
What’s hot in Text-to-Image Generation — GLIDE, DALL-E and IMAGEN
If you haven’t been living under a rock or were busy attending a conference during the last few days, social media should have notified you of yet another diffusion model called IMAGEN which is generating images from text in progression to openAI’s work.

Yet another text to image generator. Who would have thought that Google Brain would also take a shot at diffusion models generating images from text? Recently we have seen quite a lot of advancements in the text-to-image generation realm. So here is a short recap of the most important cornerstones.
- DALL-E
- GLIDE
- DALL-E 2
- IMAGEN
DALL-E, GLIDE and DALL-E 2
The first big hype was called DALL-E by OpenAI, an autoregressive model that could take in text and generate impressive images even though a bit blurry.
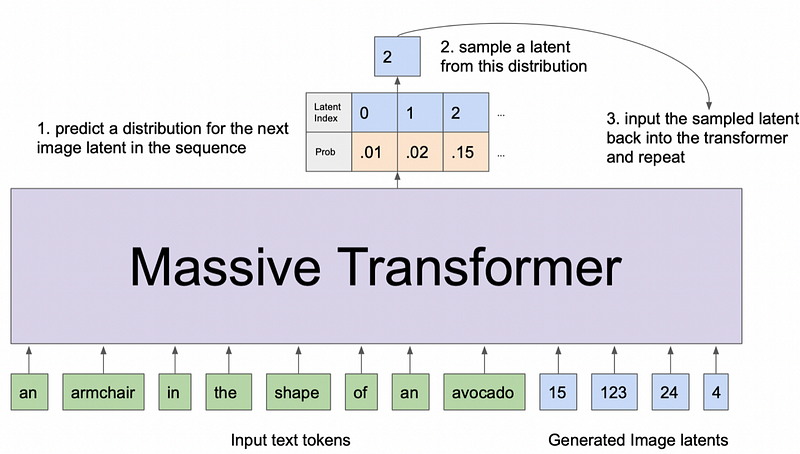
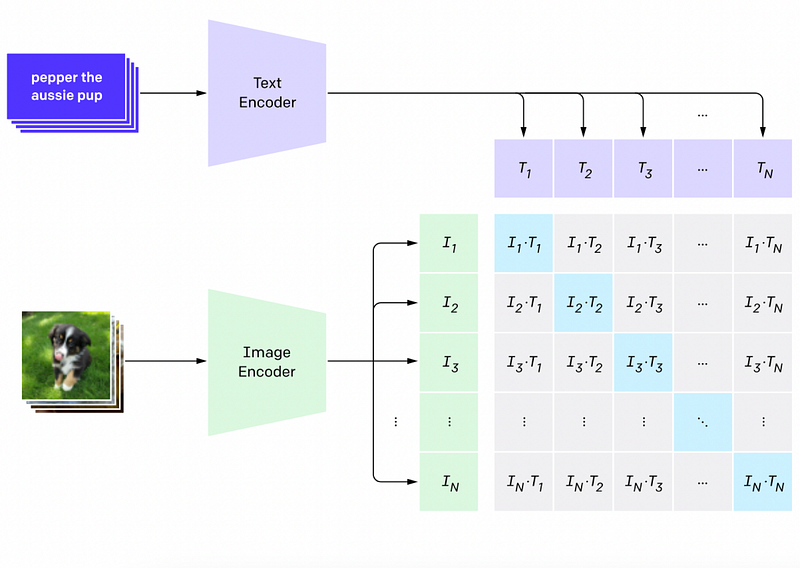
DALL-E is a GPT-like model which, given a piece of text and the start of an image, generates the image Pixel by Pixel, row by row. Then the second bigger bang was made again by OpenAI, but this time with GLIDE, which is a diffusion model. So a very different kind of beast compared to DALL-E. If you do not know what diffusion models are, check out my article where I explain diffusion models in general. In the meantime, people also proposed approaches like VQ-GAN CLIP which uses multimodal text embeddings by CLIP to generate images from them with a VQ-GAN.
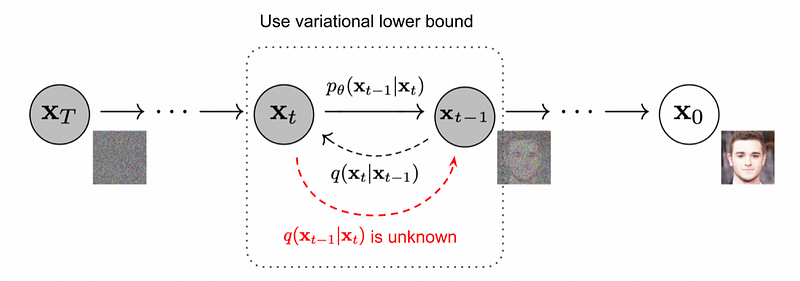
IMAGEN has been delighted by the diffusion technique similar to GLIDE, but unlike GLIDE which was generating relatively small images of 256 X 256 after up sampling. This method successfully applies diffusion models to generate 1024 X 1024 Pixel images.
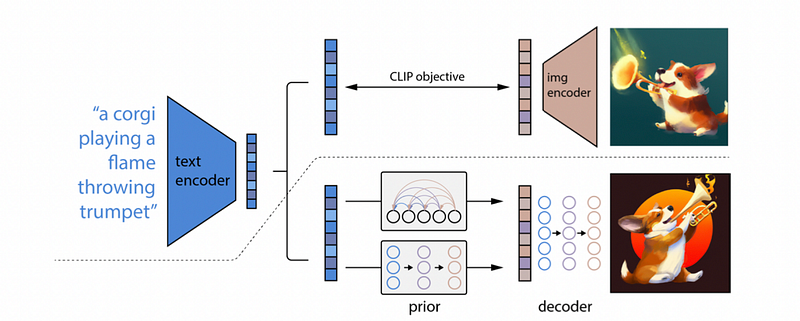
Speaking of social media attraction, this was what DALL-E 2 got in full. After all, it was presented by OpenAI with a big bang as being the follower model of DALL-E. But if you ask me, this was a very successful move. DALL-E 2 being a diffusion model and not an autoregressive model like DALL-E, felt like a successful increment on GLIDE rather than DALL-E. DALL-E 2 is very much like GLIDE, with minimal conceptual changes.
Instead of generating the image from noise, it generates the image from the CLIP image encoding corresponding to the CLIP encoding of the textual prompt. It’s interesting to see how the huge jump from DALL-E to DALL-E 2 only feels large if one doesn’t see the advancements in between like GLIDE.
How IMAGEN work?
Let’s get to the latest and greatest as of today. IMAGEN also is a diffusion model like GLIDE or DALL-E 2, but coming from Google Brain.
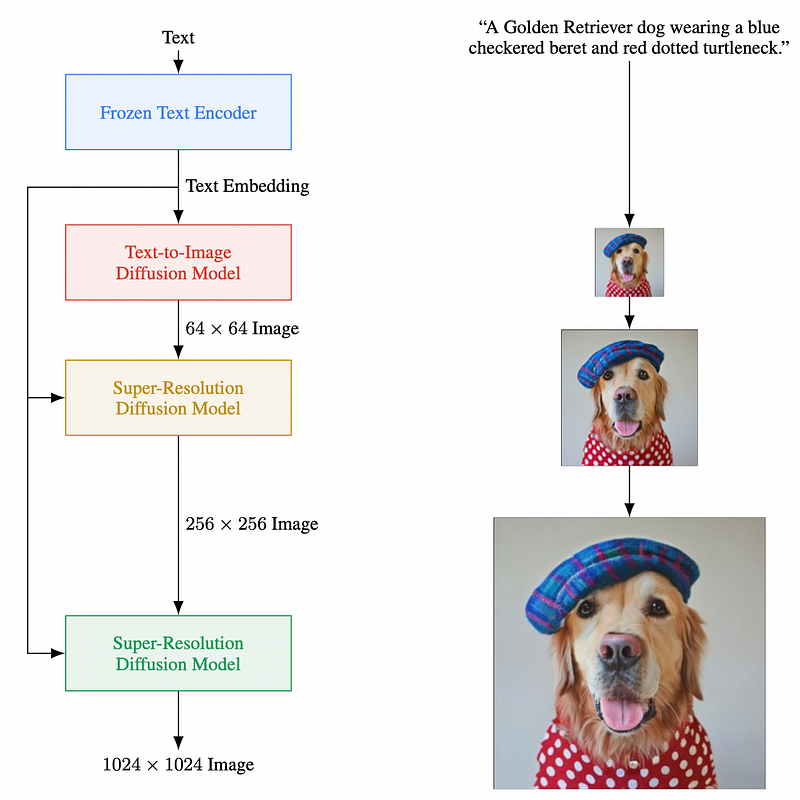
In a nutshell, a diffusion model works like this. To prepare training data, we do the forward diffusion process, where we take an image and add more and more noise to it until it looks like just noise. Then we use one single model like a unit to reverse each of these steps, which is the backward diffusion process. IMAGEN is a diffusion model and is surprisingly similar to GLIDE rather than to DALL-E 2.
Both GLIDE and IMAGEN use a text transformer to encode the language prompt, while GLIDE trains the transformer from scratch. For this, on the training data of DALL-E 2, consisting of images and captions, IMAGEN takes an off the shelf huge language model, namely T5XXL, which has seen lots and lots of text. So text with more variation than just image captions. And the language model is frozen, which seems crucial for keeping its text processing capabilities.
Instead of overly specializing it on the captions of images at training time, the text to image diffusion model learns to generate an image conditioned on the text embedding. Unlike GLIDE, IMAGEN uses a smaller version of the unit to learn the backward diffusion steps. A concatenated super-resolution diffusion model is trained to upscale the generated low resolution image of 64 X 64 pixels to produce a higher resolution image of 256 X 256, which can be further upscaled to 1024 X 1024 by a super resolution diffusion model, which is a nice addition to just diffusion models, which generate images from text.
Magic sauce — Classifier free guidance

Like GLIDE, IMAGEN uses classifier free guidance which is a test time to further enhance the impact of the text. So when generating a sample, one runs the whole diffusion process once with text conditioning and another whole process without any text conditioning. Once computed the difference between the diffusion step with text and without text, with this difference, we now know in which direction to move if we want to go from no text to text. So we take the textless generation and add this difference scaled by quite a lot, such that the output of the model without text information is heavily extrapolated into the direction of text information. And yes, this is a weird hack, such that the image generation is more faithful to the text, but it seems to work both for IMAGEN and for GLIDE, so it does the job for classifier free guidance.
In IMAGEN, the authors also introduced a dynamic thresholding method to make sure that by extrapolating into the direction of the text, we do not generate pixels that are out of the allowed range.
This reportedly results in better photorealism and better image text alignment.
Since IMAGEN draws so much attention, is there something that it can deliver that DALL-E 2 does not? IMAGEN advertises itself with sites, an unprecedented degree of photorealism and a deep level of language understanding well in terms of photorealism, the authors of IMAGEN show side by side comparisons to DALL-E 2 and claim higher photorealism.
New Benchmark in the area
The state of the art is so good now that evaluating the models is subjective. Already, at least the IMAGEN paper proposes a direction on how to evaluate these text. To image generators more consistently, the authors introduced “Drawbench” of 200 text prompts probing for certain model capacities. They include creative prompts that push the limits of the model’s ability to generate highly implausible scenes well beyond the scope of the training data.
In general, IMAGEN performs better on the “Drawbench” than competitors, but I would really like to see a larger benchmark where others can contribute to such that testing cannot fall victim to wishful thinking, maybe unconsciously introduced by benchmark makers when they want to prove their model to be the best.
It looks like IMAGEN is generally better with generating text than GLIDE when it comes to faithfulness with the text prompt and language understanding image and delivers great results.
References
[1] CLIP: Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International Conference on Machine Learning. PMLR, 2021.
[2] DALL-E: Ramesh, Aditya, et al. “Zero-shot text-to-image generation.” International Conference on Machine Learning. PMLR, 2021.
[3] GLIDE: Nichol, Alex, et al. “Glide: Towards photorealistic image generation and editing with text-guided diffusion models.” arXiv preprint arXiv:2112.10741 (2021).
[4] DALL-E 2: Ramesh, Aditya, et al. “Hierarchical text-conditional image generation with clip latents.” arXiv preprint arXiv:2204.06125 (2022).
[5] IMAGEN: Saharia, Chitwan, et al. “Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding.” arXiv preprint arXiv:2205.11487 (2022).
[6] Video: https://www.youtube.com/watch?v=xqDeAz0U-R4&t=812s
Keep Learning, Keep Hustling