Why you should not use randomSplit in PySpark to split data into train and test.
In case you work with large scale data and want to prepare dataset for your Tensorflow/PyTorch model, don’t use randomSplit function to split data into train and test.
The problem
You have a pyspark dataframe and you would like to split it into two dataframes, train and test. Obviously, you would like to have both parts to be shuffled. The behavior you expect should be similar to train_test_split in sklearn, where it assigns rows in random order into train or test.
However, PySpark function randomSplit first sorts the partitions and then makes splits. It can be found in the comment to the code.
Example
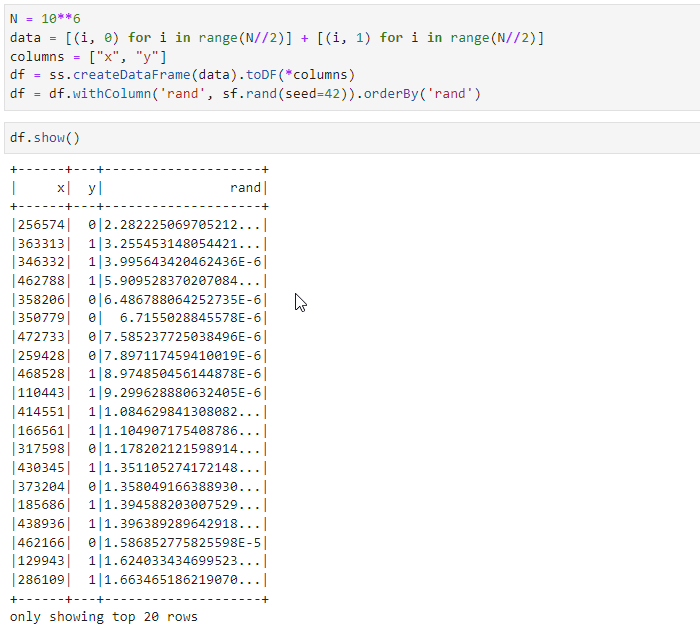
In this example we create a dataframe with x column and then shuffle this column
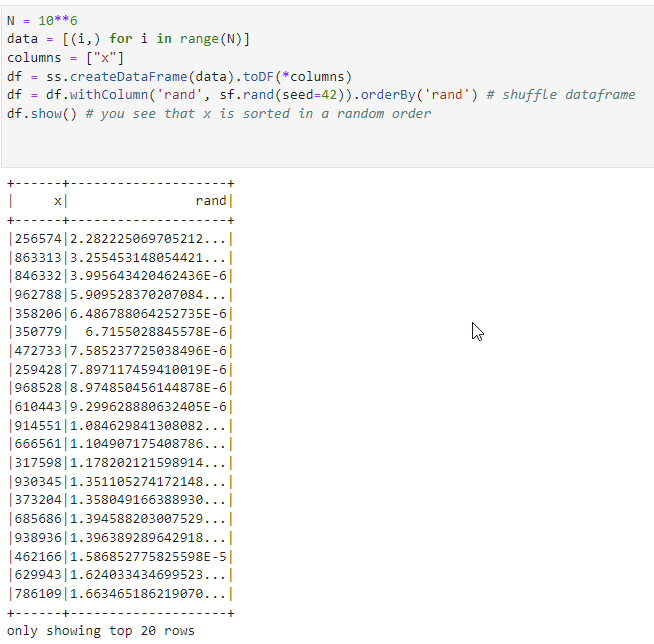
We would expect that after randomSplit we will see also random order of this column. However, it’s not the case, and in fact the column x is in sorted order.
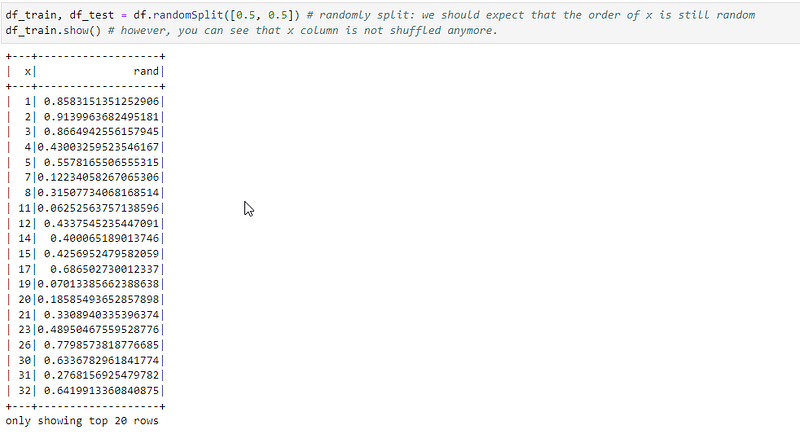
Needless to say that this could cause huge silent problems later on during the training because the training batches would include only instances of one type. Here is an example.
Why it’s a big problem?
Imagine your dataset has 2 columns x and y , where x for features and y is binary target labels that take 0 or 1, for your ML model to predict. Naturally, when you train a model your training batch should have approximately the same distribution of y as in the whole dataset. However, if we use randomSplit, training batch will have either y=0 or y=1.
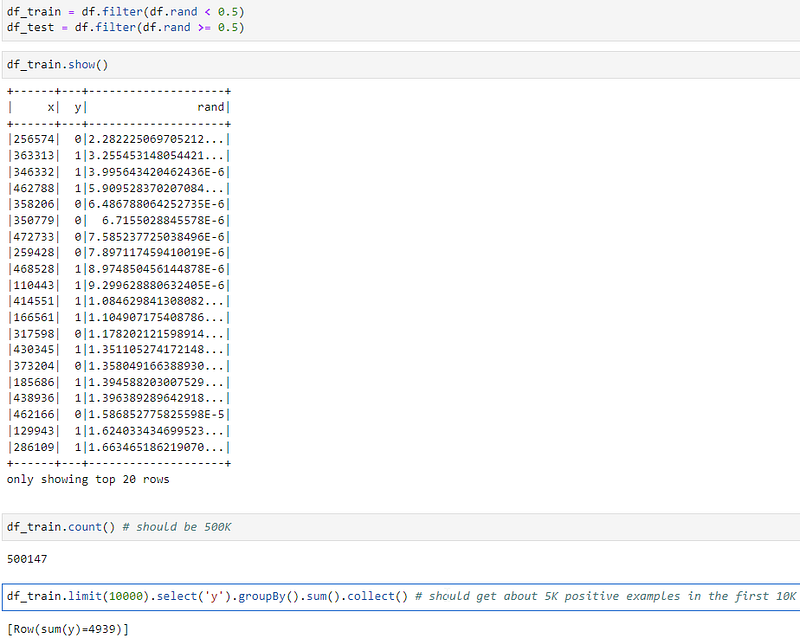
In the example, below we have original dataframe.
Now we do random split and get the following:
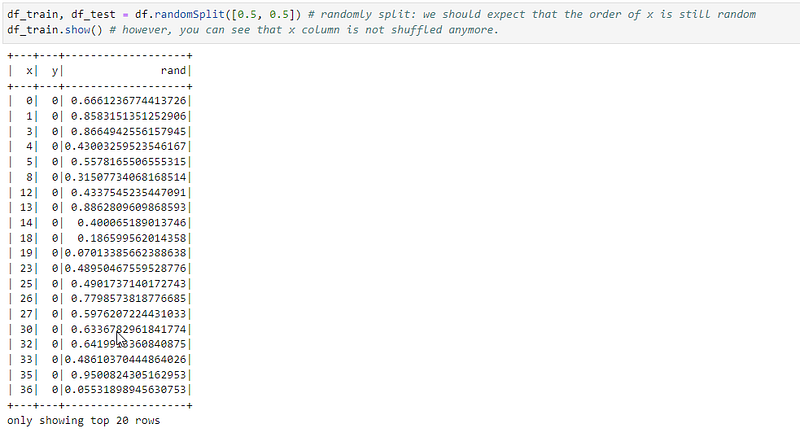
In fact, the first 10K rows of the dataframe has no y=1:

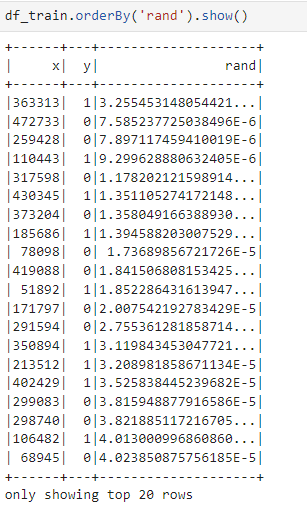
If we look at all the rows of df_train we will see that the ratio of 0 and 1 is balanced (about 250K out of 500K):

So it means that dataframe df_train has the first rows with y=0 which are followed by y=1. This is highly unshuffled behavior, which can silently destroy ML model’s peformance.
Solution
There are 3 solutions to this problem.
- We can just reshuffle dataframes after
randomSplit.The problem is just the cost: for big datasets reshuffling datasets can be expensive.
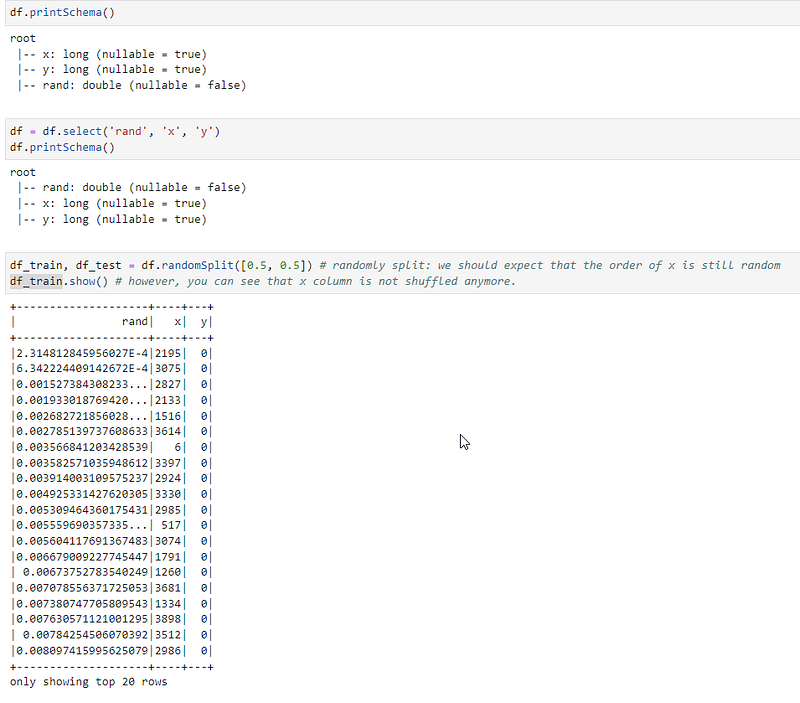
2. Another is more subtle. We can reorder columns and that would impact how ordering is performed. However, it does not always solve the problem.
3. Get rid of randomSplit altogether. Instead, just use filter to get 2 different dataframes. This does not guarantee exact split_ratio, but for a big enough dataset you should get a good approximation.