
Why Your Microservices Architecture Needs Aggregates
What are Aggregates and how can they help you in the long run?

Microservices are all about organizing our stuff into discreet, well-defined units.
Whereas our legacy monolithic generally meant that every engineer in the organization worked on every part of the application, and every business entity had a tight coupling with every other entity, microservices allow us to move in a different direction.
Engineering teams should focus exclusively on their own business domains. And business entities should be coupled only with other entities in the same domain.
Drawing these boundaries, however, is easier said than done. So, new patterns have emerged, and older ones rediscovered. The bounded context, for example, is a recently-popularized pattern that guides us in organizing our engineering teams and business domains at a high-level.
Likewise, the Aggregate pattern is one that helps us to organize our data at a lower level. This pattern was initially defined as a way to transactionally group changes to related entities.
It has also come to provide us with a blueprint for breaking apart our monolithic data schema, essentially grouping highly cohesive entities into a single, atomic unit.
And its benefits go way beyond that.
Interestingly, the Aggregate pattern doesn’t seem to be as well-known, widely-discussed, or commonly-implemented as other distributed software design patterns. But I’ve found it to be a fundamental building block when constructing microservices.
Designing with Aggregates upfront helps us to avoid the sorts of things, such as accidental dependencies or leaky references between entities, that typically dog us as we try to scale.
First, let’s look at what Aggregates are.
Aggregates
The Aggregate is a design pattern popularized by Eric Evans in his tome Domain-Driven Design, a book that, while not explicitly written to discuss microservice architectures or distributed systems, has nonetheless emerged as a guide on those topics.
An Aggregate defines a self-contained grouping of entities, which is treated as a single, atomic unit. A change to any of the entities is considered to be a change to the entire Aggregate. Every Aggregate is made up of the following:
- A boundary. This is a clear delineation between the entities that are a part of the Aggregate and those that are not.
- A number of entities. The entities are the business objects contained within the group.
- A root. Every Aggregate exposes exactly one of its entities to the outside world. Objects outside of the Aggregate can only reference the Aggregate root; they cannot directly address any other entity within the Aggregate.
The diagram below depicts these:
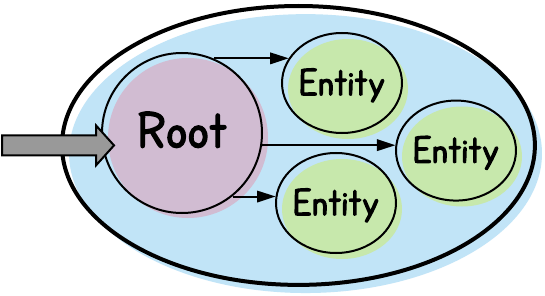
The thick oval represents the boundary around the aggregate. Inside the aggregate are the Aggregate root (represented by the purple circle) as well as additional entities (represented by the green circles).
The root is the only entity that is directly accessible from outside of the Aggregate. As such, only the root can reference the other entities within the Aggregate.
Aggregate roots
In a way, the roots serve as a representative of the Aggregate to the outside world. So, in determining which entity should be the root, we need to choose the most qualified one.
Fortunately, the choice will usually be obvious. Many Aggregates will have a clear, primary entity, to which a number of supporting entities are attached.
Let’s modify our generic example from above to show a specific — albeit simplified — example: a User Aggregate:
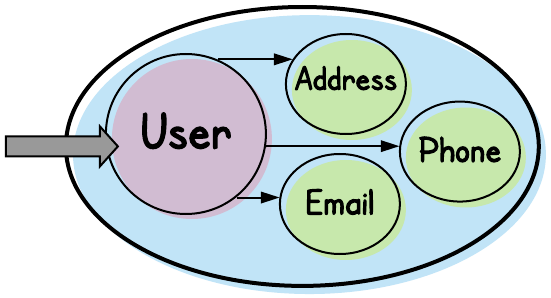
Notice how our Aggregate and its root entity are both called “User”. Our User entity probably consists of attributes such as first-name and last-name, gender and date-of-birth, maybe a national identifier (social-security-number or social-insurance-number), and a smattering of other scalar fields.
The other entities depicted here represent one-to-many relationships between a User and its contact information: Email (address), Phone (number), and (mailing) Address.
Beyond our simple depiction above, we might also have other entities in our Aggregate (for example, entities that represent user preferences).
That the User entity will serve as our Aggregate’s root should be obvious. Identical names aside, the User entity contains the core information about users.
Moreover, it’s the entity from which all other entities in the Aggregate emanate. If, say, a Phone was to be removed, the Aggregate itself would still remain.
In this sense, the Phone itself is meaningless outside of the context of the User. By contrast, if the User entity was to be removed, then the rest of the Aggregate — including all associated Phones — would become meaningless, orphans floating aimlessly around our microservices architecture.
The User entity, then, is the only one of the entities in the Aggregate that is directly addressable externally. Using ReST paths to exemplify, this means that we can provide a path like this:
/users/{user-identifier}But never like this:
/users/phones/{phone-identifier}Other Aggregates can store references to Users. Our Order Aggregate, for example, might store the identifier of the User who initiated each Order. For this reason, every User must be assigned a globally- or universally-unique identifier.
Value objects
By contrast, the other entities need only have local identifiers; that is, identifiers by which an Aggregate can disambiguate its own entities. One User’s Phones, for example, might simply be identified as 1, 2, and 3.
This is because, again, the Phone has no meaning outside of the Aggregate itself. No other Aggregate would ever ask simply for Phone 2. It might, however, retrieve Phone 2 of User b4664e12–2b5b-47c8-b349–41e81848758f.
Even this, however, should happen within a limited scope; other Aggregates should never permanently retain a reference to the user’s phone number.
Back to our ReST example, we could consider it acceptable to reference a phone number thusly:
/users/{user-identifier}/phones/{phone-identifier}However, many of these supporting entities will be value objects; that is, objects whose identities are based on their values, not on any reference.
Consider Email. We may decide to assign a numeric ID to each email address, but in reality, [email protected] itself can be considered the entity’s identity. If that string changes, then it becomes an entirely new email address.
The same is true of Phones (it’s the unformatted digits that make up the identity of a phone number). It might also be true of (mailing) Addresses, although that can become a little tricky, given that the same address can be written in multiple ways (e.g. 34 N. Main St. versus 34 North Main Street).
In reality, to treat an Address as a value object, we’d need its identity to be represented by some canonicalized form of the address components.
So, returning to our ReST example one more time, we might dispense with IDs altogether for our contact-info entities, and simple access them as a group, like so:
/users/{user-identifier}/phonesNote that there is no universal answer here. It all depends on how we plan to treat our entities.
Aggregates, transactional boundaries, and invariants
Earlier, we’d mentioned that an Aggregate is treated as an atomic unit. A change to any contained entity or entities is considered to be a change to the Aggregate as a whole.
Thus, the Aggregate defines the transactional boundaries upon which any changes to the contained entities are performed.
What do we mean by this? Often, we establish rules that govern what must happen when we modify an entity. In many cases, if we modify an entity of one type a certain way, then another entity must also be modified.
Or, the modification of a given entity might only be allowed under specific circumstances.
We call such rules invariants. Any invariant must reside solely within the context of an Aggregate. If a change to entity X requires a change to entity Y, then entity X and entity Y must both be contained within the same Aggregate.
Likewise, if an edit to entity X might be rejected based on the calculation of entities Y and Z, then all three entities must be contained within the same Aggregate.
Or, more accurately, if an invariant is spread across Aggregates, then we cannot guarantee that the invariant can consistently be enforced (in fact, we can almost guarantee the opposite).
Let’s illustrate this with our User Aggregate example. Let’s assume that we allow our users to indicate their single, preferred method of communication. This may be a particular email address, phone number, or even mailing address.
So, we attach a “best-contact” boolean field to each of the three contact-info entity types. If a user indicates an email address as their best-contact, and later changes their best-contact to be one of their phone numbers, then two things must happen:
- The email address’
best-contactfield must be set tofalse. - The phone number’s
best-contactfield must be set totrue.
Clearly, both the Email and Phone entities must belong to the User Aggregate. If they each belonged to a separate Aggregate, then the “update best contact” action could not be performed within a single transaction; instead, two separate calls — one to each Aggregate — would need to be made.
Note that in using the term “transaction,” I don’t necessarily mean a database transaction. In many cases, changes to entities are performed in the database. But they might also be done in-memory, or via any other mechanism.
The important part is that all of the required changes occur from a single invocation upon the Aggregate. So, implicit here is that we define our APIs accordingly.
In our example, we wouldn’t want to require that our callers update the best-contact field explicitly; the following ReST path would be a bad idea:
PUT /users/{user-identifier}/phones/{id}/isBestContact // boolean passed in the bodyInstead, we’d want to provide something like the following:
PUT /users/{user-identifier}/bestContact // ID passed in the bodyIn this manner, we can think of Aggregates and invariants as representing the concept of high-cohesion: elements that tend to change together should be grouped together.
How to Define Aggregates
Properly defining our Aggregates helps us to break out of our legacy data models in which boundaries between major entities are grey (at best) or non-existent (at worst). And it helps us to group together entities that need to change in tandem.
But… how do we define our Aggregates? There are a few approaches to take, but they would all follow this basic process:
Start by identifying the major entities in your system
The first bit requires a mix of business knowledge and common sense. We start by identifying the high-level entities that are fundamental parts of our business domain.
Odds are, phone numbers are not pivotal entities in our system, but users (or whatever our organization calls them) are. Other examples (depending on our business) might be:
- Orders
- Products (most likely, our organization would define entities that represent the product we offer, such as Car, Book, AudioTrack, WaterBottle, etc.)
- Ledgers
- Inventory
If we find ourselves having trouble determining whether a given entity is “high level” enough to represent an Aggregate, we might ask ourselves whether the entity warrants a global identity.
Do we want to globally distinguish a given instance of that entity from all others, even those with identical values? Or do we only care about the values of the entity?
Once we’ve identified the key entities in our system, we’ll have identified likely candidates for the root entities of Aggregates. We’ll then want to identify — for each root entity — the other entities that are closely associated with the root entities.
In doing so, we should keep in mind things like:
- The other entities will generally be objects with no meaning without the root entity.
- In addition, the other entities will generally be value objects (as described above)
- As we are identifying the entities that belong to an Aggregate, we should look for invariants — rules that govern the interaction of different entities. We should strive to group all entities involved in an invariant in the same Aggregate.
Some Aggregates may seem obvious and will form naturally (our User example typically being one such example.) Others might not be as straightforward.
Let’s take, as an example, two candidates: Orders and Order Items. Orders would represent an overall purchase that a customer has made online. An Order would be made up of Order Items, each of which represents a specific product purchase as part of the Order.
Undoubtedly, we would want to treat Orders as Aggregates. We would want to track any given Order that has been placed, and query it at any point to examine its components.
But what about an Order Item? Should we consider an Order Item to be its own Aggregate? Depending on our design, an Order Item might group together a number of other entities. And it could be that other Aggregates might want to store references of Order Items.
Conversely, an Order might have invariants that are related to its Order Items. Perhaps the total price of an order needs to be recalculated every time an Order Item is added.
Or maybe a limit to the number or types of items being purchased must be enforced. This suggests that Order should be an Aggregate that encompasses OrderItems.
There’s no magic answer. It depends on our business. Often we’ll go through several iterations, working through various use cases, before we identify our Aggregate roots.
Why Aggregates?
We’ve looked in-depth at what Aggregates are, and explored ways to identify our Aggregates. Clearly, it takes some up-front effort to design our Aggregates. So, why should we care in the first place?
When defining the pattern in Domain-Driven Design, Evans focuses almost exclusively on the Aggregate as a mechanism for transactional enforcement of invariants.
But this pattern — in which we identify atomic collections of entities with a single externally-accessible reference — becomes useful in many other aspects of our microservices architecture.
In addition to providing that enforcement of invariants, Aggregates help us to avoid later problems caused by things such as:
- Unwanted dependencies between entities.
- Leaky object references.
- Lack of clear boundary around groups of data.
Let’s look at some examples of these issues, and how Aggregates would have helped.
Microservice and data schema design
Let’s take a look at a typical monolithic database. Typically, over the years, we’ll have developed a large database schema, replete with foreign key references throughout.
Starting at any arbitrary table and tracing all of the FK references to and from that table, we’d likely find ourselves traversing the entire schema.
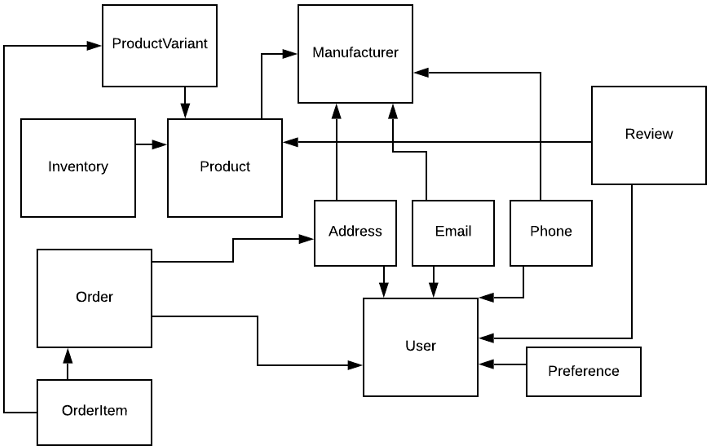
Even with a monolithic codebase, this doesn’t smell quite right.
For example, when making a database call to retrieve an Order, how much data should be returned? Certainly the Order details such as status, ID, and ordered-date.
But should we return all of the Order Items? The addresses where the item was shipped from and to? How about the User objects representing the order-placer and recipient? If so, how much data should come along with those Users?
As we move towards microservices, we’ll be breaking apart our monolithic data schema as we break apart our monolith codebase. This will likely be the most difficult task that we face as we get started.
Fortunately, thinking in terms of Aggregates provides us with a blueprint, and solid guidelines, for designing our data microservices and their associated database schemas.
Rather than arbitrarily drawing lines, and debating which objects “feel like” they belong together, the Aggregate pattern tells us to identify:
- Our root entities.
- Value objects that would be attached to our root entities.
- Invariants that are required to maintain data consistency across related entities.
While it will still take work, and often many iterations, to settle on our Aggregates, we’ll have a guiding light to direct us. And we can be much more confident that we’ve gotten it right, once we’ve formed our Aggregates.
Sharding
Most databases can handle an enormous amount of traffic. But even the most highly performant database can only handle so much. When we get to the point where our data volume has gotten too much for our database, we have a few options.
One common option, sharding, describes a way to horizontally scale our databases. When sharding our database, we are effectively creating multiple copies of our schema, and dividing our data across those copies.
So, for example, if we create four shards, then each shard would store approximately one-quarter of our data. The schema would be the same across the shards — each one would consist of the same tables, foreign keys, and other constraints, etc.
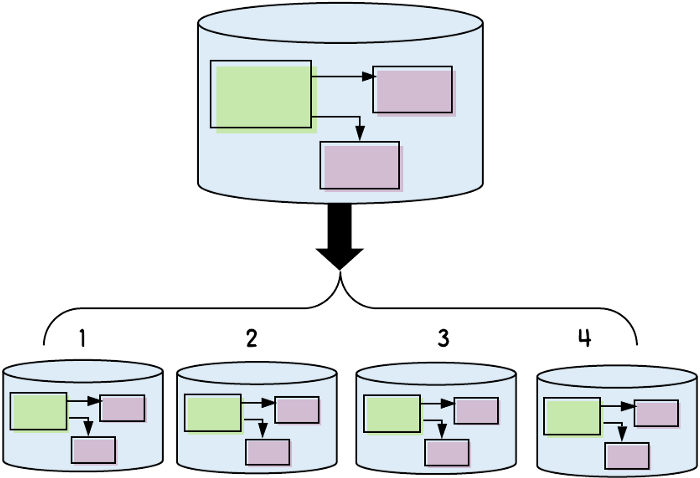
Critical to effective sharding is a sharding key. Effectively, a sharding key is a common identifier that is run through a hashing or modulus function to determine which shard it belongs to.
For example, if we’re attempting to update a user, we can take that user’s ID, hash it, and mod it by four (assuming four shards) to determine in which shard we can find the user.
Now, if we imagine a typical monolithic database schema, this might seem like an impossible task.
Why? Well, in our monolithic schema, we will likely have a number of foreign key relationships. For example, we might have a foreign key from the ORDER table to the USER table (to represent the user who placed the order).
Now, we might be able to easily determine where to find a given USER record with an ID of 12345 (12345 % 4 = 1, so that USER record would be found in Shard 1).
But what if a foreign key to that USER record was held by an ORDER record with an ID of 6543? 6543 % 4 = 3, so that ORDER record would be found in Shard 3. Given the foreign key relationship, then, this would be impossible to implement.
While this is a clear example from a monolithic database, we could just as easily paint ourselves into a corner with a microservice’s data schema.
Imagine that we’ve created a User service in which — much like our previous examples — a User entity is associated with 0..n email addresses, mailing addresses, and phone numbers.
The underlying data schema would then look like the following:
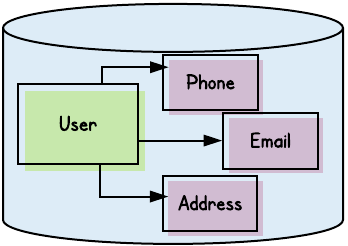
Now, let’s pretend that we’d eschewed the idea of Aggregates when we built out this microservice. Instead, we’d provided endpoints that allow direct access to all entities, like so:
GET /users/{user-id}
GET /users/phones/{phone-id}
GET /users/emails/{email-id}
GET /users/emails/{email-id}A year later, our user base has exploded, and we’ve decided to shard. But at this point, can we?
The example below shows our four USER shards, and a sample USER record with an ID of 12345 (12345 % 4 = Shard 1) and associated PHONE_NUMBER record of ID 235 (235 % 4 = Shard 3).
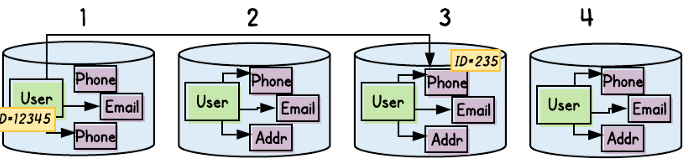
We’ve run into the same problem as with the monolithic data schema.
If we had properly defined our User Aggregate, of course, we would have ensured that every request travels through the root entity. So, it is the root entity’s ID that determines where every entity — including that phone number — belongs.
In our example above, all of the entities — email addresses, mailing addresses, phone numbers, and the root entity itself — associated with user ID 12345 would be stored in Shard 1.
Message passing
Let’s take a brief detour, and mention the bounded context. This is another extremely useful pattern borne out of Domain-Driven Design.
Among other things, it helps us to understand that — rather than a mess of synchronous API calls — our microservices architecture should leverage message passing.
Any time an event occurs within one bounded context, that event will be published to an event bus like Kafka, to be consumed by a service in another bounded context.
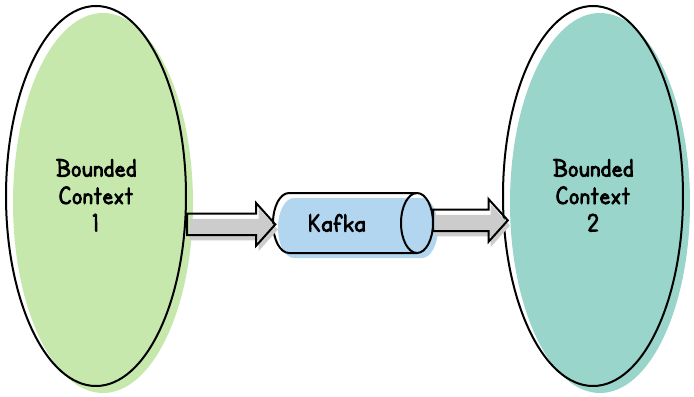
Now, the question usually arises: “What should the message contain?” For example, let’s say a User adds a phone number. Once that change is committed to its data store, we want to publish that edit as a message.
But exactly what should we publish? Generally, we want to publish the new state of the modified data. So, we could simply publish the new phone number:
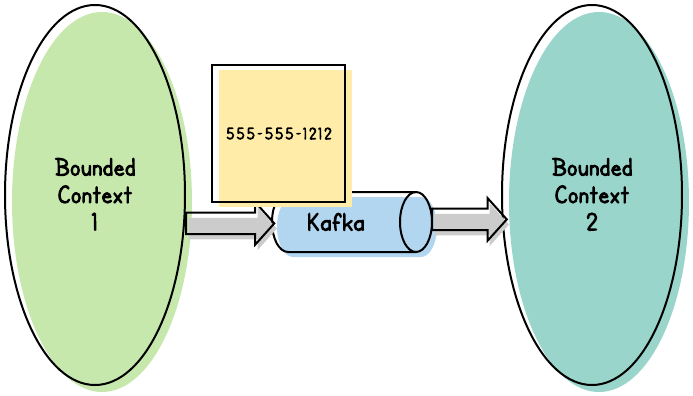
That might be sufficient. Unfortunately, it’s hard to say what additional information the message’s consumers might need. Some consumers, for example, might need to know if the new phone number is also the User’s primary phone number.
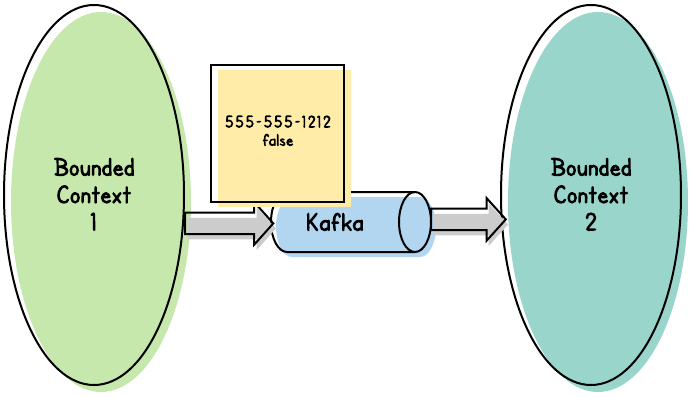
But what if the primary flag is false… and the consumer still needs to know which phone number is the primary?
Hmm. Maybe we should send all of the phone numbers. But… what if another consumer needs to notify the User that the change has been processed, and needs to do it via email? Maybe we should send all of the User’s email addresses as well?
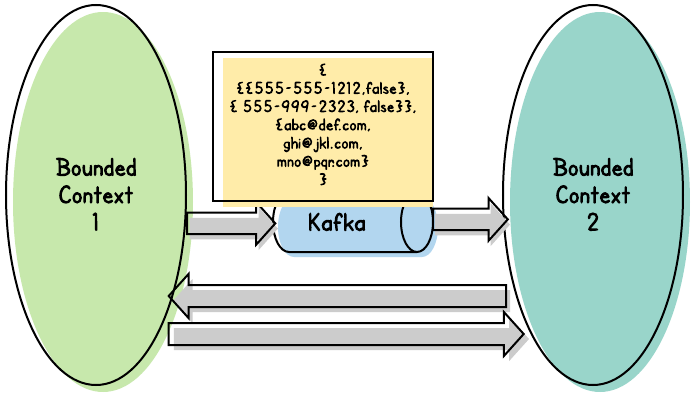
Clearly, this process might never end… and we might never get it right.
An alternative approach that some teams try is to simply send the ID of the modified entity in the message. Any consumer can (nay, must) then call back to the event publisher to obtain the details of the event.
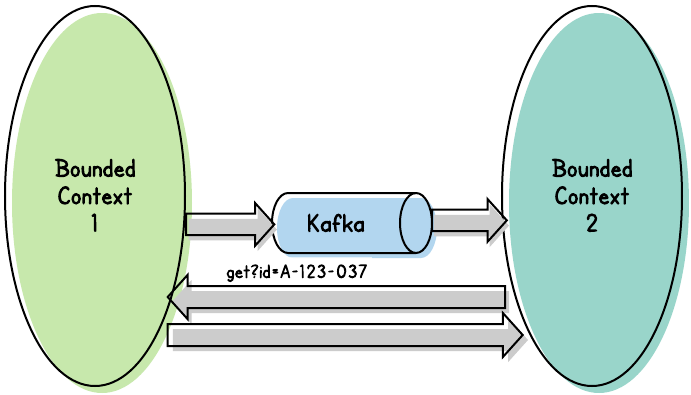
This approach has two unfortunately problems:
- It will, from time to time, result in the wrong data being retrieved. Say entity 123 is modified, and the corresponding message published. Then the same entity is again modified. After that point, a consumer consumes the first event and requests entity 123. That consumer will never pick up that first modification. Now, that might not matter; it could be that the consumer only ever cares about the latest version of the entity. But as producers of the event, we don’t know whether any of our consumers — present and future — might need to track individual changes.
- Worse, it turns our nicely decoupled event-driven architecture back into a tightly-coupled system bogged down by synchronous calls across bounded contexts.
So what should we pass as our messages?
As it turns out, if we’ve embraced Aggregates, then we have our clear answer. Anytime an Aggregate is changed, that Aggregate should be passed as the message.
We know this because an Aggregate is an atomic unit. Any change to any part of the Aggregate means that Aggregate as a whole has been modified.
How that Aggregate is represented in the message, of course, depends on our organization. It might be a simple JSON structure, or it might be represented by an Avro schema.
The Aggregate’s data may or may not be encrypted. But regardless of the data format, thinking and designing in terms of Aggregates makes questions like these no-brainers.
Message Passing and Ordering When we pass messages between microservices, ordering often matters. That is to say, downstream consumers need to process changes in the order that they occurred. For example, if a user changes their name from “Smith” to “Jones” in rapid succession, and those changes are published as Kafka messages, we would expect all consumers to first process the “Smith” change, and then the “Jones” change… not the other way around.
On the surface, this not seem like an issue. After all, Kafka topics operate in a FIFO manner, right? If Message 1 is published to a topic before Message 2, then all of that topic’s consumers should see Message 1 first, right? Well, not necessarily. For scalability, Kafka (and other event buses) further divide their topics into partitions.
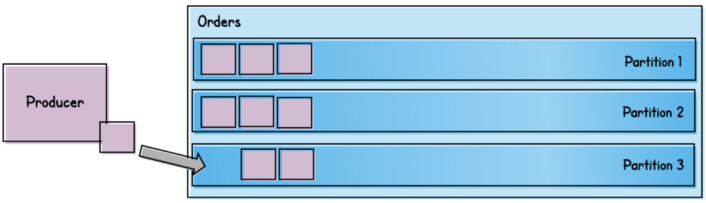
How does this help scalability? Well, a single consumer can actually be deployed as multiple instances, with each listening to its own partition(s). In the example in the above image, a consumer of the “Orders” topic can actually deploy three instances, which will concurrently process the messages on their own partition — thus speeding up message consumption approximately threefold.
Except… now the messages can be processed out of order. Fortunately, Kafka gives us the concept of a partition key, which controls which partition the producer will publish a given message to. We simply configure our producer to tell Kafka what the key of a given message is; Kafka will effectively hash and mod that key by the number of partitions. This guarantees that any messages with the same partition key will be published to the same partition.
How does this relate to Aggregates? Simple. If the messages that we produce represent changes to entire Aggregates, then we can simply use the Aggregate’s ID as the partition key. This will ensure that messages belonging to a given aggregate are always published to the same partition, and thus will ultimately be consumed in order.
Caching
Caching is another topic that can become unwieldy without well-defined, bounded data structures.
Most caches operate like large hashmaps; they allow us to associate some chunk of data with a single identifier, and to later pass in that identifier to retrieve that chunk.
If we haven’t designed our data around Aggregates, it can become difficult to figure out what type of data we want to cache. Imagine a system that is frequently queried but infrequently modified.
In this system, we might want to cache our query results higher up in our stack to minimize trips to the database. Fine. But what should we cache?
We could simply cache the results of every query. Back to our user example, that means that we could be caching the results of things like:
- Searching for a certain user.
- Searching for a certain phone number.
- Searching for a collection of email addresses.
- Searching for the marital status of a given user.
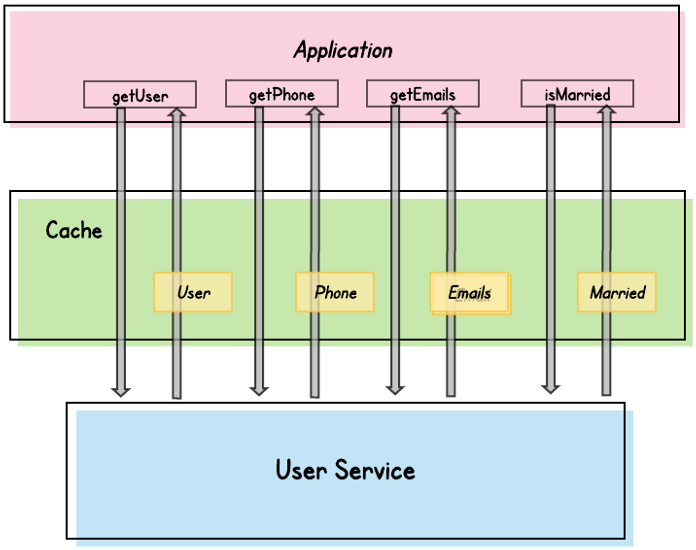
Notice that we’re potentially duplicating data. We’re caching a user object, but we’re also caching individual contact information and groups of contact information, as well as individual fields from the user object.
That has ramifications, of course, in terms of the amount of memory required. It also has more serious ramifications when it comes to cache invalidation.
Imagine that an attribute of a cached phone number changes — from our earlier example, let’s say the “best contact” flag is changed from false to true. So, we invalidate the cached phone number.
But do we also need to invalidate the cached user object? What about the other piece of contact info, that had a corresponding “best contact” change from true to false?
If we’re using Aggregates, we don’t need to worry about these issues. With an Aggregate, we have only a single possible cache key: the Aggregate root’s GUID.
When we retrieve the Aggregate, we cache it. When any attribute of the Aggregate changes, we invalidate the entire Aggregate.
Problem solved.
Service authorization
Well into one of my previous company’s move to microservices, I headed a team tasked with implementing service-to-service, data-level authorization.
In other words, we’d already solved the problem of “is Service A permitted to access Service B?” We needed to solve the problem of “is Service A permitted to request Entity 123 from Service B?”
This meant that we needed to be aware of the current user-agent (for example, the customer who had initiated the request). No problem; that’s what things like JWTs are for. We could pass the user’s ID in a token while making service-to-service calls.
We also needed to be aware of whether that user-agent was permitted to view any particular entity. In our case, the number of potential entities was huge.
In addition, a user might be viewing their own documents, or they might have been given permission by another user to access their documents (for example, by granting power-of-attorney to a third party).
Our goal was to provide a generic, pluggable solution. We also wanted to avoid repeated synchronous calls to a separate service to determine whether a given user had access to a given entity.
For that reason, we decided to determine the items that a given user was permitted to access — once, during startup — and include the IDs of those items in the user’s token.
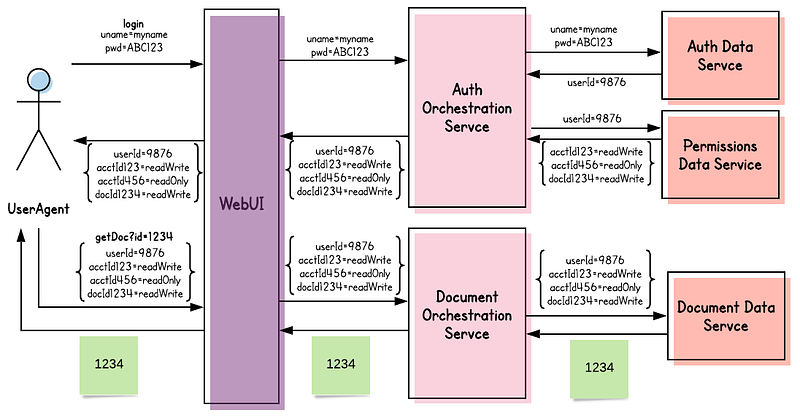
Had we not designed our microservices around Aggregates, this would not have been feasible. The list of potential entities would have been prohibitive.
However, because we had invested up-front in using Aggregates, we had already constrained ourselves to looking up any entity using its Aggregate’s root’s ID.
Therefore, we only needed to track the Aggregates to which a user-agent was granted access. That list was quite feasible.
Tracking changes
We may find ourselves tasked with tracking changes to our data. Historically, we’d recorded data changes by implementing a change data capture (CDC) system triggered by low-level database activities.
More recently, organizations have tended to move towards capturing changes to business entities, rather than changes to column in databases.
So, we’re faced with a question: “What data should be in the snapshot, and how will we use it later down the line?”
As you might imagine by now, answering these questions will be straightforward if we’ve designed our data around Aggregates. Any time a change to any entity is made, we record the new version of its Aggregate. This is not only simple; it’s also more accurate.
Recall that the original purpose of Aggregates is to transactionally enforce invariants. So, each snapshot of the Aggregate will represent the result of any such transactions.
Retrieving the changes later on also becomes much more straightforward. If we want to see the history of a User’s contact information, we won’t need to worry about gathering changes across multiple CDC tables.
Instead, we just go straight to the Aggregate’s table. Likewise, diffing changes becomes trivial; we simply compare one version of an Aggregate to another.
Myriad others
This was a non-exhaustive list of the challenges that designing our entities around Aggregates helped us solve. Undoubtedly, some of us will find others (try implementing the Command Query Responsibility Segregation (CQRS) pattern without Aggregates!)
When we think about it, it makes sense. Applying the Aggregate pattern forces us to think up-front in a methodical way about which entities belong together.
Ultimately, we’ll have constrained ourselves to entities within well-defined, atomic grouping with a single access point. We won’t wind up with those accidental dependencies between entities, or with the sorts of leaky references that will prevent us from implementing scaling solutions.
References
Find this story useful? Want to read more? Just subscribe here to get my latest stories sent directly to your inbox.
You can also support me and my writing — and get access to an unlimited number of stories — by becoming a Medium member today.





