
{kind=link}
Wide and Narrow dependencies in Apache Spark

Indeed, not all transformations are born equal. Some are more expensive than others and if you shuffling data all around you cluster network, then you performance you surely take the hit! In order to understand why some transformations can have this impact into the execution time, we need to understand the basic difference between narrow and long dependencies in Apache Spark.
Computations are represented in Spark as a DAG(Directed Acyclic Graph) — officially described as a lineage graph — over RDDs, which represent data distributed across different nodes.
I won’t dive into details about RDDs here (Jacek Laskowsk has a nicely written description abou them!) but it is good to understand that RDDs are actually maid up of four main parts:
- Partitions
- Dependencies (that models the relationships a RDD and its partitions and the partition which it was derived from)
- Function: for comping the dataset based on its parent RDD
- Metadata about its partitioning scheme and data placement
Therefore, each partition can depend on one or more partitions from its parent RDD.
Narrow dependencies
When each partition at the parent RDD is used by at most one partition of the child RDD, then we have a narrow dependency. Computations of transformations with this kind of dependency are rather fast as they do not require any data shuffling over the cluster network. In addition, optimizations such as pipelining are also possible.
Example: map , filter and union transformations
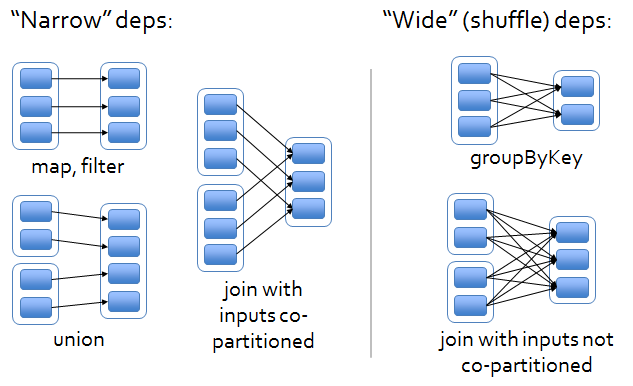
Wide dependencies
When each partition of the parent RDD may be depended on by multiple child partitions (wide dependency), then the computation speed might be significantly affected as we might need to shuffle data around different nodes when creating new partitions.
Example: groupByKey operations and join operations whose inputs are not co-partitioned
When designing algorithms, it is great to bear in mind those definitions in order to always try to minimize the number of transformations which leads to RDDs with wide dependencies and data shuffling.
If you need help if your Spark application, get in touch. Besides Twitter, you can also reach me on StackOverflow.