
Word Embeddings: CBOW and Skip Gram
Since the advent of transformers, NLP gained a lot of traction, and a wide variety of tasks are already solved by GPT-3 and other big transformers-based models. But today we are going to take a step back and learn about word embeddings. In this blog, we are primarily going to look into CBOW or Continuous Bag of Words and Skip Grams. These embeddings are super important for the conversion of text into numbers. So, without further ado, let’s dive into the basics of NLP.

What is word embeddings and why do we need them?
A word embedding is a learned representation for text where words that have the same meaning have a similar representation. In other terms, word embeddings are just a way to convert text into relevant numbers. The reason why we need to do this is that computers can’t process text thus every character or word should be converted to a series of numbers. Another reason why we need embeddings is to solve the issue of variable length of sentences in sentence embeddings. The idea behind both the word and sentence embedding is exactly the same.
Word embeddings can be thought of as an alternate to one-hot encoding along with dimensionality reduction.
The easiest way to convert words into vectors is to use one-hot encoding using a dictionary. This creates a problem as the dictionary is often very large in size thus making it almost impractical to use. Let’s see how can we convert sentences or words into vectors using some other techniques.
Continuous Bag of words or CBOW
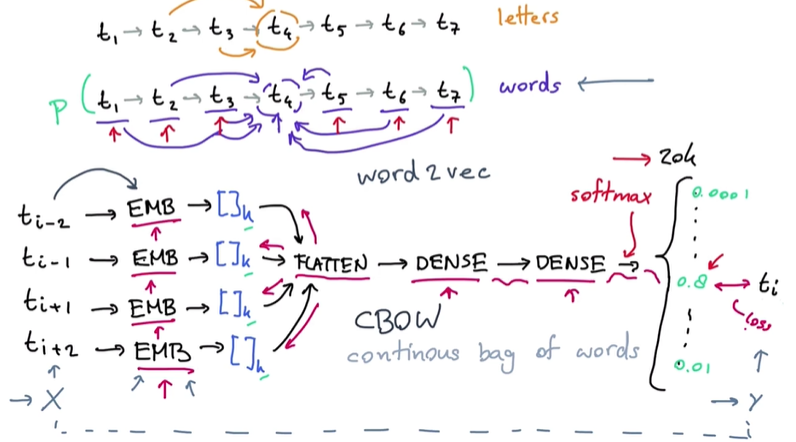
One very important thing during the embedding of words is that words without context are pretty much useless. Let’s look at the following sentence “I’m going to the bank” now if we carefully analyze this sentence, we can say that this is an ambiguous sentence. We don’t know whether the sentence talks about the river bank or the financial bank. Capturing this context is of utmost importance if we expect our model to perform well on some natural language tasks.
Let’s see how the embeddings are learned using the CBOW.
- The entire sentence is tokenized and converted into a set of numbers.
- Pass k-tokens distributed around the token tᵢ to an embedding layer. K is a hyperparameter here.
- The embedding layer in turn will produce k-vectors of the same size (we can choose the size of the vector produced). Initially, each vector contains random values that are updated later on.
- After flattening and passing the embeddings through several dense layers, a softmax layer is applied in the final layer. The last layer has the size of the vocabulary (in our case, it’s 20k).
- Finally, we will get a vector that has a very high value for the i_th position and very small values for all other positions, basically, the resulting vector will look similar to a one-hot-encoded vector.
- In order to minimize the loss, embedding vectors will be updated using backpropagation and thus we will get out the final embeddings that have captured the contextual information. NOTE: Even though the final layer is of the size of vocabulary, for embeddings we can choose any size we want.
Skip Grams

The idea of skip-gram is also very similar to CBOW but with one major difference. Sometimes, it’s possible that the first token has almost zero correlation with its surrounding tokens but has maximum correlation or context with the last token, in such cases, it’s better to use Skip-gram. In the above diagram, we take one token and try to find its correlation with other context words. In our case, we have one token- Google and three context words- really, office, Berlin. Thus we will try to minimize the error in the softmax layer such that these 3 words have high value and the rest of them has values close to 0. The vector produced during the training is a 20k-sized vector. And in this optimization, we get an embedding vector that has captured Google’s corelation with the three mentioned context words. Again we can choose the size of the embedding vector according to the level of dimensionality reduction we need.
Thanks for giving your time and if you think that this blog added something to your knowledge base, please consider following the AIGuys Blog, and if you are interested to become a writer at AIGuys you can follow this link.




