
What’s New in Delta Lake 3.0

To provide a comprehensive understanding of the new features added in Delta Lake 3.0, it is important to first review the fundamental aspects of Delta Lake and its key features. With this in mind, let us begin by defining Delta Lake and exploring its primary capabilities.
What is Delta Lake?
Delta Lake is a storage layer that is optimized for storing data and tables in the Databricks Lakehouse Platform. It is open-source software that extends Parquet data files with a file-based transaction log for ACID transactions and scalable metadata handling.
PS: Parquet is a columnar storage format that is optimized for big data processing. It is a popular format for storing data in data lakes. Delta Lake extends Parquet by adding a file-based transaction log. This log tracks all changes that are made to a Delta Lake table.
Delta Lake Features:
Delta Lake provides a number of features that make it well-suited for managing and storing large amounts of data, such as:
- ACID transactions: Delta Lake ensures that data is always consistent, even when multiple users are working with it at the same time.
- Scalable metadata: Delta Lake uses a scalable metadata format that can handle petabyte-scale tables with billions of files.
- Time travel: Delta Lake allows you to easily roll back to previous versions of your data, which can be helpful for debugging or auditing purposes.
- Unified batch/streaming: Delta Lake can be used for batch and streaming data processing, making it a versatile tool for working with big data.
- Schema evolution: Delta Lake supports schema evolution, which means that you can change the schema of your data without losing data or having to recreate your tables.
- Audit history: Delta Lake keeps an audit history of all changes that are made to your data, which can be helpful for tracking down errors or auditing your data.
What’s New in Delta Lake 3.0
To gain insight into the new features of Delta Lake 3.0, it is important to first address the challenges encountered in the previous version of Delta Lake and how they were addressed in the latest release.
Problem 1: Which storage format should I choose?
There are a number of different open formats available like Apache Hudi and Apache Iceberg. Each with its own strengths and weaknesses. Choosing the right storage format for a data lakehouse can be challenging.
Solution 1: Delta Universal Format (UniForm)
Delta Lake has a new feature that makes it easier for applications to read the data in the format they need. This means that Delta Lake is now more compatible with a wider range of applications and systems. Additionally, Delta Lake can automatically generate metadata needed for other big data platforms like Apache Iceberg or Apache Hudi, which saves users time and effort in converting data formats. With UniForm, Delta Lake is now a universal format that can be used across different ecosystems and applications.
Problem 2: Choosing the right partitioning keys for optimal performance
Building a data lakehouse can be challenging because it’s difficult to create a partitioning strategy that works for all data query patterns and adapts to new workloads over time. Fixed data layouts mean that choosing the right partitioning strategy requires careful planning, and even then, query patterns may change, and the initial strategy may become inefficient. Partition Evolution can help make partitioning more flexible, but it requires continuous monitoring and effort from data engineers.
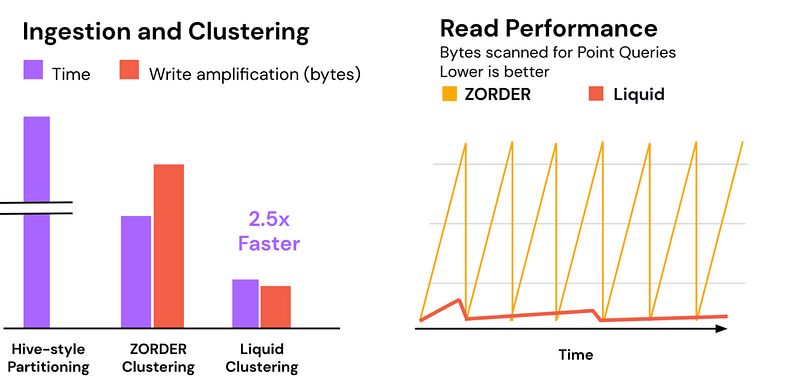
Solution 2: Liquid Clustering
Liquid Clustering is a smart way to manage data in Delta tables. It clusters data dynamically, which helps avoid problems with traditional partitioning methods. To use Liquid Clustering, you just need to set clustering keys on the most frequently queried columns. It’s efficient because it incrementally clusters new data and flexible because you can easily change the columns that are clustered without rewriting existing data.
Problem 3: which connector to prioritize for integrators
Developers and integrators who are building the connectors that enable integration between Delta Lake and other big data platforms face a challenge in deciding which storage formats to prioritize first. They need to balance the maintenance time and costs against engineering resources because every new protocol specification requires new code. This means that they need to carefully consider which formats are most important to their users and invest their resources accordingly.
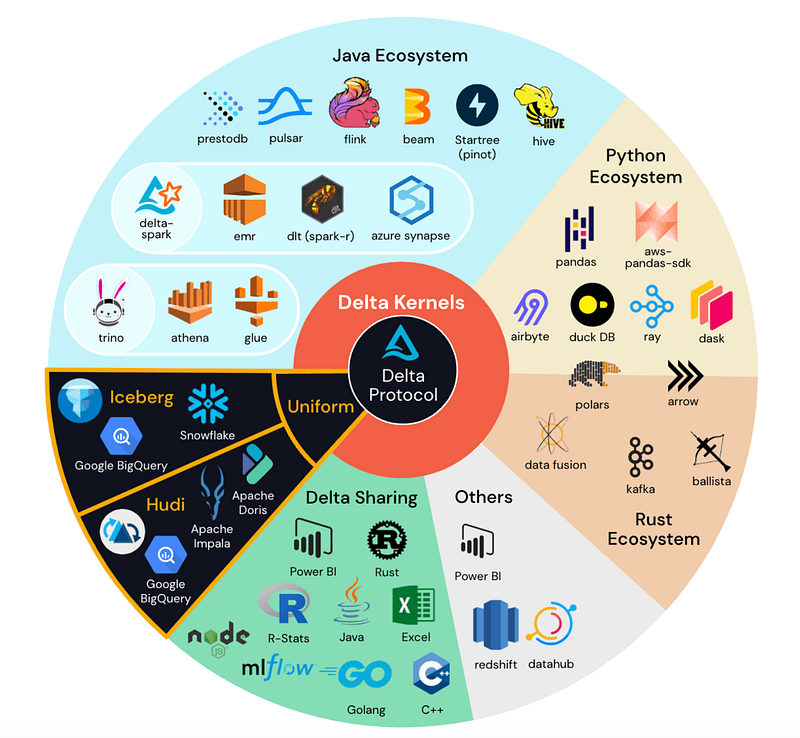
Solution 3: Delta Kernel
Delta Kernel aims to simplify the development of Delta connectors by providing a simplified, narrow, and stable programmatic API. This API will hide all of the complex Delta protocol details, making it easier for developers to create connectors.
Another benefit of Delta Kernel is that it will allow connector developers to access all new Delta features by updating the Kernel version itself, not a single line of code. This means that connector developers will not have to manually update their code every time a new Delta feature is released.
Delta Lake 3.0 is a major release that introduces a number of new features and improvements. These features include:
- Delta Universal Format (UniForm): UniForm allows Delta Lake tables to be read as if they were Apache Iceberg or Apache Hudi tables.
- Delta Kernel: Delta Kernel simplifies building Delta connectors by providing simple, narrow programmatic APIs.
- Liquid Clustering: Liquid Clustering is a new feature that simplifies getting the best query performance with cost-efficient clustering as the data grows.
These new features make Delta Lake a more powerful and versatile tool for managing and storing large amounts of data. They also make it easier to use Delta with different data processing frameworks and systems.
If you like this story don’t forget to hit Follow and Subscribe Now for free to Get an email whenever I publish. Don’t miss out on anything.
Become a Member Now and read every story on Medium. Your membership fee directly supports me and other writers you read. You’ll also get full access to every story on Medium.




