddings capture semantic relationships between words based on their usage in a large corpus of text.
Word Embeddings: Word embeddings are fixed-size, dense vectors representing words. They capture semantic meaning in such a way that similar words have similar vectors. For example, “king” and “queen” might have vectors that are close to each other.
Architecture
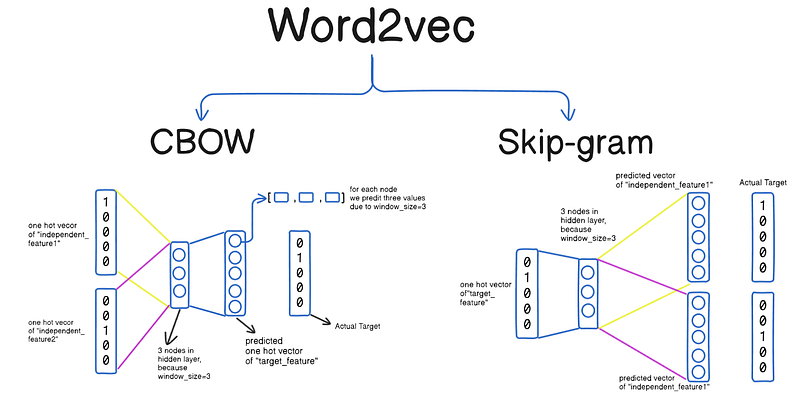
Word2Vec has two main architectures for generating word embeddings:
- Continuous Bag-of-Words (CBOW)
- Skip-Gram
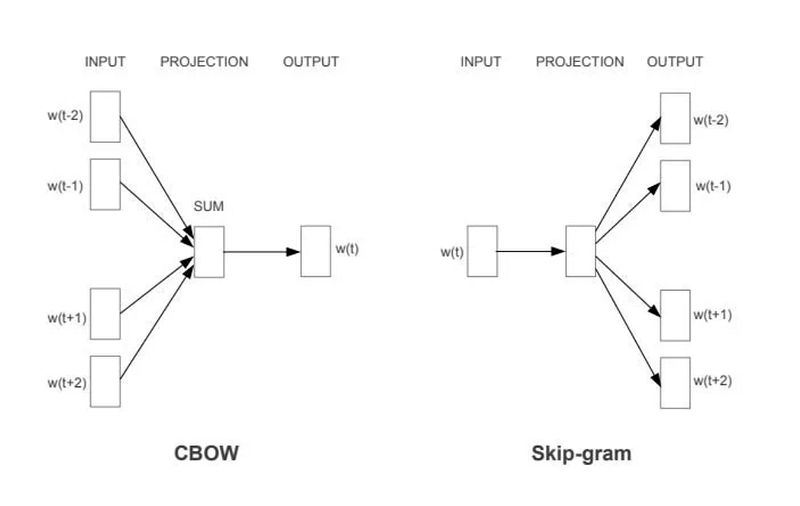
1. Continuous Bag-of-Words (CBOW)
- Predict the target word (center word) from the surrounding context words.
- The model averages the vectors of context words and uses this average to predict the target word.
- Faster to train since it predicts only one word from multiple context words.
Practical Example:
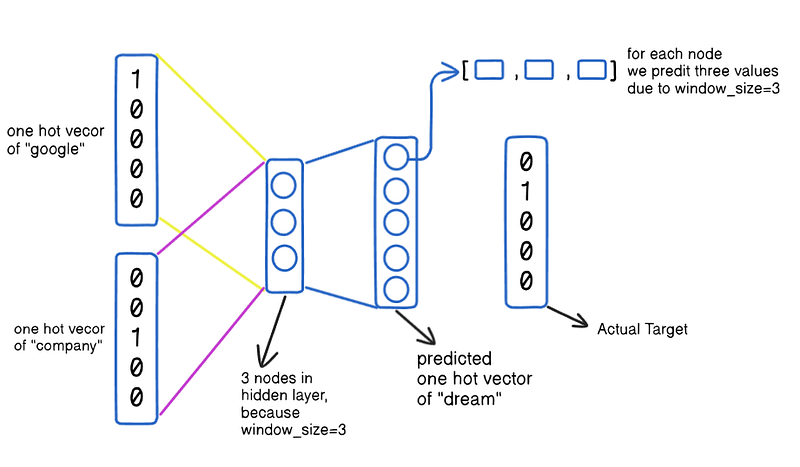
- For simplicity, imagine we got these five words: “google dream company software engineer”
1st Iteration:
- Select the window size (window_size=3).
- The target is to predict the center word from context words (Surrounding words).
- We create the dataset where the context word is independent features and the center word is our output.

- Convert it into one hot encoding.

- Next step, we pass it to the Neural Network
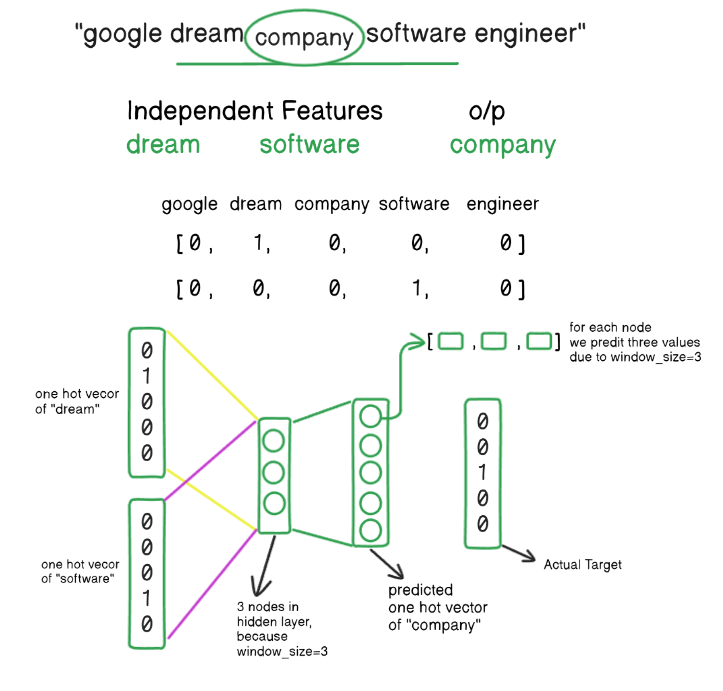
2nd Iteration:
- We go for the next three words
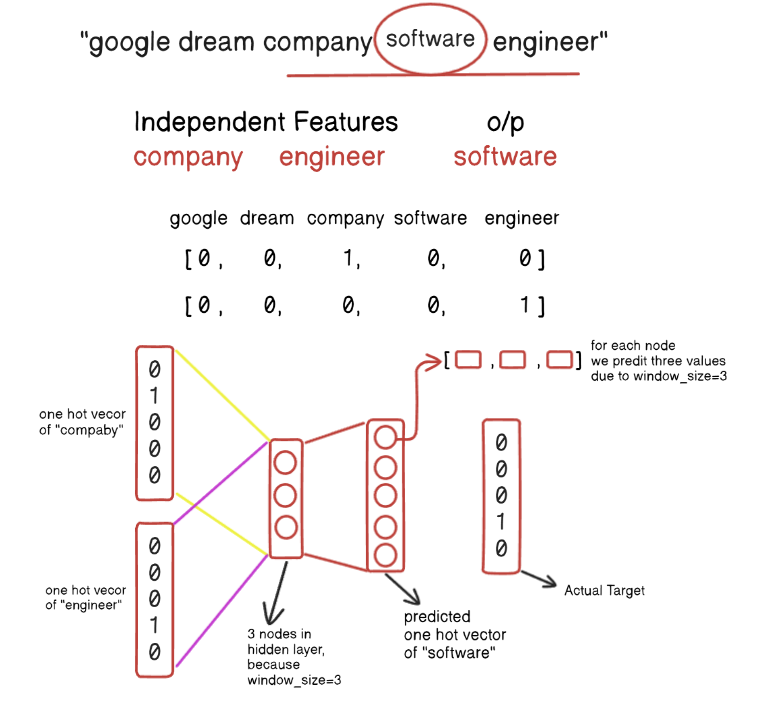
3rd Iteration:
- Finally, for the last three words the process is shown below:
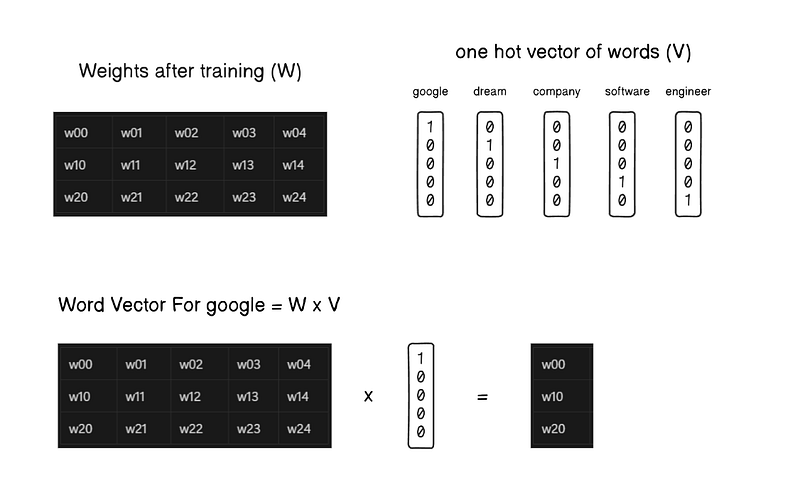
Getting Word Embeddings:
- below is shown the process of getting word embeddings:
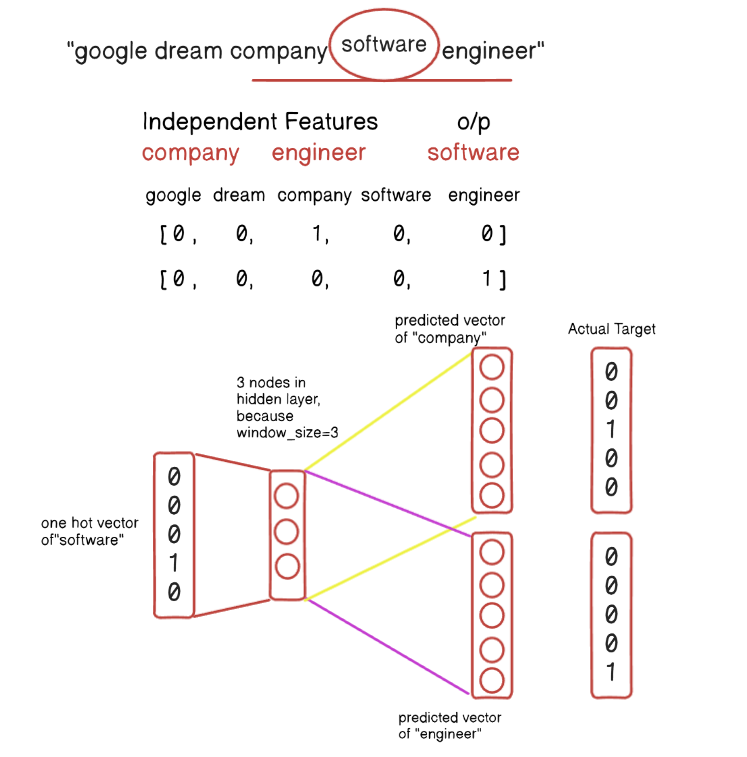
Skip-Gram
- Predict the surrounding context words given a target word.
- The model takes the target word and tries to predict each of the context words within a window.
- Performs better on smaller datasets and can capture more complex relationships between words.
Practical Example:
- We will use the above example:
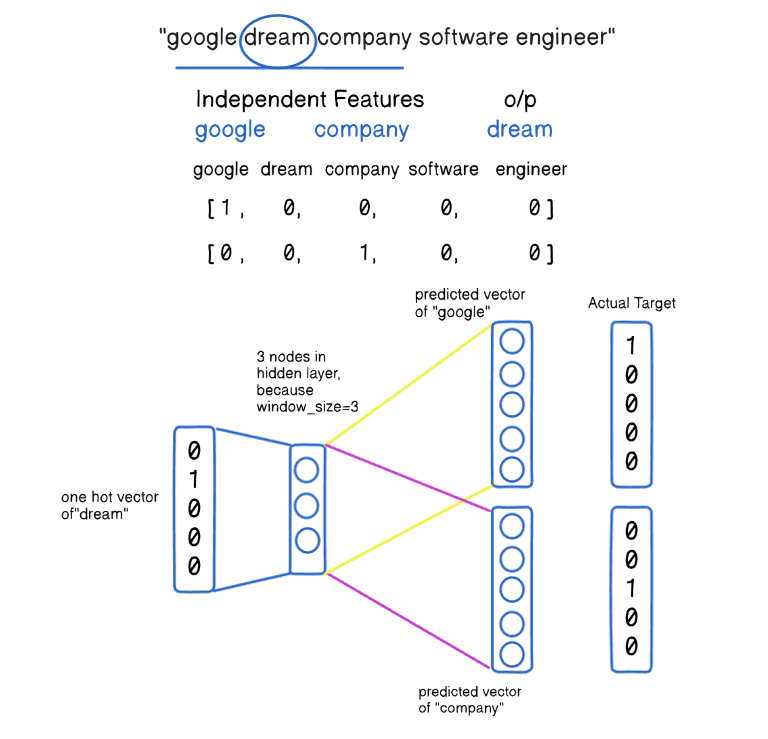
1st Iteration:
- Here, our input is our output value, and we predict the surrounding words.
2nd Iteration:
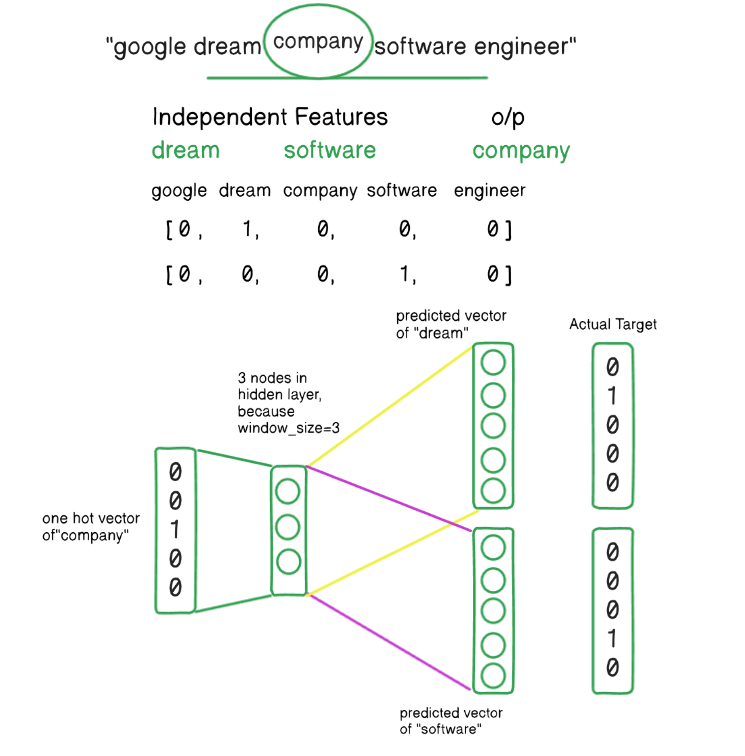
3rd Iteration:
Extensions and Alternatives
Several models build on or improve Word2Vec:
- GloVe (Global Vectors for Word Representation): Combines global word co-occurrence statistics with local context-based learning.
- FastText: Extends Word2Vec by representing words as n-grams of characters, improving representations for rare words.
- ELMo (Embeddings from Language Models): Uses deep, contextualized word representations.
- BERT (Bidirectional Encoder Representations from Transformers): Uses transformers for contextualized word embeddings, considering both left and right context.
Applications
- Semantic Similarity: Measuring similarity between words.
- Text Classification: Improving feature representation for classification tasks.
- Machine Translation: Enhancing translation quality by providing better word embeddings.
- Information Retrieval: Improving search results by understanding word semantics.
- Recommendation Systems: Enhancing recommendations by understanding user preferences and item descriptions.
Limitations
- Context Independence: It doesn’t consider the order of words or their syntactic roles.
- Out-of-Vocabulary Words: It cannot handle words that were not present in the training corpus.
- Fixed Embedding Size: All words are represented by fixed-size vectors, regardless of their frequency or importance.




