
Why You Should Use Scikit-Learn Pipelines
This tool takes your code to the next level

After spending sufficient time using the Scikit-learn package, machine learning workflows may start to appear repetitive. Tasks often entail subjecting data to a series of transformations before fitting the processed data to an estimator that will then make predictions.
For those looking to take their Scikit-learn expertise to the next level, the module offers the Pipeline class, a tool that enables users to carry out these transformations in a more user-friendly manner.
Here, we delve into what the Scikit-learn pipelines do and why they should be utilized more in machine learning projects.
Why Use Pipelines?
The Scikit-learn pipeline is a tool that chains all steps of the workflow together for a more streamlined procedure.
The key benefit of building a pipeline is improved readability.
Pipelines are able to execute a series of transformations with one call, allowing users to attain results with less code.
They only require one fit method to apply all transformations to the data, which is much more convenient than applying fit and transform methods to the training and testing data for each preprocessing step.
Furthermore, by using pipelines to chain all transformations in the procedure, users can easily understand the workflow at a single glance. With this arrangement, it will be easier to make modifications and spot any potential errors in advance.
Are Pipelines Mandatory?
At this point, you might be thinking: pipelines may improve readability, but can’t we attain readability by writing well-structured code with proper documentation?
The answer is, of course, yes!
The Scikit-learn pipeline is simply a tool of convenience and is not vital for a successful project.
However, when a module directly offers a tool that can make life so much easier, why turn it down?
Case study
The utility of Scikit-learn pipelines can best be demonstrated by creating one with Python.
Suppose that we are building a model that predicts breast cancer using a toy dataset.
The steps for building the model include:
- scaling features with the MinMaxScaler
- reducing dimensionality with PCA
- fitting the data to a random forest classifier
Let’s perform this exercise without a pipeline and then with a pipeline. We can then compare the two approaches in terms of procedure and model performance.
Firstly, we will need to import the following packages:
- Training the model without a pipeline
Creating an estimator without a pipeline is pretty straightforward. For each preprocessing step, we use the fit_transform method on the training data and the transform method on the testing data. We then fit the processed data to the random forest classifier and make predictions with it.
Now that the random forest classifier is trained, let’s evaluate its performance against the testing set using the f-1 score metric.
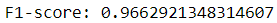
This is a viable approach for training the classifier. However, it might not be ideal in the long run for a few reasons.
Firstly, the odds of making a mistake will rise as more lines of code are written to facilitate the transformations. For instance, it is possible to accidentally apply the fit_transform method to the testing data or execute transformations in the wrong order (e.g., performing PCA before feature scaling).
Secondly, this approach results in code that is suboptimal in terms of readability. The code might seem intuitive as you execute each step of the workflow, but will it remain that way when you revisit your work after several months? Will it be intuitive to others that read your code?
2. Training the model with a pipeline
This time, we will use a pipeline to chain all of the steps in the procedure together.
This means creating a pipeline object and specifying all of the transformations in the steps parameter. The inputted argument is a list of tuples, with each tuple representing a transformation.
How simple was that?
With minimal code, we are able to carry out all of the transformations, train the model, and generate predictions with the model.
Instead of applying a number of fit and transform methods, we only need to use the fit method once to execute all of the steps in the pipeline.
Furthermore, we can now clearly examine the series of transformations that will be applied to the data prior to training the model. This makes the code easier to understand and less prone to error.
The pipeline object can now be used to generate predictions much like any estimator. Let’s see how it performs against the testing set.
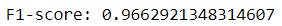
The f-1 score remains the same, which isn’t surprising since pipelines are merely tools of convenience that do not improve model performance. However, if we compare the code used in both approaches, it is easy to see the appeal of Scikit-learn pipelines.
3. Bonus: Optimizing the model with a pipeline
We’ve demonstrated how Scikit-learn pipelines enhance readability by enabling users to train models with minimal code.
However, the pipeline has another feature worth mentioning.
In addition to executing transformations sequentially with much cleaner code, the pipeline object can be used to optimize model performance with hyperparameter tuning!
Typically, hyperparameter tuning is used to find the best set of hyperparameters for the estimator alone. However, with the pipeline, users can optimize the feature engineering process as well!
To accomplish this, we need to create the pipeline object that stores all of the steps in the workflow as well as a dictionary that stores all of the hyperparameters of interest.
The dictionary contains the hyperparameters and their corresponding list of values as key-value pairs. The keys in this dictionary have to specify the transformer/estimator and the hyperparameter with the
After creating the pipeline object and the dictionary of hyperparameters, we can execute the hyperparameter tuning with a grid search.
Finally, we can derive the model with the optimal hyperparameters and use it to generate predictions.
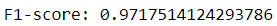
Conclusion

All in all, Scikit-learn pipelines serve as a means to chain together all of the steps in a machine learning task in a more concise manner.
They may not improve model performance, but their ability to streamline the machine learning workflow makes them invaluable.
I wish you the best of luck in your data science endeavors!



