
Your validation loss is lower than your training loss? This is why!
Just because your model learns from the training set doesn’t mean its performance will be better on it.
Sometimes data scientists come across cases where their validation loss is lower than their training loss. This is a weird observation because the model is learning from the training set, so it should be able to predict the training set better, yet we observe higher training loss. There are a few reasons why this could happen, and I’ll go through the common ones in this article.

Reason 1: L1 or L2 Regularization
Symptoms: validation loss is consistently lower than training loss, but the gap between them shrinks over time
Whether you’re using L1 or L2 regularization, you’re effectively inflating the error function by adding the model weights to it:

The regularization terms are only applied while training the model on the training set, inflating the training loss. During validation and testing, your loss function only comprises prediction error, resulting in a generally lower loss than the training set.
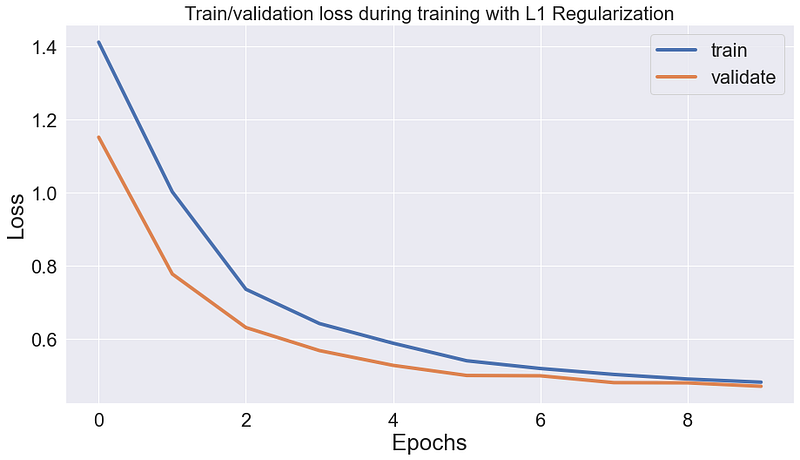
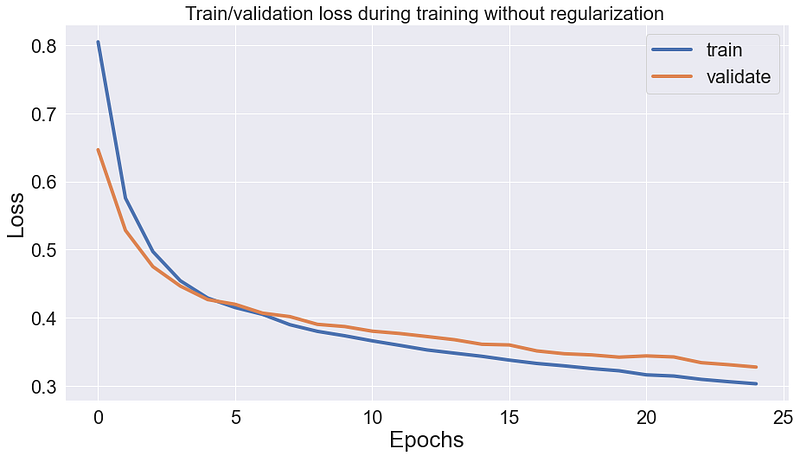
Notice how the gap between validation and train loss shrinks after each epoch. This is because as the network learns the data, it also shrinks the regularization loss (model weights), leading to a minor difference between validation and train loss.
However, the model is still more accurate on the training set.
Let’s compare the R2 score of the model on the train and validation sets:
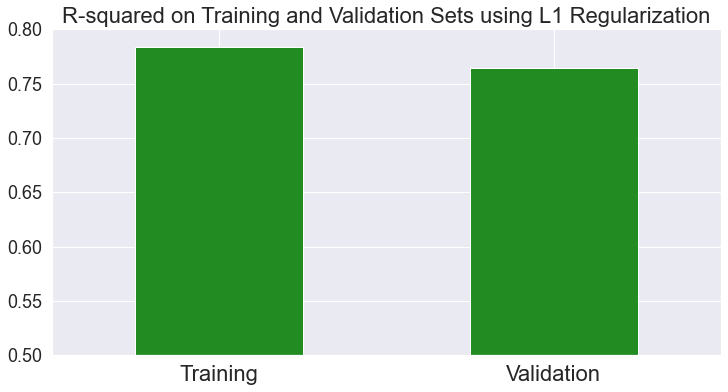
Notice that we’re not talking about loss and only focus on the model's prediction on train and validation sets. As expected, the model predicts the train set better than the validation set.
Reason 2: Dropout
Symptoms: validation loss is consistently lower than the training loss, the gap between them remains more or less the same size and training loss has fluctuations.
Dropout penalizes model variance by randomly freezing neurons in a layer during model training. Like L1 and L2 regularization, dropout is only applicable during the training process and affects training loss, leading to cases where validation loss is lower than training loss.
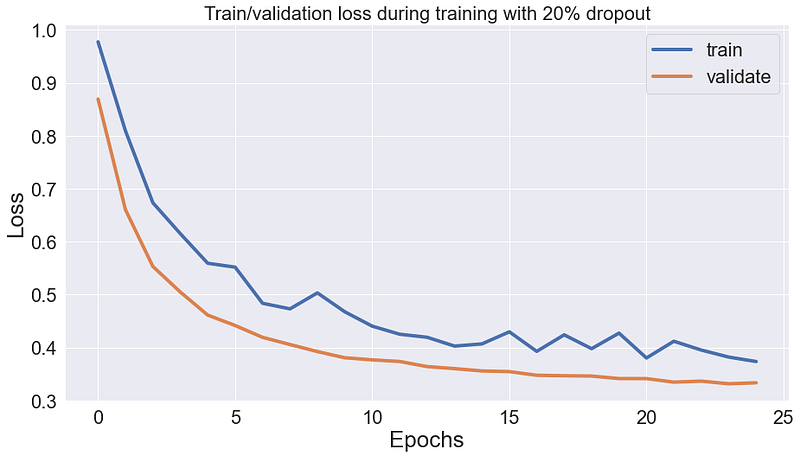
In this case, the model is more accurate on the training set as well:
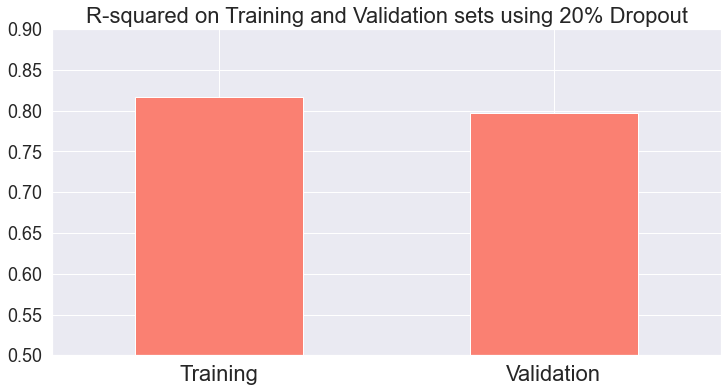
Which is expected. Lower loss does not always translate to higher accuracy when you also have regularization or dropout in the network.
Reason 3: Training loss is calculated during each epoch, but validation loss is calculated at the end of each epoch
Symptoms: validation loss lower than training loss at first but has similar or higher values later on
Remember that each epoch is completed when all of your training data is passed through the network precisely once, and if you pass data in small batches, each epoch could have multiple backpropagations. Each backpropagation step could improve the model significantly, especially in the first few epochs when the weights are still relatively untrained.
As a result, you may get lower validation loss in the first few epochs when each backpropagation updates the model significantly.
Reason 4: Sheer luck! (Applicable to all ML models)
Symptoms: validation set has lower loss and higher accuracy than the training set. You also don’t have that much data.
Remember that noise is variations in the dependent variable that independent variables cannot explain. When you do the train/validation/test split, you may have more noise in the training set than in test or validation sets in some iterations. This makes the model less accurate on the training set if the model is not overfitting.
If you're using it, this can be treated by changing the random seed in the train_test_split function (not applicable to time series analysis).
Note that this outcome is unlikely when the dataset is significant due to the law of large numbers.
Let’s conduct an experiment and observe the sensitivity of validation accuracy to random seed in train_test_split function. I’ll run model training and hyperparameter tuning in a for loop and only change the random seed in train_test_split and visualize the results:
for i in range(10):
X_train, X_val, y_train, y_val = train_test_split(X, Y, test_size = 0.3, random_state = i)
xg = XGBRegressor()
grid_obj = GridSearchCV(xg, parameters, n_jobs=-1)
grid_obj = grid_obj.fit(X_train, y_train)
val_r2.append(r2_score(y_val, grid_obj.predict(X_val)))
train_r2.append(r2_score(y_train, grid_obj.predict(X_train)))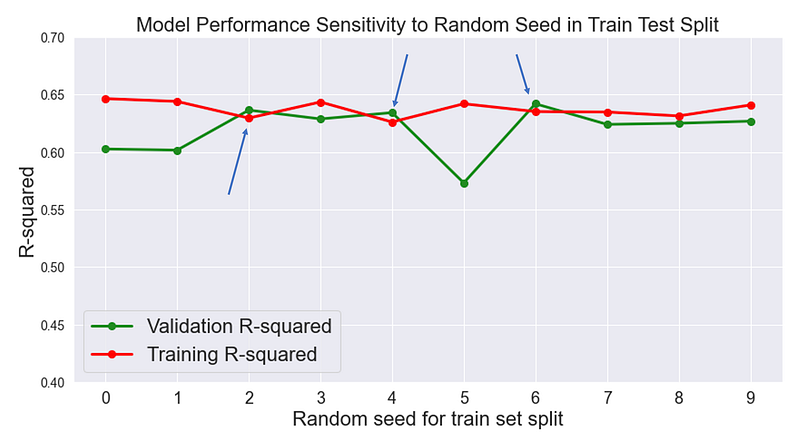
In 3 out of 10 experiments, the model had a slightly better R2 score on the validation set than the training set. In this case, changing the random seed to a value that distributes noise uniformly between validation and training set would be a reasonable next step.
There is more to be said about the plot. Data scientists usually focus on hyperparameter tuning and model selection while losing sight of simple things such as random seeds that drastically impact our results. Still, I’ll write about that in a future article!
Summary
We discussed four scenarios that led to lower validation than training loss and explained the root cause. We saw that often, lower validation loss does not necessarily translate into higher validation accuracy, but when it does, redistributing train and validation sets can fix the issue.
We conducted this study under the hypothesis that we’re not suffering from other issues such as data leakage or sampling bias, as they can also lead to similar observations.
Make sure to follow for more!




