
Things which Spring pagination tutorials do not talk about
Why Pagination in Spring Is not The Most Efficient Solution?
Implement scalable and high performing pagination solution
I had a request from a business to develop a pagination feature for search transactions. “Sure”, I said. It was a simple solution with the Spring framework. But in our team meetings, one of our colleagues talked about using cursor-based pagination. It triggered further discussions on pagination and I found myself with no clear solution.
What we did next brought out a new perspective to the problem of pagination for us. I will list down the path to our solution below.
- Requirements
- Pagination solution
- Evaluation of approaches
- Conclusion — Solution we implemented
- Further Reading

Requirements
- The consumer of the API will call all pages until there are no records found
- The solution should not return duplicate transactions. Duplicate transactions happen when new transactions arrive between two consecutive page requests
- There was no need to access a random page
- Consistent performance across all pages
- The application should remain stateless
Options
We explored some of the pagination solutions available. The detailed list is here. We shortlisted the below approaches.
- Offset based pagination
- Cursor based pagination
- Continuation Token Pagination
Offset Based Pagination
Offset-based pagination is the traditional way of implementing pagination. Clients need to supply two more parameters in their query: an offset, and a limit. An offset is the number of records you wish to skip before selecting records.
Advantages
- Able to calculate the total number of pages and total items
- Able to access random page
Disadvantages
- Performance degrades as the number of records increases. The database has to read up to the number offset number of rows to know where it should start selecting data. This is often described as O(n) complexity, meaning it is the worst-case scenario.
- Page misses entire results or duplicate transactions will appear. Frequent writes happen in large datasets. The window of results across pages will be inaccurate with frequent writes as : — Page misses entire results — See duplicates because frequent writes add results to the previous page e.g. Operator searches for the last 3 months transaction history. Between two page calls of 10 transactions each, 10 new transactions arrive. This will result in viewing the same 10 transactions on the second page.
Cursor Based Pagination
A cursor is a unique identifier for a specific record. It acts as a pointer to the next record we want to start querying from for the next page. By using a cursor, we remove the need to read all previous rows that we have already seen. We do it through a WHERE clause in our query (making it faster to read data as it’s constant i.e. O(1) time complexity).
We address the issue of inaccurate results by always reading after a specific row. Thus we are not relying on the position of records to remain the same. We can use cursors in any query. But cursors need a server to hold a dedicated database connection and transaction per HTTP client.
Advantages
- Cursors have the desirable property of pagination consistency on arbitrary queries. Cursor shows results as they exist at the time.
- The isolation level of the transaction ensures paginated results won’t change.
Disadvantages
- The problems with cursors are resource usage and client-server coupling
- Bridging HTTP to cursors introduces complications. Servers must identify clients across requests. This is either through a token or by keeping an identifier such as the client IP address in a session.
- Servers must also judge when to release transactions due to inactivity.
- Server load balancing is complex as each client must connect to a dedicated instance
Continuation Token Pagination
Timestamp_Id token is used as a token that will be returned to the client.
- Timestamp: The timestamp of the last element of the current page. It’s mapped to a column like modificationDate or creationDate.
ID: The ID (primary key) of the last element of the current page. This is necessary to distinguish between elements with the same timestamp.
-- Given that T is the timestamp and I is the id contained in the token.SELECT * FROM elementTableWHERE ( timestampColumn < T OR (timestampColumn = T AND idColumn > I))
AND timestampColumn < now()ORDER BY timestampColumn desc, idColumn asc;-- The ids in the idColumn must be unique (out-of-the-box for primary keys)-- We need an index on both columns timestampColumn and idColumnAdvantages:
- Performance does not degrade with data size with constant performance
- No duplicates are delivered to the client
Disadvantages:
- Pages can be traversed only sequentially. Random page access is not possible.
- Total pages count and total results available will not be available
More details can be found here
Evaluation Details
Infrastructure
- Postgres 9.5 running on docker in dev laptop
- Postman to fire messages
- Application running through Intellij
Test Data
- 10k records (total 30k records) each were inserted into 3 tables
- 3 million timestamps were generated for dates between 10–01–2020 and 10–31–2020
Test Scenario
- Page Size was set to 200 and 150 pages were traversed
- All other services were turned off to remove any side-effects
Test Results Summary
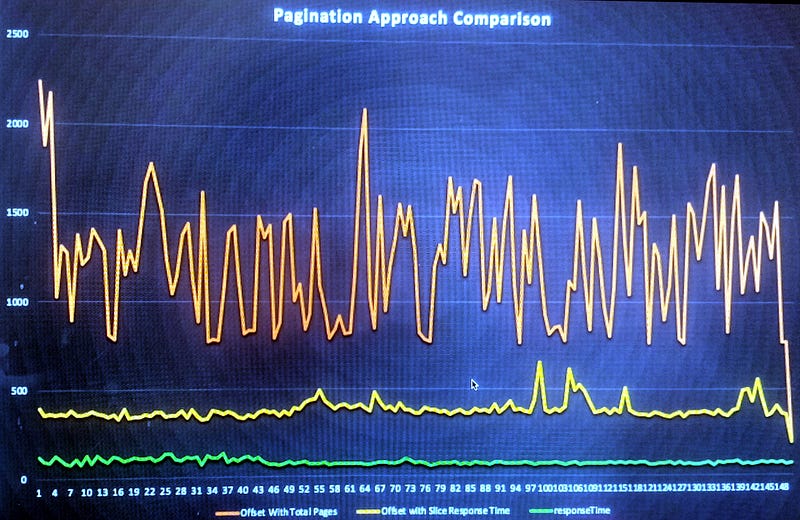
Observations
- There was an extra count all query in Offset based pagination
- Slice performed better as it avoided the total number of pages query
- Continuous page token executed only a single query. Response time was the lowest compared to the other two approaches. The query performance remained constant across all pages
Conclusion
We selected the Continuation Token Pagination technique as:
- It avoided duplicate transactions
- Performance of the API will be fastest and consistent irrespective of the data size
- Microservice will remain stateless if there is no update operation on the columns used to compose the continuation token
So, is this the best approach? The best approach is always that solves a business problem the best. This approach may not solve all pagination problems. But this is one approach to consider when implementing pagination.





