
Which Phrases are the Most “ChatGPT” of All?
I analyzed 1.2 million GPT words to find the most common phrases output by ChatGPT — I found some crazy results.

I did an experiment to identify some of the most common ChatGPTisms, and compared them to real human writing. The results are rather hilarious. Yes, your assumptions are correct. ChatGPT has some really annoying patterns, so let’s find out which ones are the most egregious!
How I made my dataset
My ChatGPT data was generated in the following way:
- I wrote a GPT script that produced realistic user prompts that would likely be asked to ChatGPT (quite meta, I know).
- I fed a list of 500 topics into this user prompt generator script five times (with a high temperature so there were no duplicate prompts) to get 2500 realistic GPT calls.
- I fed the 2500 prompts into a new GPT function, posing as fake user prompts so GPT would answer “normally.”
- I collected all these GPT responses into one text file, which is 1.2 million words long. I would have done more, but my wallet was bleeding…
Here’s a sample from this flow:
Generated Fake User Prompt: “Give me some insights on how to incorporate sustainable materials into my line of handcrafted jewelry.”
Here is the Python script that completes this prompt:
def completion(prompt):
response = client.chat.completions.create(
model="gpt-4-1106-preview",
temperature=0.8,
messages=[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": f"{prompt}."}],
)
return response.choices[0].message.content.strip()GPT response: Incorporating sustainable materials into your line of handcrafted jewelry is a commendable approach that aligns with increasing consumer interest in environmentally friendly products. Here are some insights and ideas on how you can do this…
I ran this same flow 2500 times, and I got a fairly longitudinal dataset of ChatGPT content. On to the analysis!
Comparing GPT writing to real human text
I used samples from several English text databases (COCA, COHA, NOW, iWEB) from the Corpus of Contemporary American English. These human samples ended up being over 97.6 million words in total. As far as linguistic analysis goes, this is actually a very small sample. However, I couldn't afford to purchase the full multi-billion word databases (they’re $800), so this is what I’m working with.
I made a code that stripped out the most prevalent three and four-word phrases from this dataset (I didn’t do five or six; the files became so large I didn’t want to accidentally data bomb my computer).
Analyzing the three-word phrases
After much data analysis, I found some interesting things. First, I’ll set the stage with the data:
- Total amount of three-word phrases (real English dataset): 97,648,942
- Total amount of three-word phrases (GPT English dataset): 1,171,775
The most common real English three-word phrase is “one of the.” This accounts for 0.03% of the total phrases in this dataset.
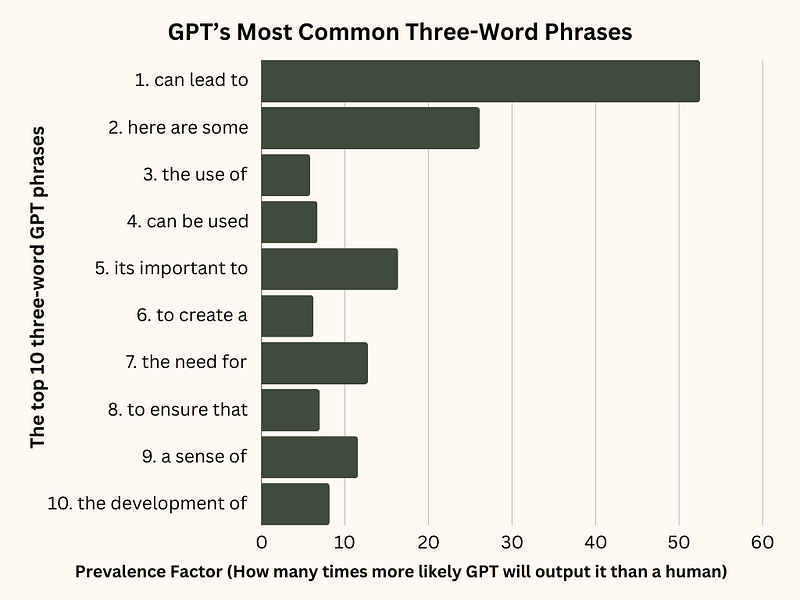
On the flip side, the most common GPT three-word phrase is “can lead to,” which accounts for 0.058% of the total phrases in this dataset.
I calculated the prevalence percentage (the total occurrences of one phrase / the total amount of phrases in the dataset) and then divided those two prevalence percentages to get the prevalence factor, which essentially answers the question: “How much more likely is ChatGPT to output this phrase than a real human?”
Here is a graph showing the top 10 most common three-word phrases in the GPT dataset and their prevalence factors:
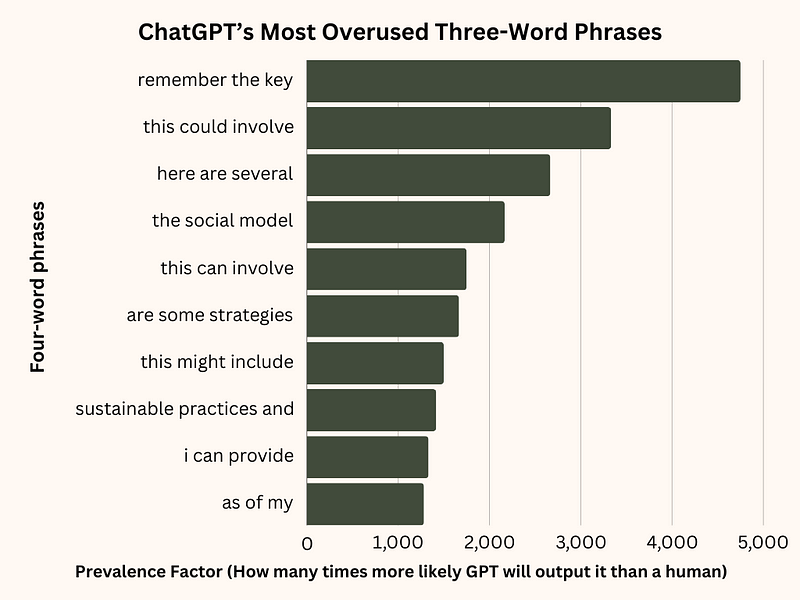
And now for the really interesting stuff. Here is a graph showing the most overused phrases; these are the phrases that are the most “ChatGPT” phrases possible…
Here are a few GPTisms that didn’t make the graphs:
- “the grand tapestry” — 250x prevalence factor
- “a crucial role” — 79x prevalence factor
- “id be happy” — 40x prevalence factor
Analyzing the four-word phrases
Now, on to the four-word phrases:
The most common real English four-word phrase is “the end of the.” This accounts for 0.007% of the total phrases in this dataset.
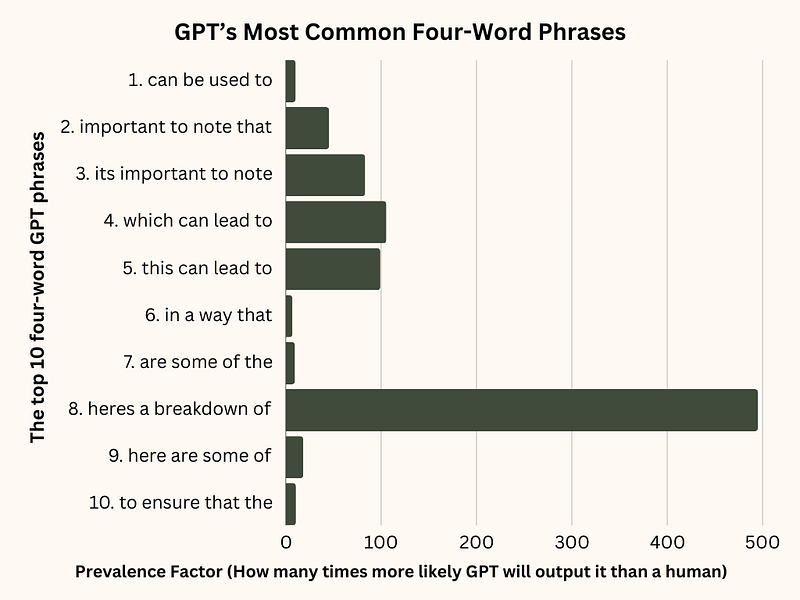
The most common GPT four-word phrase is “can be used to,” which accounts for 0.017% of the total phrases in this dataset.
I conducted the same analysis as I did in the three-word phrases and generated some graphs. Here is a graph showing the top 10 most common four-word phrases in the GPT dataset and their prevalence factors:
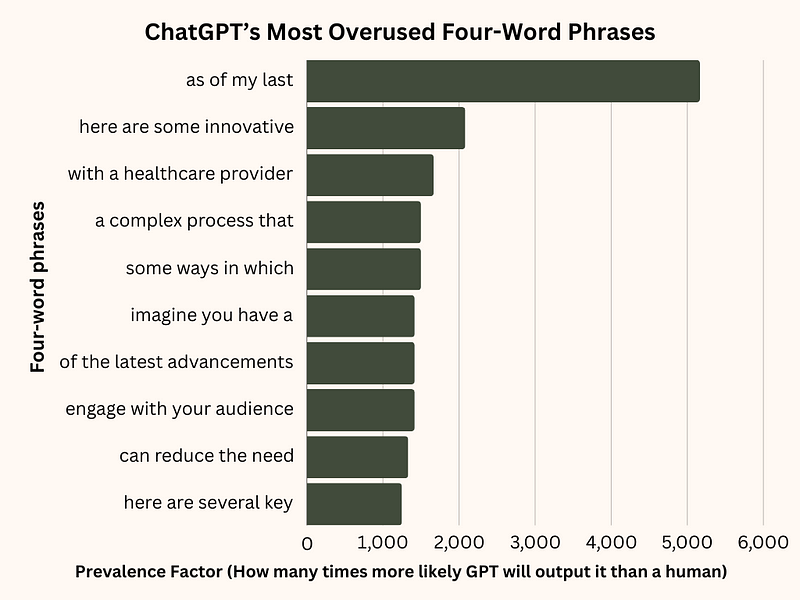
Now for the fun stuff, GPT’s most over-used four-word phrases:
Here are a few GPTisms that didn’t make the graphs:
- “foster a sense of” — 1208x prevalence factor
- “a multifaceted approach that” — 1125x prevalence factor
- “requires careful planning and” — 1000x prevalence factor
I had a ton of fun with this experiment. Let me know of any common phrases you know ChatGPT loves in the comments, and I’ll search my dataset and tell you the prevalence factor.
Thanks for reading!
-Jordan





