
Why does a Data Mesh matter?

A data stream, feed and API used to be a subset of an ‘application’ product that interacts with users through graphical user interfaces (GUI). However, as decision making becomes data-driven, organisations start storing and managing a large and disparate set of data while managing access, risk, quality and lifecycle. There is a growing number of organisations managing data ‘as a service’ taking the comparable approach as managing a product — in other words product management. To understand the concept of a data product, we need to understand how the term has been introduced.
What is Data Mesh?
Data mesh is a decentralised approach to data architecture that aims to address the challenges of scaling and managing data in large organisations. It proposes a shift from a centralised data infrastructure to a distributed model where data is treated as a product and owned by individual domain teams. In a data mesh, each domain team is responsible for the data products they create, including data quality, documentation, and compliance of the centrally defined governance. This approach promotes data democratisation, allowing domain experts to have more control over their data and enabling faster and more autonomous decision-making.
What are the Key Components of Data Mesh?
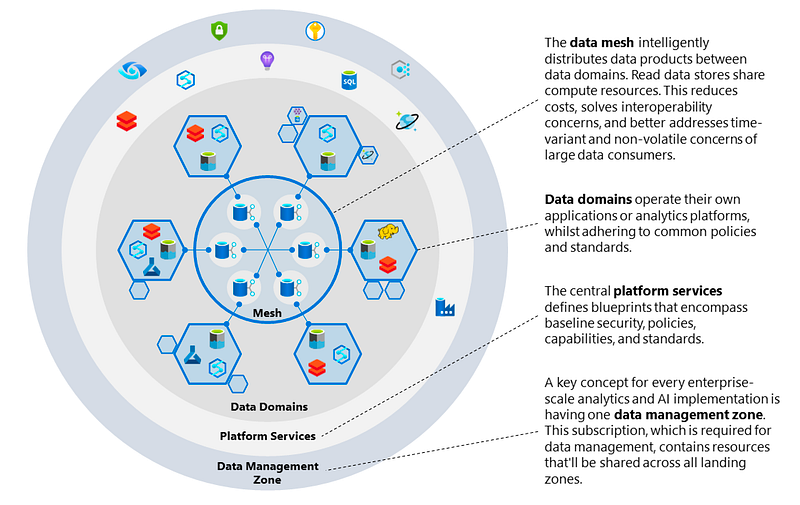
The data mesh concept can break down to several building blocks which are considered as key components.
1️⃣ Self-serve data platform — A data mesh requires a self-serve data platform with a dedicated platform team that manages technical complexity, which allows domain teams to focus on their data use cases.
2️⃣ Domain-driven data ownership — The enterprise needs to be able to clearly define business or organisational domains within the mesh in a way that each domain can contain a data product and its sub products.
3️⃣ Data as a product — Each domain operates its data end to end. Accountability lies with the data owner within the domain. Pipelines become a first-class concern of the domains themselves.
4️⃣ Federated data governance — To ensure that each data owner can trust the others and share its data products, an enterprise data governance body must be established. The governance body implements data quality, central visibility of data ownership, data access management, and data privacy policies.
What is a Data Product in Mesh?
In data mesh, a data product refers to a self-contained and autonomous unit that provides a specific data capability to its consumers. It is designed to encapsulate a specific domain of data and is responsible for its own data quality, data governance, and data lifecycle management. A data product can consist of multiple sub products that can be attributed to specific datasets. A data product is owned and operated by a dedicated product team, which includes data engineers, data scientists, and domain experts. The team is responsible for the end-to-end development, deployment, and maintenance of the data product, ensuring that it meets the needs of its consumers and evolves over time.
By treating data as a product, organisations can enable decentralised data ownership and empower domain experts to take ownership of their data, leading to improved data quality, agility, and scalability. One of the principles from the data mesh paradigm is to consider data as a product — data product. However, the concept can be also developed in the centralised data infrastructure — data fabric, that can be overviewed in the future.
Reference(s)





