
Which Open-Source LLM Should You Choose in 2024?

Since the 2017 paper “Attention Is All You Need” invented the Transformer architecture, natural language processing (NLP) has seen tremendous growth. And with the release of ChatGPT in November 2022, large language models (LLMs) has captured everyone’s interest.
Do you want to use LLMs for your own use case but not pay for every prompt? This article will help you understand the current state of LLMs in 2024. It will also help you decide which open-source model to choose for your own use case.
The Transformer Model
Without going into too much detail, the original Transformer architecture is divided into two interconnected parts: an encoder on the left and a decoder on the right.
The encoder’s job is to encode an input word into a deep vector representation. The decoder’s job is to generate new words.
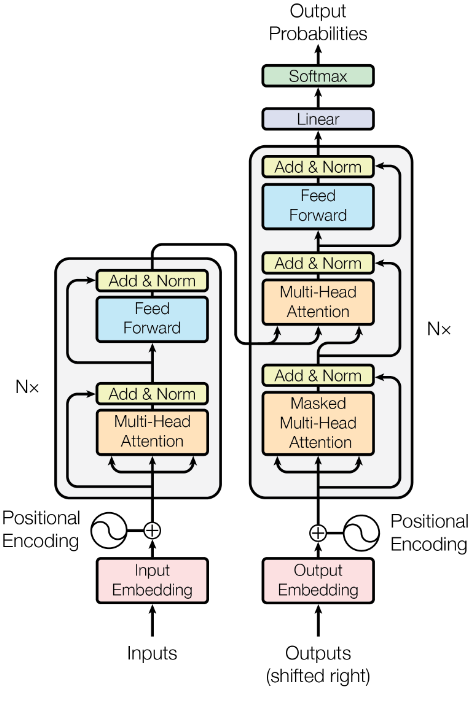
First, an input sentence must be tokenized; that is, words (strings) must be mapped to tokens (numbers). For example, the word “the” can be mapped to the token 342.
The tokens are then converted into high-dimensional embedding vectors. Similar word embeddings are close to each other in this high-dimensional vector space. So, our token number 342 is encoded as a 512-dimensional vector.
Positional encoding is added to the embedding vectors to preserve the order of words in a sentence. This is important for the self-attention mechanism. The attention layers capture the relationship between words in a sentence. For example, a verb in a sentence belongs to a subject.
In the end, the decoder produces output probability values for every single token in our dictionary. So, in each iteration of the decoder, we can choose the most likely next word.
The Evolution of LLMs: Current State of The Art
Yang et al. have documented the evolution of modern LLMs as a tree, classifying the models by their choice of architecture and whether they are open source or not [2]. For an up-to-date version, check out https://github.com/JingfengYang/LLMsPracticalGuide.
Since 2021, new LLMs have mostly been decoder-only LLMs. While Microsoft has released a lot of encoder-decoder models, most other companies focus on decoder-only models.
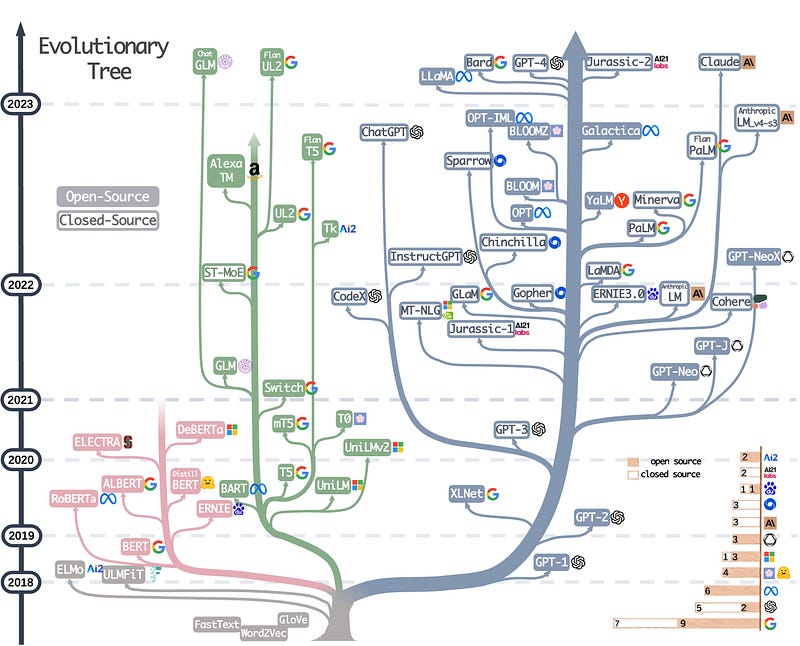
Decoder-only LLMs (for example, GPT-4) are also called autoregressive language models. They are pre-trained by predicting the next word for a given input of words. Decoder-only LLMs are best suited for text generation.

Encoder-decoder models are also called sequence-to-sequence models. During pre-training, some words for a given text are masked, and the model must predict the masked words. In theory, encoder-decoder LLMs are best suited for tasks such as translation, text summarization, and generative question answering.

Recent Open-Source Models
I have compiled a summary of recent open-source Transformer models with additional information in the table below. All of these LLMs can be downloaded and used locally. Most of them are available at the Transformers API of Hugging Face.
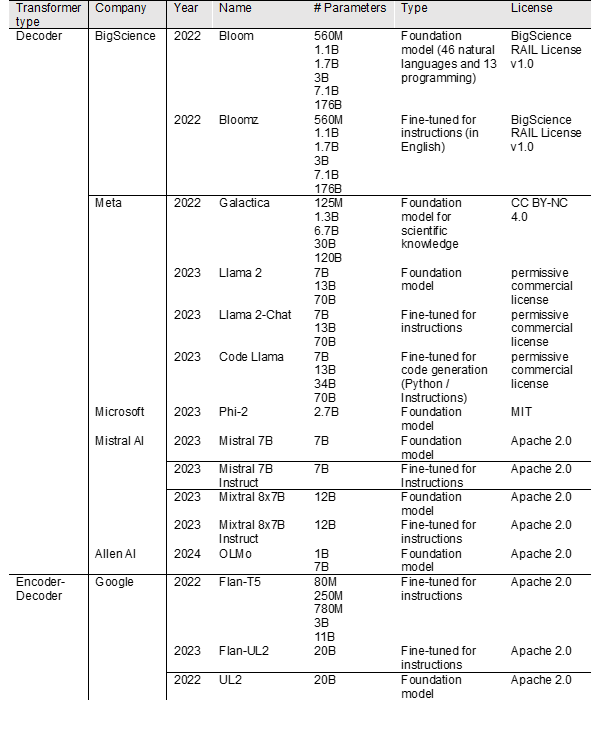
For example, if you want a chatbot to answer questions, you should choose a model that has already been tuned for instructions and whose model size fits your hardware.
There are also domain-specific models, such as “Galactica,” which is trained on scientific knowledge, and “Code Llama Python,” which is trained specifically on Python code.
Model size
The number of parameters and the quantization determine the size of the model, which is a major limitation of the use of LLMs.

To use a LLM, we have to fit the model into memory. Using 32-bit floating points (FP32), 1 parameter requires 4 bytes of RAM.
Using 16-bit quantization (BFLOAT16 or FP16), we can reduce it to 2 bytes of RAM for 1 parameter.
With 8-bit integer (INT8), we need 1 byte of RAM for 1 parameter.
So, storing 1 billion (1B) parameters of a LLM in memory requires approx. 4GB of memory for 32-bit full precision, 2GB for 16-bit half precision, and 1GB for 8-bit precision.
As an example, my GeForce 2060 graphics card has 6 GB of memory, which could fit around 1.5B parameters @ 32-bit, or 3B parameters @ 16-bit, or 6B parameters @ 8-bit.
However, just loading CUDA kernels can consume 1–2GB of memory. So, in practice, you cannot fill the entire GPU memory with just parameters.
Training an LLM requires even more GPU RAM, because optimizer states, gradients, and forward activations require additional memory per parameter [3].
When choosing an LLM, see how much GB of memory your GPU has, and then choose a model that fits. Use 1B parameters = 2GB@16-bit or 1GB@8-bit as a rule of thumb.
Conclusion
If you want to use LLM in your own use case but do not want to pay for a commercial model, you can use available open-source LLMs.
Since LLMs are still relatively new and are constantly improving, you should probably use a model that has been recently released.
If possible, use a model that has been fine-tuned for your specific downstream task. For example, use an instruction model for question-answer prompts. If none exists, you may need to fine-tune a foundation model yourself.
Finally, look at the number of model parameters and compare it to the amount of RAM in your hardware to see if it is possible to load this model.
References
[1] A. Vaswani et al., Attention Is All You Need (2017), arXiv:1706.03762
[2] J. Yang et al., Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond (2023), arXiv:2304.13712
[3] Hugging Face Documentation, Anatomy of Model’s Operations (2024)





