
Why not Mean Squared Error(MSE) as a loss function for Logistic Regression? 🤔
Authors: Rajesh Shreedhar Bhat*, Souradip Chakraborty* (* denotes equal contribution).

In this blog post, we mainly compare “log loss” vs “mean squared error” for logistic regression and show that why log loss is recommended for the same based on empirical and mathematical analysis.
Equations for both the loss functions are as follows:
Log loss:

Mean Squared Loss:

In the above two equations
y: actual label
ŷ: predicted value
n: number of classes
Let's say we have a dataset with 2 classes(n = 2) and the labels are represented as “0” and “1”.
Now we compute the loss value when there is a complete mismatch between predicted values and actual labels and get to see how log-loss is better than MSE.
For example:
Let’s say
- Actual label for a given sample in a dataset is “1”
- Prediction from the model after applying sigmoid function = 0
Loss value when using MSE:
(1- 0)² = 1
Loss value when using log loss:
Before plugging in the values for loss equation, we can have a look at how the graph of log(x) looks like.
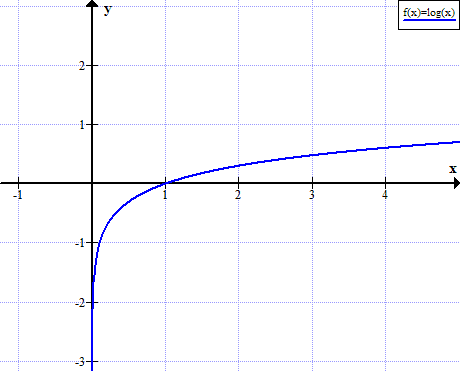
As seen from the above graph as x tends to 0, log(x) tends to -infinity.
Therefore, loss value would be:
-(1 * log(0) + 0 * log(1) ) = tends to infinity !!
As seen above, loss value using MSE was much much less compared to the loss value computed using the log loss function. Hence it is very clear to us that MSE doesn’t strongly penalize misclassifications even for the perfect mismatch!
However, if there is a perfect match between predicted values and actual labels both the loss values would be “0” as shown below.
Actual label: “1”
Predicted: “1”
MSE: (1 - 1)² = 0
Log loss: -(1 * log(1) + 0 * log(0)) = 0
Here we have shown that MSE is not a good choice for binary classification problems. But the same can be extended for multi-class classification problems given that target values are one-hot encoded.
MSE and problem of Non-Convexity in Logistic Regression.
In classification scenarios, we often use gradient-based techniques(Newton Raphson, gradient descent, etc ..) to find the optimal values for coefficients by minimizing the loss function. Hence if the loss function is not convex, it is not guaranteed that we will always reach the global minima, rather we might get stuck at local minima.
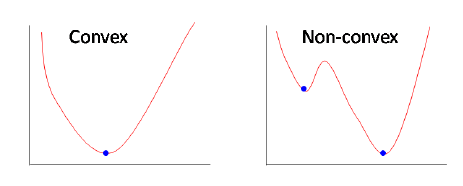
Before diving deep into why MSE is not a convex function when used in logistic regression, first, we will see what are the conditions for a function to be convex.
A real-valued function defined on an n-dimensional interval is called convex if the line segment between any two points on the graph of the function lies above or on the graph.
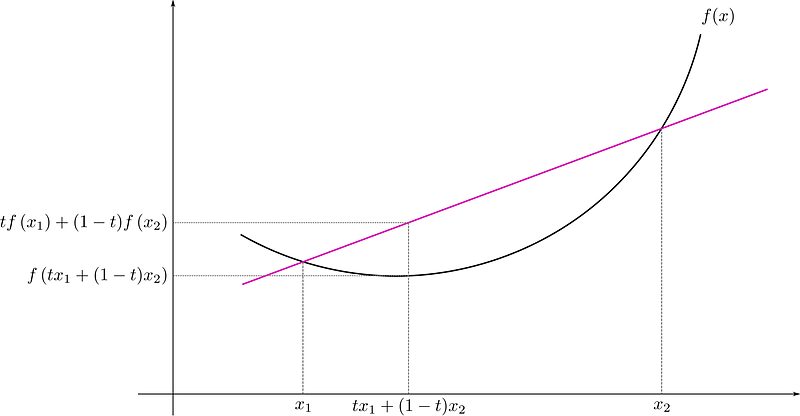
If f is twice differentiable and the domain is the real line, then we can characterize it as follows:
f is convex if and only if f ”(x) ≥ 0 for all x. Hence if we can show that the double derivative of our loss function is ≥ 0 then we can claim it to be convex. For more details, you can refer to this video.
Now we mathematically show that the MSE loss function for logistic regression is non-convex.
For simplicity, let's assume we have one feature “x” and “binary labels” for a given dataset. In the below image f(x) = MSE and ŷ is the predicted value obtained after applying sigmoid function.
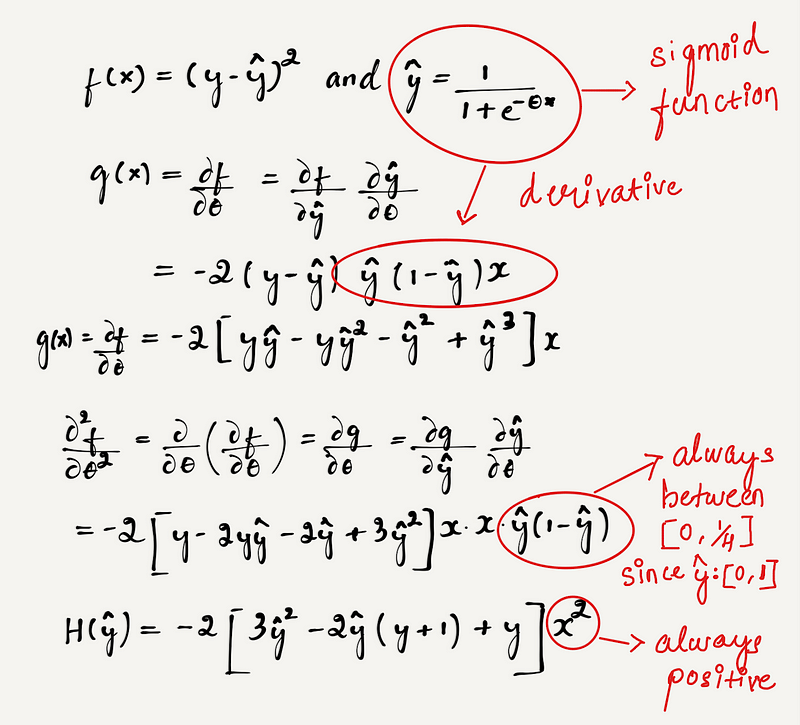
From the above equation, ŷ * (1 - ŷ) lies between [0, 1]. Hence we have to check that if H(ŷ) is positive for all values of “x” or not, to be a convex function.
We know that y can take two values 0 or 1. Let’s check the convexity condition for both the cases.
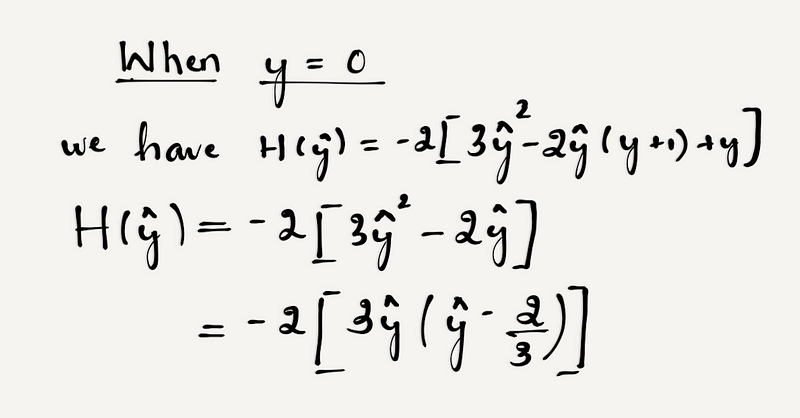
So in the above case when y = 0, it is clear from the equation that when ŷ lies in the range [0, 2/3] the function H(ŷ) ≥ 0 and when ŷ lies between [2/3, 1] the function H(ŷ) ≤ 0. This shows the function is not convex.
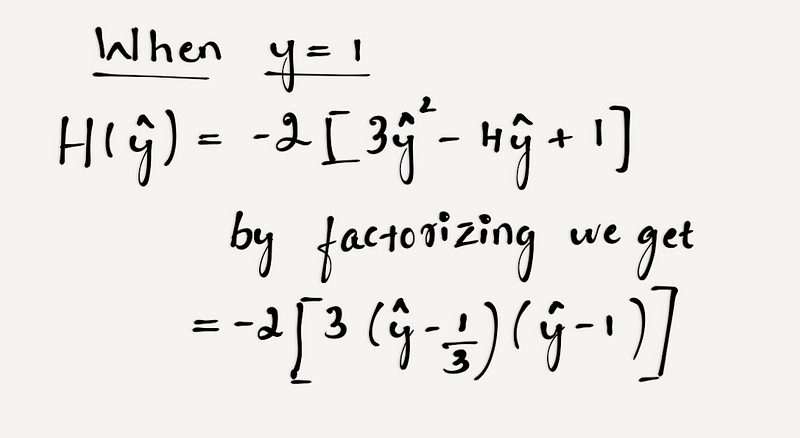
Now, when y = 1, it is clear from the equation that when ŷ lies in the range [0, 1/3] the function H(ŷ) ≤ 0 and when ŷ lies between [1/3, 1] the function H(ŷ) ≥ 0. This also shows the function is not convex.
Hence, based on the convexity definition we have mathematically shown the MSE loss function for logistic regression is non-convex and not recommended.
Now comes the question of convexity of the “log-loss” function!! We will mathematically show that log loss function is convex for logistic regression.
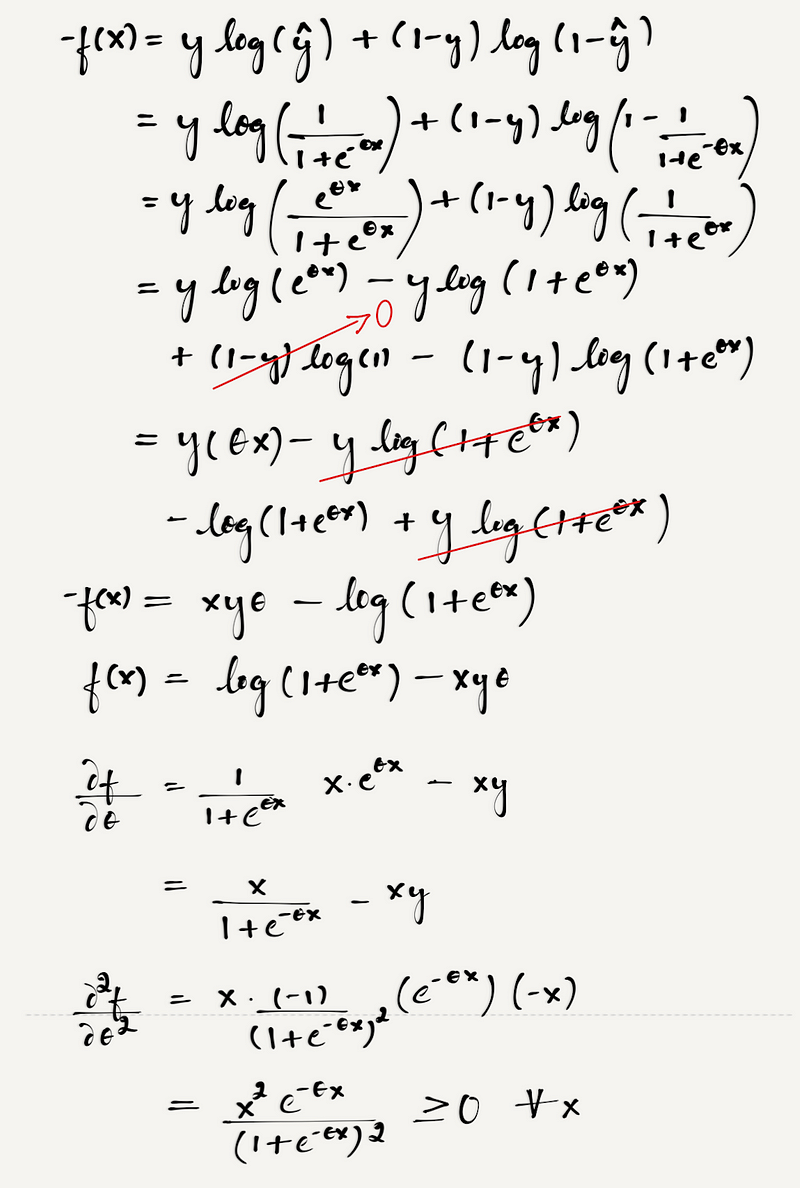
Theta: co-efficient of independent variable “x”.
As seen in the final expression(double derivative of log loss function) the squared terms are always ≥0 and also, in general, we know the range of e^x is (0, infinity). Hence the final term is always ≥0 implying that the log loss function is convex in such scenarios !!
Final thoughts:
We hope this post was able to make you understand the cons of using MSE as a loss function in logistic regression. If you have any thoughts, comments or questions, please leave a comment below or contact us on LinkedIn and don’t forget to click on 👏 if you like the post.
References:




