
Why ChatGPT isn’t ready to kill Google Yet?
Introduction
ChatGPT is out and it took the world by storm. This new version of GPT3.5, fine tuned to maintain a coherent conversation showcased GPT3’s new capabilities, i.e., a great ability to follow instructions, tell stories, provide educational answers, generate executable code and so on.
Let’s look at a simple example where you ask ChatGPT for an answer, the way you would use Google, but with a very different outcome! (twitter source). Here are both answers.
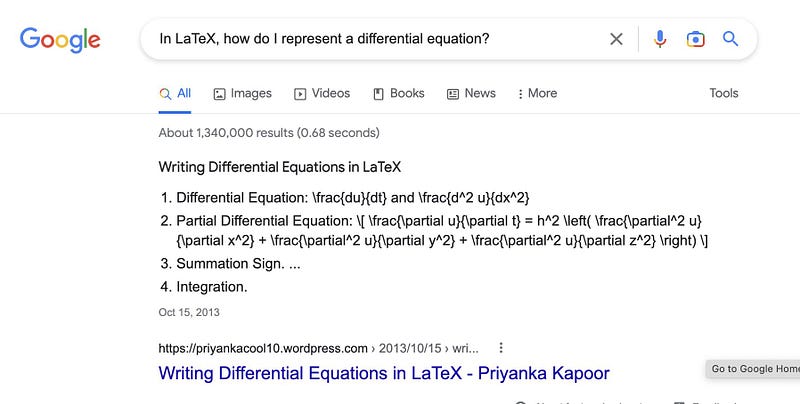
Indeed ChatGPT provides a rather clear and detailed answer. You don’t need to go through different links hoping for a actionable content. It is indeed a great example of what these new AIs are capable of.
And, this is one of a few examples compiled by Tobias Zwingmann. It shows the fascinating applications already tested by the community. To name a few, use ChatGPT to find an answer, or to get an explanation about a complex topic, or to create a prompt to generate an image on dalle2 ;it can also follow instructions to generate code, you can ask it to tell you a story and so on. It does all of it, and it does it more efficiently than older GPT3 versions!
But still… there’s a few things that do not feel right. And that’s why we’re here today. Let’s look at some of its concerning short comings that (will) block its wide adoption, namely accuracy and data governance. But first, let’s understand what we’re dealing with!
What do we know about ChatGPT ?
ChatGPT is a large language model optimized for dialog.
In OpenAI’s own words: “We’ve trained a model called ChatGPT which interacts in a conversational way. The dialogue format makes it possible for ChatGPT to answer follow-up questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests.”
More specifically, ChatGPT is based on OpenAI’s newest model Davinci-003, part of what OpenAI calls GPT3.5 series. This series includes fine tuned models that are much better at following instructions and generating long form answers, starting with davinci-002 (both code and text versions).
In a nutshell, It a fine-tuned model based on gpt3 that is much better at
(1) following instructions (2) in the specific case of ChatGPT, at answering question in a more natural way.
GPT3 was known for suffering from two main issues, namely, hallucination (i.e., presenting false information in a context of credible information) and lack of relevant recent knowledge (since the knowledge base is limited to June 2021). Does ChatGPT alleviate GPT3’s short comings?
GPT3.x Hallucination issues
Hallucination définition: presenting false information in a context of credible information.
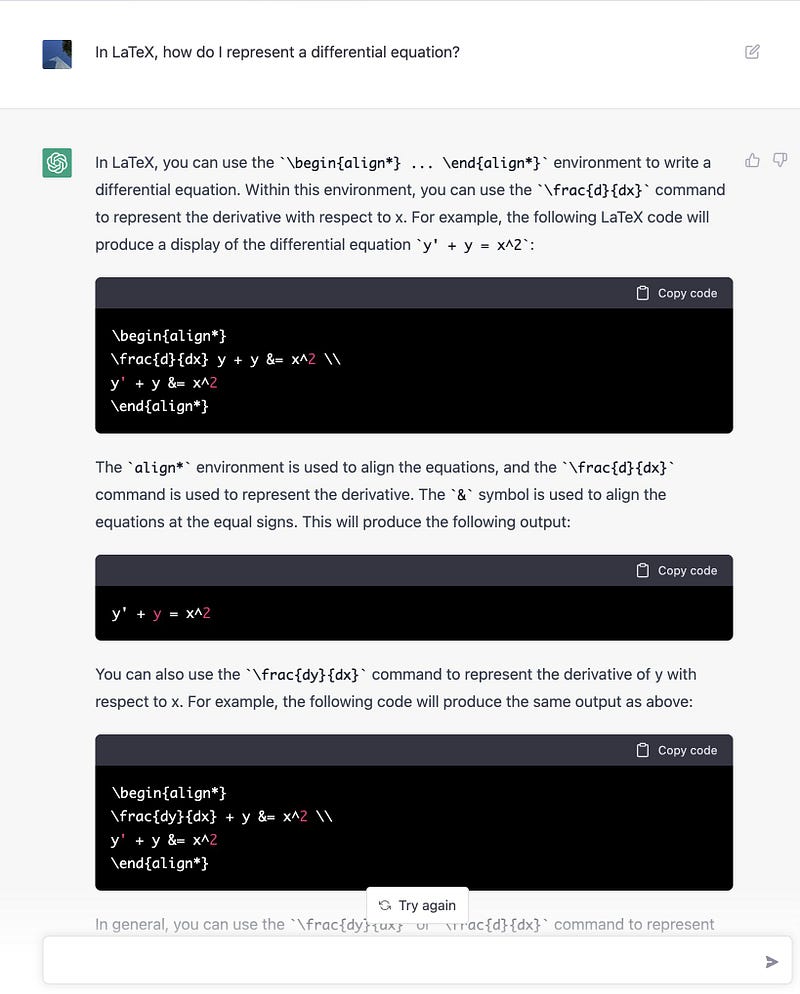
Let’s look at one of the examples mentioned above, i.e., a prompt asking the model to explain a complex algorithm. But this time, a different question was asked (twitter source). Here’s the answer:

The provided answer sounds great! It does follow the prompted instructions, and does sound like a knowledgeable person trying its best to explain a complex notion. Yet… the devil is in the details, and in this case, details show that the answer can contain errors.
The problem is that the overall answer is so good, that you might be enclined to trust it, but you shouldn’t! GPT3 can’t guarantee a correct answer even if it does provide some really good once often!
Hence the tool can be a very powerful assistant in the hands of knowledgeable people (in their area of expertise) ; since they would be able to spot the hallucination part. Unfortunately for the rest of humanity, this could lead to trusting — falsely presented as trustworthy — wrong information.
That is not ok! This issue gets worse with the lack of traceability of the source of information (see below, section on data gouvernance).
Beyond hallucination, lack of relevant recent knowledge.
Although the model does a great job at answering any question (accurately or not is another topic), it’s knowledge based is limited to June 2021. This means that on any new topic, or one where knowledge could change quickly (politics, economics, legislation, medical research, high tech education, to name a few), it will not be of any help! And that’s a BIG blocker today.
So as long as you want it to tell you a plausible story, it is great indeed. But beyond that, on real world applications, I guess we’ll still have to google our answers…
Note that it might be possible to bypass this issue by providing the model with more context. As a matter of fact, GPT3 and GPT3.5 series can take into account additional information provided as part of the prompt, to formulate its answer. Note that the prompt size is quite limited today (~4000 tokens) which limits this feature, at least for now.
Unfortunately Hallucination and Lack of recent relevant data are not the biggest issues at hand today. There a much bigger one… data governance!
Data Gouvernance — ChatGPT relies on your data but doesn’t give you credit for it
When you share your data with Google, you know what you are getting in return! Trafic!
So Yes, they are making a ton of money on your data, but if your SEO is on point, you’re getting your share of it as well, including credit for your work and time (even when it’s using snippet answers)!
But what about Large Language Models such as GPT3? They reached a size and data volume that enables them to often provide us with a sound answer to our questions or instructions, but… that information is coming from various data sources that are not mentioned.
OpenAI used to be opensource and for non-profit ; as pointed out by Elon Musk (see Screenshot below), it’s not true anymore. So it means its selling its service based on your data but with no clear return on investment to content creators.
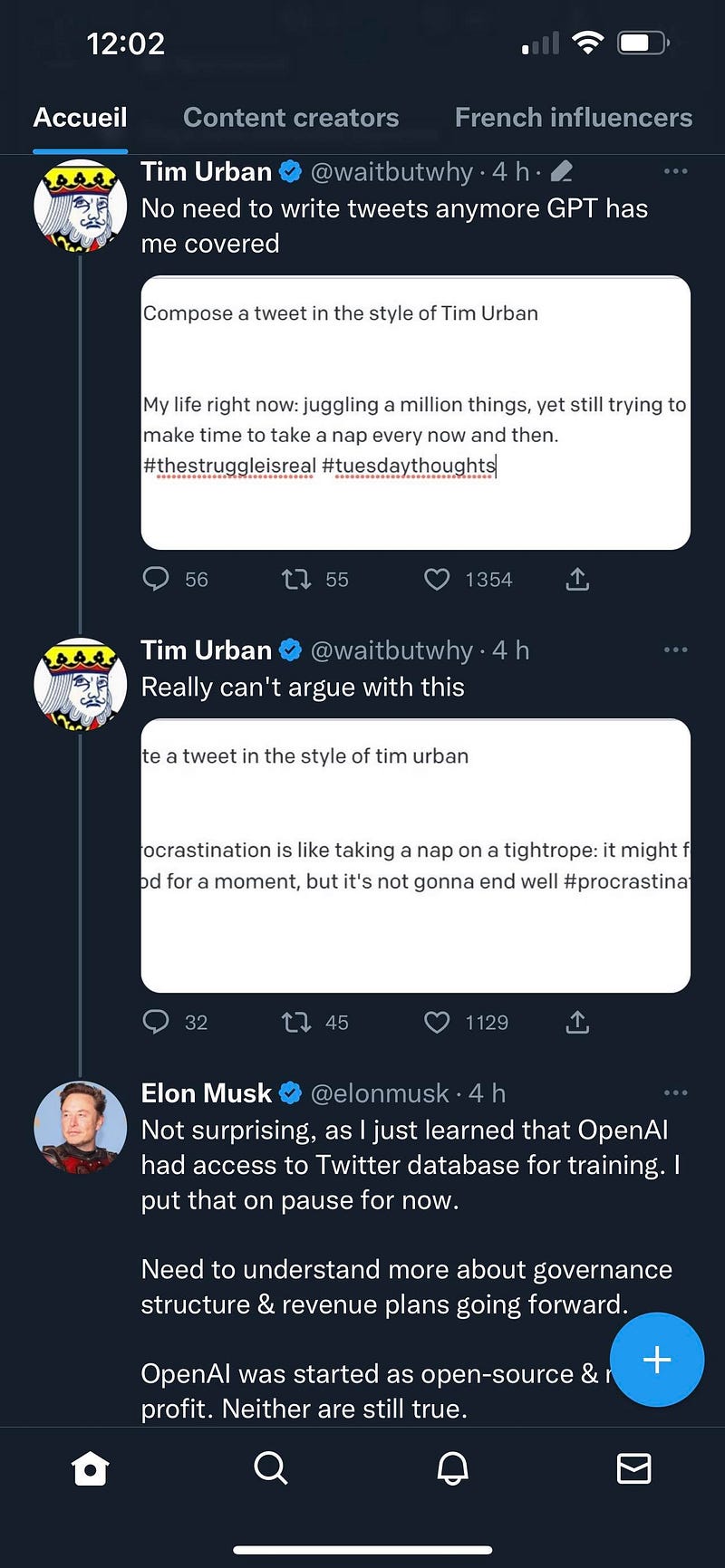
The data gouvernance issue is probably the most worrying one! We can’t fact check answers, and content creators - that large models are relying on - get nothing in return, not even a mention…
And this problem is hard to solve! As a matter of fact, the huge amount of data used for training becomes encoded in the models weights. The result is a actually a probabilistic model trained to complete text. Yes, complete text, nothing more. The additional capabilities that we’re observing are what the AI community calls “emergent” abilities. For some reason the model becomes able to display new abilities such as following prompts…Consequently, there is now way to get back to the original data ; it is lost in translation!
Google is not perfect, but does provide you with a list of relevant data sources that helps you get answers, interact with the community (on forums) and even explore other relevant questions related to the topic you’re looking into (#serenpidity). Using ChatGPT limits you to the answers returned by the model, with no ability to expand your search or trace the source of the data.
Conclusion
ChatGPT is indeed an incredible tool ; It will become, under the right conditions, an incredible general assistant, or a specific one fine tuned to address specific domains. Yet, today, its short comings are still blocking (e.g., hallucination and hack of recent knowledge). The data gouvernance one, is the most worrying as it has today no way of providing us with the source of the answer. Hence, it has no way of giving you credit for the data it is using and monetizing…