
What Is Visual ChatGPT?
A sneak peek at multimodality
Visual ChatGPT is not a new model. Instead, it uses existing vision and language foundation models and merges them into a ChatGPT-like interface.
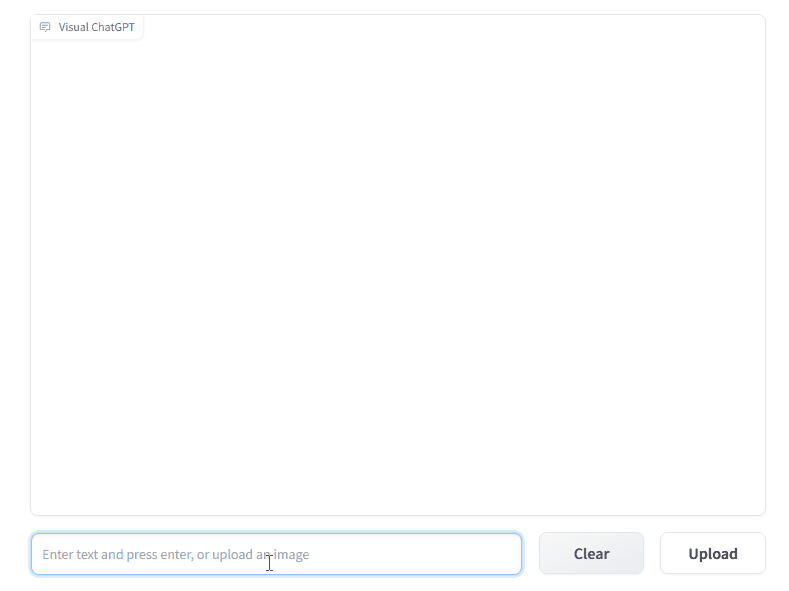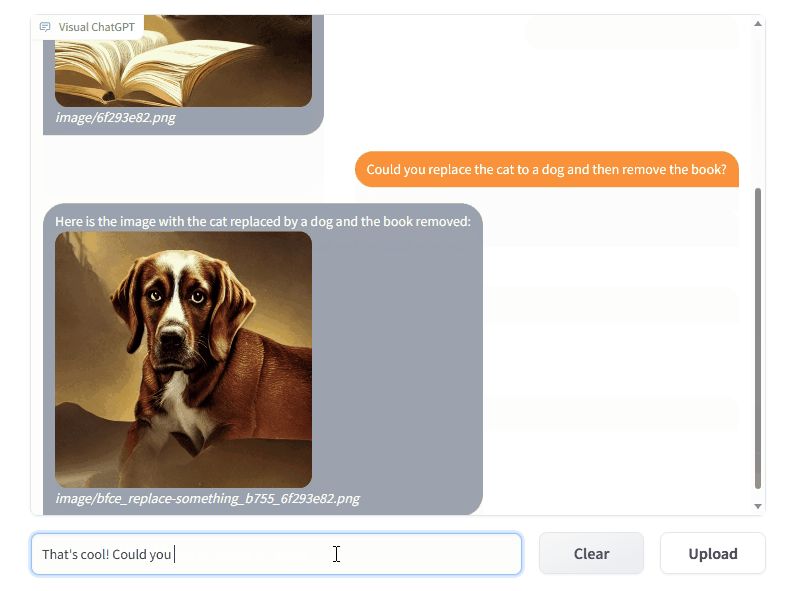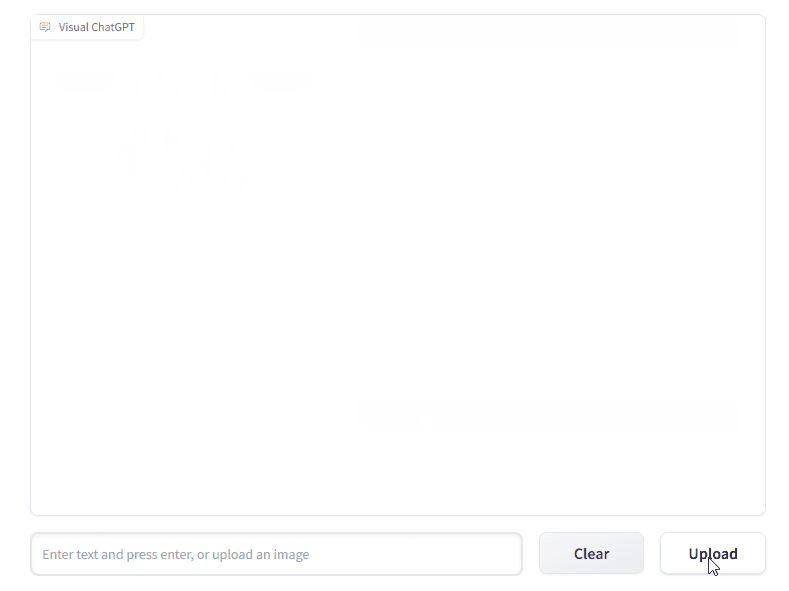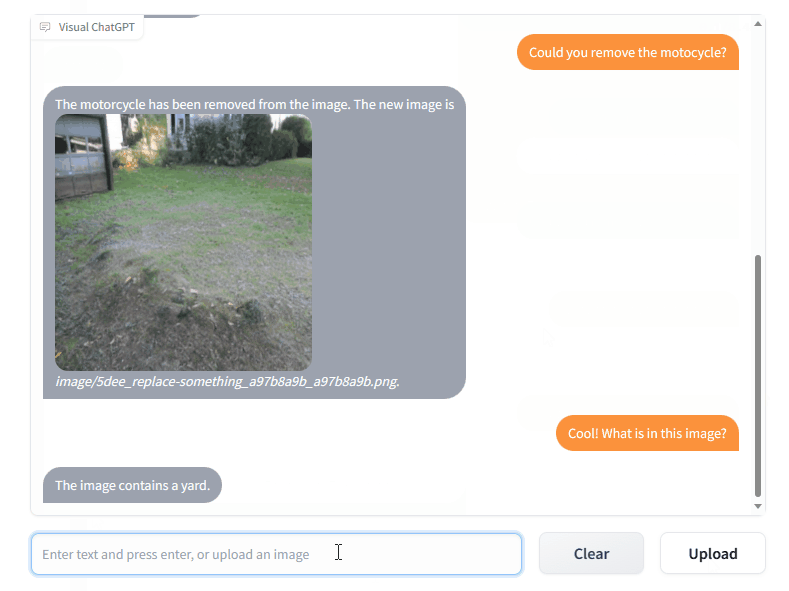
Visual ChatGPT allows us to use text prompts to control so-called Visual Foundation Models (existing models like Stable Diffusion, ControlNet, Pix2Pix, and others) that are included in the Visual ChatGPT framework.
This gives Visual ChatGPT completely new capabilities, for example:
- understanding images and providing the description of an image (via the BLIP foundation model)
- generate images (via the Stable Diffusion foundation model)
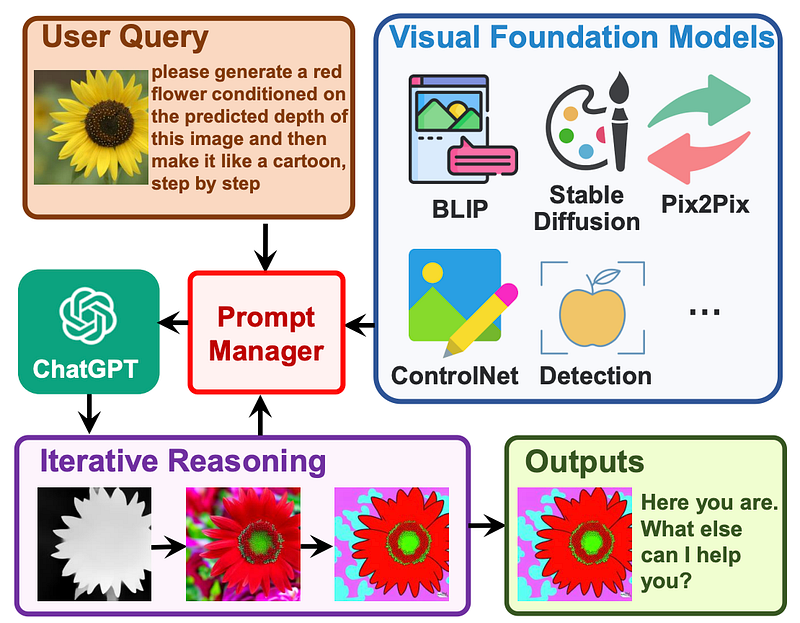
Here are some examples of experiments conducted by the Visual ChatGPT research team. As you can see, not everything is working as expected, but building a ChatGPT-like interface with access to visual foundation models is actually a sneak peek into the upcoming paradigm of multimodality.
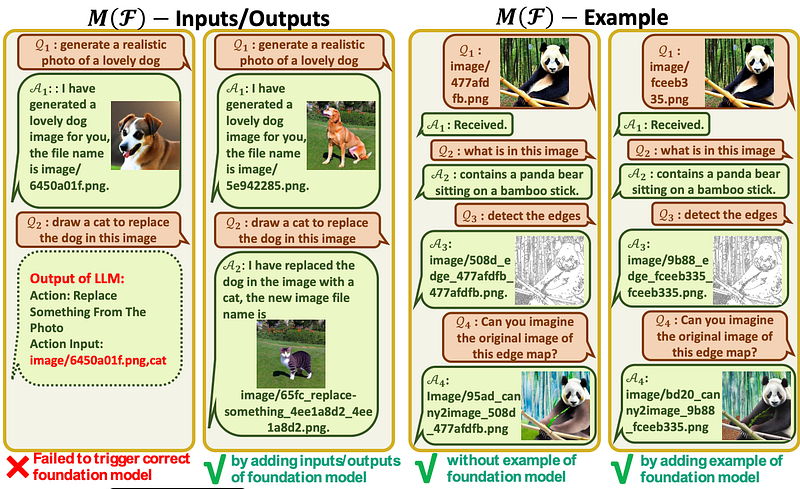
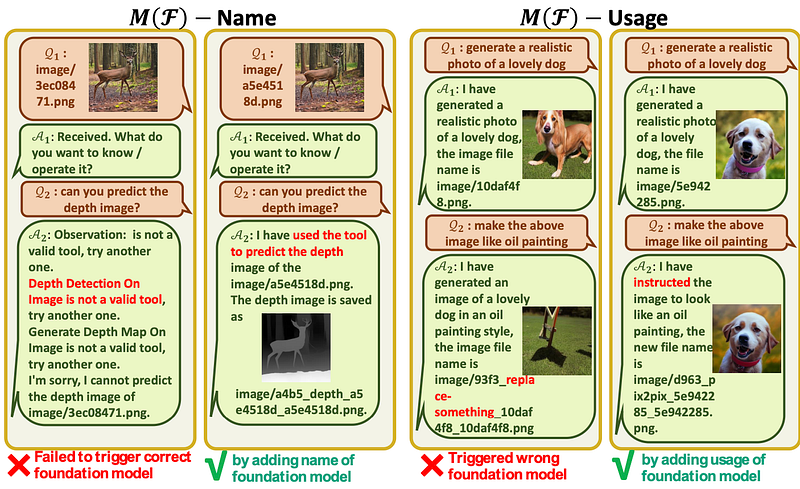
How to use Visual ChatGPT
If you have some 50GB of disk space ready you can clone it here (attention Mac users you’ll need this workaround). Otherwise you can use one of the online demos below or the Google colab.
Link to GitHub repo: https://github.com/microsoft/visual-chatgpt/
Link to Huggingface demo: https://huggingface.co/spaces/RamAnanth1/visual-chatGPT
Link to Google colab: https://colab.research.google.com/drive/11BtP3h-w0dZjA-X8JsS9_eo8OeGYvxXB
Link to original paper: https://arxiv.org/abs/2303.04671
➡️ If you like my content, why not leave a “clap” at the end of this article, so more people can see it?