
Word Mover’s Distance as a Linear Programming Problem
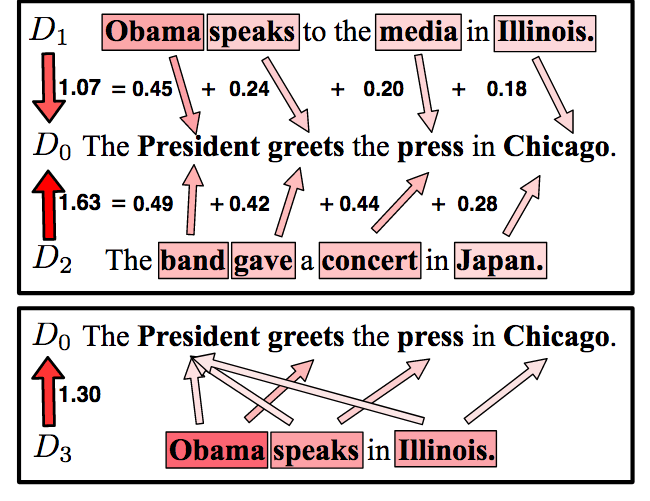
Much about the use of word-embedding models such as Word2Vec and GloVe have been covered. However, how to measure the similarity between phrases or documents? One natural choice is the cosine similarity, as I have toyed with in a previous post. However, it smoothed out the influence of each word. Two years ago, a group in Washington University in St. Louis proposed the Word Mover’s Distance (WMD) in a PMLR paper that captures the relations between words, not simply by distance, but also the “transportation” from one phrase to another conveyed by each word. This Word Mover’s Distance (WMD) can be seen as a special case of Earth Mover’s Distance (EMD), or Wasserstein distance, the one people talked about in Wasserstein GAN. This is better than bag-of-words (BOW) model in a way that the word vectors capture the semantic similarities between words.
Word Mover’s Distance (WMD)
The formulation of WMD is beautiful. Consider the embedded word vectors
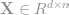
, where d is the dimension of the embeddings, and n is the number of words. For each phrase, there is a normalized BOW vector
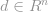
, and
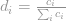
, where i’s denote the word tokens. The distance between words are the Euclidean distance of their embedded word vectors, denoted by
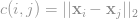
, where i and j denote word tokens. The document distance, which is WMD here, is defined by
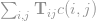
, where T is a n times n matrix. Each element
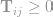
denote how nuch of word i in the first document (denoted by d) travels to word j in the new document (denoted by d’).
Then the problem becomes the minimization of the document distance, or the WMD, and is formulated as:
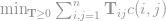
given the constraints:
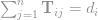
, and
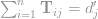
This is essentially a simplified case of the Earth Mover’s distance (EMD), or the Wasserstein distance. (See the review by Gibbs and Su.)
Using PuLP
The WMD is essentially a linear optimization problem. There are many optimization packages on the market, and my stance is that, for those common ones, there are no packages that are superior than others. In my job, I happened to handle a missing data problem, in turn becoming a non-linear optimization problem with linear constraints, and I chose limSolve, after I shop around. But I actually like a lot of other packages too. For WMD problem, I first tried out cvxopt first, which should actually solve the exact same problem, but the indexing is hard to maintain. Because I am dealing with words, it is good to have a direct hash map, or a dictionary. I can use the Dictionary class in gensim. But I later found out I should use PuLP, as it allows indices with words as a hash map (dict in Python), and WMD is a linear programming problem, making PuLP is a perfect choice, considering code efficiency.
An example of using PuLP can be demonstrated by the British 1997 UG Exam, as in the first problem of this link, with the Jupyter Notebook demonstrating this.
Implementation of WMD using PuLP
The demonstration can be found in the Jupyter Notebook.
Load the necessary packages:
from itertools import product
from collections import defaultdict
import numpy as np
from scipy.spatial.distance import euclidean
import pulp
import gensimThen define the functions the gives the BOW document vectors:
def tokens_to_fracdict(tokens):
cntdict = defaultdict(lambda : 0)
for token in tokens:
cntdict[token] += 1
totalcnt = sum(cntdict.values())
return {token: float(cnt)/totalcnt for token, cnt in cntdict.items()}Then implement the core calculation. Note that PuLP is actually a symbolic computing package. This function return a pulp.LpProblem class:
def word_mover_distance_probspec(first_sent_tokens, second_sent_tokens, wvmodel, lpFile=None):
all_tokens = list(set(first_sent_tokens+second_sent_tokens))
wordvecs = {token: wvmodel[token] for token in all_tokens}
first_sent_buckets = tokens_to_fracdict(first_sent_tokens)
second_sent_buckets = tokens_to_fracdict(second_sent_tokens)
T = pulp.LpVariable.dicts('T_matrix', list(product(all_tokens, all_tokens)), lowBound=0)
prob = pulp.LpProblem('WMD', sense=pulp.LpMinimize)
prob += pulp.lpSum([T[token1, token2]*euclidean(wordvecs[token1], wordvecs[token2])
for token1, token2 in product(all_tokens, all_tokens)])
for token2 in second_sent_buckets:
prob += pulp.lpSum([T[token1, token2] for token1 in first_sent_buckets])==second_sent_buckets[token2]
for token1 in first_sent_buckets:
prob += pulp.lpSum([T[token1, token2] for token2 in second_sent_buckets])==first_sent_buckets[token1]
if lpFile!=None:
prob.writeLP(lpFile)
prob.solve()
return probTo extract the value, just run pulp.value(prob.objective)
We use Google Word2Vec. Refer the
matrices in the Jupyter Notebook. Running this by a few examples:
- document1 = President, talk, Chicago document2 = President, speech, Illinois WMD = 2.88587622936
- document1 = physician, assistant document2 = doctor WMD = 2.8760048151
- document1 = physician, assistant document2 = doctor, assistant WMD = 1.00465738773 (compare with example 2!)
- document1 = doctors, assistant document2 = doctor, assistant WMD = 1.02825379372 (compare with example 3!)
- document1 = doctor, assistant document2 = doctor, assistant WMD = 0.0 (totally identical; compare with example 3!)
There are more examples in the notebook.
Conclusion
WMD is a good metric comparing two documents or sentences, by capturing the semantic meanings of the words. It is more powerful than BOW model as it captures the meaning similarities; it is more powerful than the cosine distance between average word vectors, as the transfer of meaning using words from one document to another is considered. But it is not immune to the problem of misspelling.
This algorithm works well for short texts. However, when the documents become large, this formulation will be computationally expensive. The author actually suggested a few modifications, such as the removal of constraints, and word centroid distances.
Example codes can be found in my Github repository: stephenhky/PyWMD.
P.S.:
- Original post: https://datawarrior.wordpress.com/2017/08/16/word-movers-distance-as-a-linear-programming-problem/
- This same code has been implemented in the Python package shorttext. Tutorial: http://shorttext.readthedocs.io/en/latest/tutorial_metrics.html
- Feature image adapted from the original paper by Kusner et. al.
References:
- Matt Kusner, Yu Sun, Nicholas Kolkin, Kilian Weinberger, “From Word Embeddings To Document Distances,” Proceedings of the 32nd International Conference on Machine Learning, PMLR 37:957–966 (2015). [PMLR]
- Github: mkusner/wmd. [Github]
- Kwan-Yuet Ho, “Toying with Word2Vec,” Everything About Data Analytics, WordPress (2015). [WordPress]
- Kwan-Yuet Ho, “On Wasserstein GAN,”Everything About Data Analytics, WordPress (2017). [WordPress]
- Martin Arjovsky, Soumith Chintala, Léon Bottou, “Wasserstein GAN,” arXiv:1701.07875 (2017). [arXiv]
- Alison L. Gibbs, Francis Edward Su, “On Choosing and Bounding Probability Metrics,” arXiv:math/0209021 (2002) [arXiv]
- cvxopt: Python Software for Convex Optimization. [HTML]
- gensim: Topic Modeling for Humans. [HTML]
- PuLP: Optimization for Python. [PythonHosted]
- Demonstration of PuLP: Github: stephenhky/PyWMD. [Jupyter]
- Implemenation of WMD: Github: stephenhky/PyWMD. [Jupyter]
- Github: stephenhky/PyWMD. [Github]