
What is Groq AI — Worlds fastest LLM & serious problem for ChatGPT? Shows what AI Custom Silicon can do
Groq’s AI focussed chip design not just troubles NVIDIA, AMD but also many models including ChatGPT & Gemini. With claim of 500 tokens/second, it is also way cheaper to run

Groq is a semiconductor company found in 2016, by former members of Google’s TPU team. Groq is focussed on delivering the lowest possible latency for AI inference. For this they moved away from GPU (like NVIDIA chipsets) to develop their own LPU (Language Processing Unit).
They bundle their custom made chips for AI with turnkey generalized software and a deterministic Tensor Streaming architecture to bring a complete ecosystem. They even have their own “GroqCloud”.
And to clarify, Elon Musk’s Grok is a different entity. Groq has raised a total of $350+M in funding over 5 rounds.
Few Tech Details

Their model is powered by their own chip called GroqChip™ , which is a first generation & we can expect more to come in the future. Their Language Processing Unit™ (LPU), is a new processor category developed by them and they claim that is one of the key ingredient of their secret sauce.
Currently Groq provides two models Llama 2 70B-4K and Mixtral 8x7B 32K. And we can also see a third model Mistral 7B-8K, but its currently not available at the time of writing.
It reads very fast and generating words like crazy. The speed is clearly visible when we test it.
Groq claims that they can breach 500 tokens per second and we know that ChatGPT 3.5 was around 75 tokens per second.
About GroqChip™
Groq have achieved this feat with a specialized processor for inference, which they call LPU, as mentioned above. GPUs were already improving speed over CPUs, but LPUs even better as per Groq.
LLM’s have two bottlenecks, compute density and memory bandwidth. Groq’s LPU has greater compute capacity than not just CPU, but even better than GPU. This results in reduced time per word. Also, Groq eluminates external memory bottleneck with its custom silicon enabling LPU inference engine to deliver performane which are orders of magnitude better on LLMs compared to GPUs.
Tough time for NVIDIA. Even tougher time for Microsoft, Meta and others who have placed orders with NVIDIA. With the performances showcased, many will be willing to switch their compute infrastructure.
However, one catch is, Groqchips does not support training yet & only inference. Hence NVIDIA has still edge, as even AMD edges only in inference
This however, raises a serious question for companies, what will happen if another company launches even better hardware in 6 months ?
Guess there will be serious discussions in boardrooms on how to spend the capital.
About Privacy
When it comes to privacy, their statement is “Our promise to customers and prompt engineers is always and forever to make it real. No hype. No vaporware. No bullshit.”
And they don’t even want you to signup. You can straight away start with prompting on their website
Testing the 500 token/second claim
I tested, whether it actually gives 500 tokens per second after the recent CEO announcment of enhanced throughput. Many of the tests done prior to the CEO announcement showed that was close but not breaching the 500 tokens/second
However, as given in the below screenshot, I was able to get more than 500 tokens per second using Mixtral 7x7B-32K model.
And its a whooping 525+tokens/second.

I agree, the test I have made is not performance intensive or to push the limits.
However, tests done by Artificial Analysis, shows that if ChatGPT runs on GroqChip™ instead of NVIDIA’s, it can run 13X faster. . .
AI LLM inference will never be the same
Groq has demonstrated 18x faster LLM inference performance on Anyscale’s LLMPerf Leaderboard & claims to be the world’s fastest inference engine as given below,
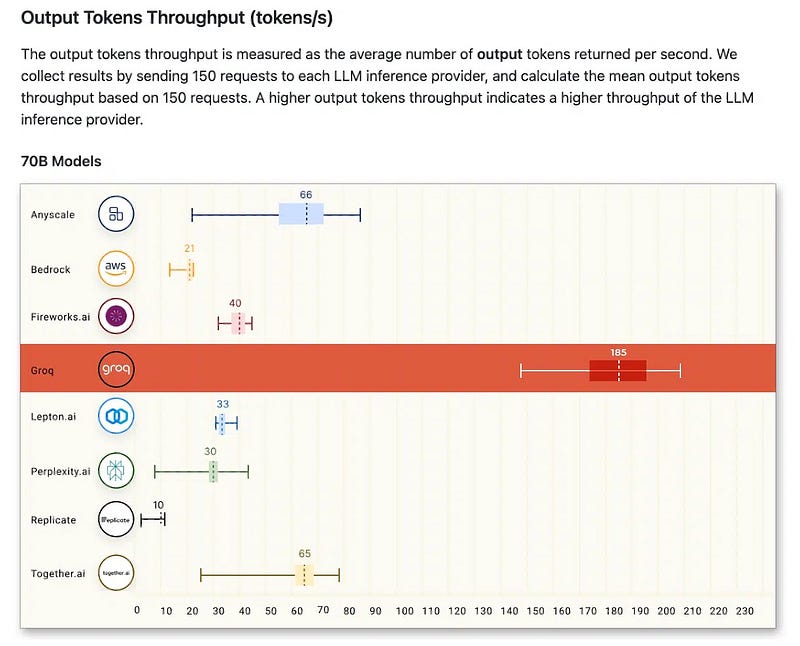
IMO, even the tokens per second claim, is not exciting as the next claim, cheaper to run.
About Cost
Groq provides 10 day free trial with the ability to refresh upon request. One will get 1 million free tokens during the trial.
More importantly, Groq API is fully compatible and can be easily switched from OpenAI API — So. . . .
After free trial, you get the cheapest running cost as given below in their website during the time of writing.
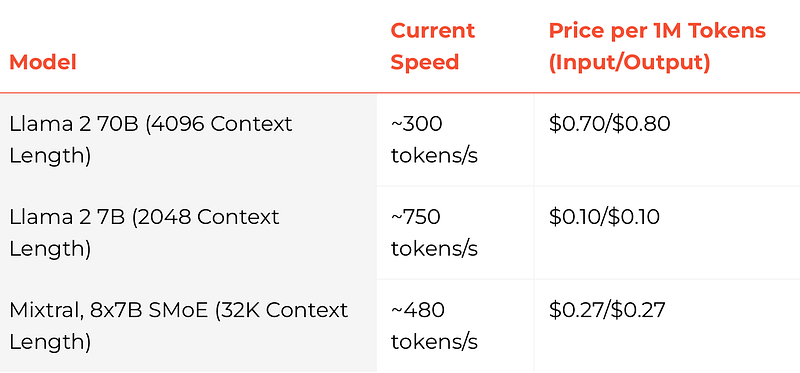
Whats more ? Groq guarantees to beat any published price per million tokens by published providers of the equivalent listed models.
Guaranteed cheap price & easily switchable from OpenAI — ya, I know, where this is going
And dont forget, they offer their own compute racks to big players like Microsoft, Meta if needed. And they claim they are currently capable of delivering 390 racks in 6–12 months and ramped lead times of 6–12 weeks
What about other Machine Learning Frameworks?

Groq states that they currently support PyTorch, TensorFlow, and ONNX for inference. However, they do not currently support ML training with the LPU Inference Engine.
So training is not possible, but inference is. Existing capital investments on NVIDIA & AMD can be still backed up.
Also, for custom development, Groq offers the GroqWare™ suite. The suite includes Groq Compiler which offers a push-button experience to get models up and running quickly.
If your application demands, you can even hand code to the Groq architecture & get fine control on any GroqChip™ processor. This can help in greatly optimizing workloads and maximize their custom application’s performance.
Conclusion
This week, they made another software update and claimed 2X more throughput achievement. And their CEO, Jonathan Ross, says they plan to release one more throughput enhancement in another couple of weeks. All this clearly shows Groq will definitely have significant boost for AI inference in coming days to come
Also, I am sure they will have further generations of their chip to get more juice. It must also be noted that, multiple other companies are trying custome made silicon for AI. Not to forget, even NVIDIA CEO announced this month that they are looking into custom silicon strategy.
With all these developments, AI is going to be more powerful at least in the LLM space for now.
Whats your opinion on Groq and the enhancements brought by custom silicon ?
Please also read my stories on NVIDIA H100 & recent OpenAI’s memory update.
Follow me for more stories on innovation & deep tech. Do you know you can give 50 claps for a story at a time, if you adore it ???

This story is published on Generative AI. Connect with us on LinkedIn and follow Zeniteq to stay in the loop with the latest AI stories. Let’s shape the future of AI together!
