
What is Database Sharding? Scaling Your Data Horizontally
A complete guide of database sharding, why use it and how it works for your system design interview.
Hello folks, in the ever-evolving landscape of data management, the ability to efficiently handle vast amounts of data is crucial for businesses and organizations.
Traditional monolithic databases often struggle to keep pace with the demands of modern applications and services and become performance bottleneck. This is where database sharding comes into play, offering a powerful solution for horizontally scaling your data.
In this comprehensive database sharding guide, you will learn about database sharding, exploring its concepts, benefits, implementation strategies, and real-world use cases.
P.S. Keep reading until the end. I have a bonus for you.
By the way, If you are preparing for System design interviews and want to learn System Design in depth then you can also checkout sites like ByteByteGo, Design Guru, Exponent, Educative and Udemy which have many great System design courses and if you need free system design courses you can also see the below article.
Table of Contents
- Introduction
- What is Database Sharding?
- Why Sharding? The Need for Scalability
- How Does Database Sharding Work?
- Sharding Strategies
- Challenges and Considerations
- Real-World Use Cases
- Implementing Database Sharding
- Best Practices
- Conclusion
1. Introduction
In today’s data-driven world, businesses and organizations are inundated with vast amounts of information. Managing and processing this data efficiently is a challenge that traditional monolithic databases struggle to meet.
As user bases grow, application workloads increase, and the demand for real-time analytics soars, the need for scalable database solutions becomes paramount.
This is where database sharding enters the scene as a powerful tool for achieving horizontal scalability.
2. What is Database Sharding?
Database sharding is a database architecture strategy used to divide and distribute data across multiple database instances or servers. The term “shard” refers to a partition or subset of the overall dataset.
Each shard operates independently and contains a portion of the data. By distributing data across multiple shards, a system can achieve horizontal scalability, allowing it to handle larger data volumes and higher workloads.
Sharding is especially beneficial for applications with rapidly growing datasets or high-throughput requirements, such as social media platforms, e-commerce websites, and gaming applications.
It enables these applications to distribute the database load across multiple servers or clusters, preventing any single database server from becoming a bottleneck.
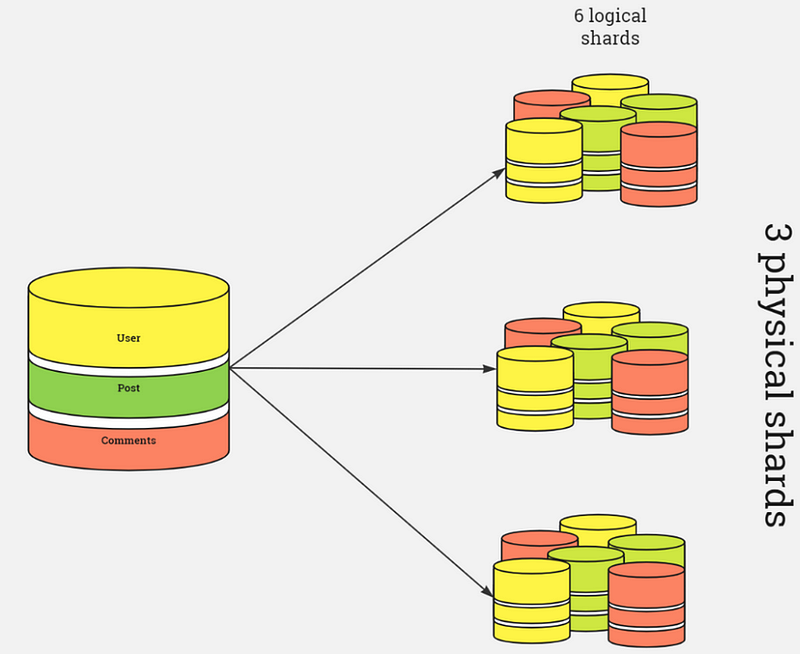
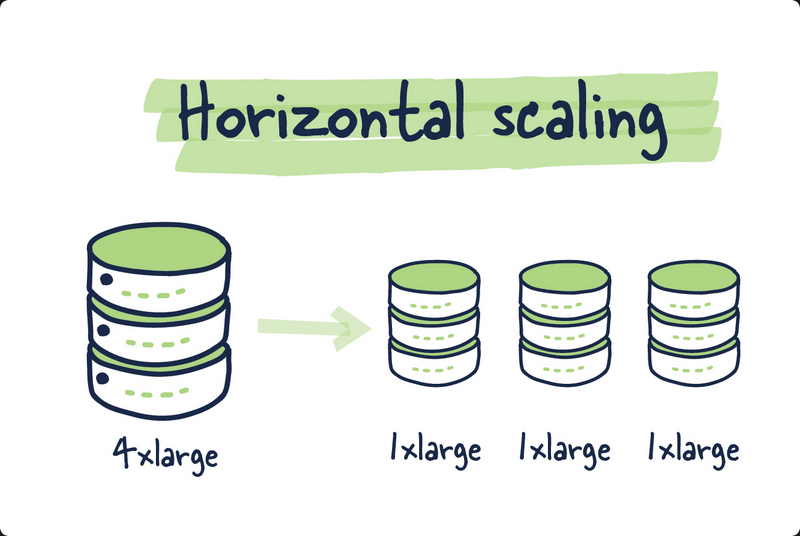
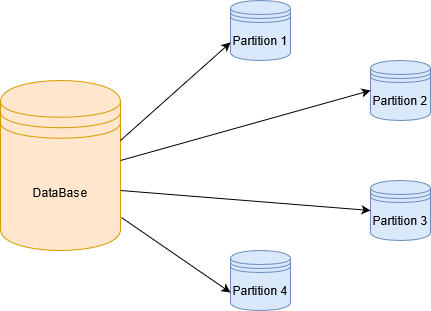
Here is a simple diagram which explains database sharding as Horizontal scaling:
3. Why Sharding? The Need for Scalability
Now, let’s see why do we need databse sharding
3.1. Scalability Challenges in Monolithic Databases
Traditional monolithic databases have limitations when it comes to scalability. In a monolithic architecture, all data is stored in a single database instance.
As data volume and user load increase, a monolithic database can face several challenges:
- Performance Bottlenecks: A single database server can become a performance bottleneck, leading to slow query response times and application downtime.
- Limited Storage: The storage capacity of a single server is finite, making it difficult to handle extremely large datasets.
- Vertical Scaling Costs: Scaling vertically by upgrading hardware can be expensive and has diminishing returns.
- Complexity: Managing a large monolithic database can be complex and error-prone, requiring extensive maintenance and optimization.
3.2. The Solution: Horizontal Scalability with Sharding
Database sharding addresses these scalability challenges by distributing the data across multiple shards, each residing on separate database servers or clusters. This approach offers several advantages:
- Improved Performance: Sharding spreads the database load evenly across multiple servers, resulting in better query performance and responsiveness.
- Infinite Scalability: As data grows, new shards can be added, allowing for nearly unlimited scalability.
- Cost-Effective: Sharding can be a cost-effective solution compared to continually upgrading a single server.
- High Availability: Sharding can improve fault tolerance and availability since the failure of one shard does not affect the entire system.
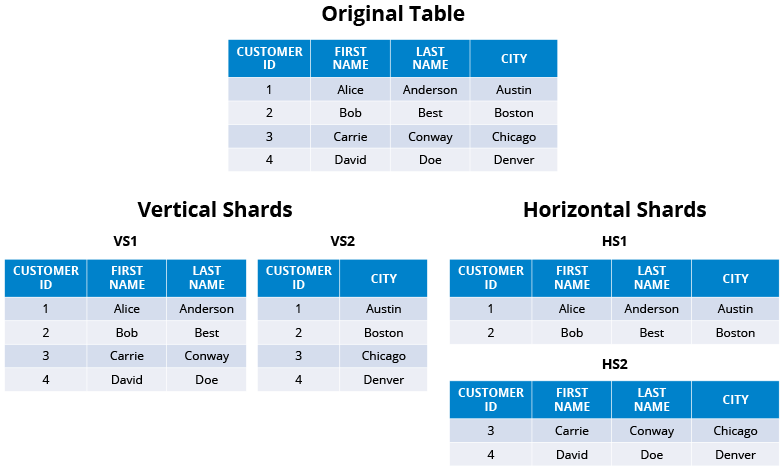
Here is how horizontal sharding and vertical sharding of database look like
4. How Does Database Sharding Work?
The core idea behind database sharding is to partition data into smaller, manageable pieces called shards. Each shard is a self-contained database subset that stores a portion of the overall dataset.
Shards can be distributed across multiple database servers or clusters, allowing for parallel processing and improved performance.
Here’s a high-level overview of how database sharding works:
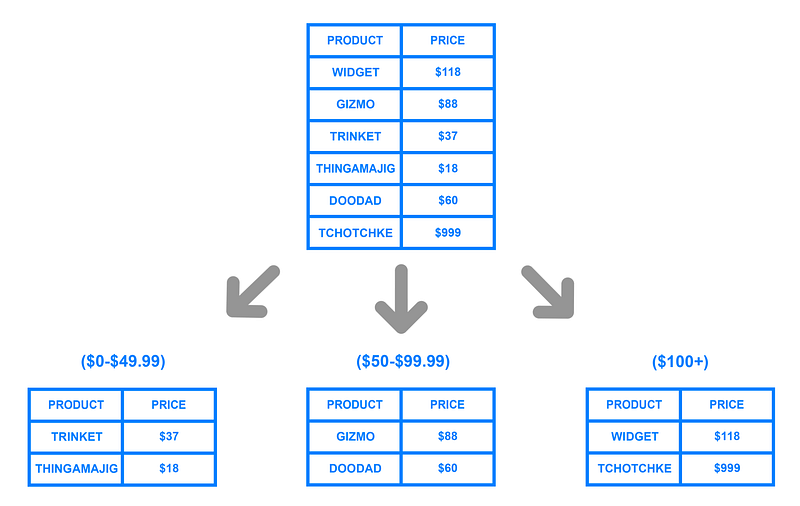
You can see that database sharding offers a logical way to split your data horizontally across multiple servers and clusters.
4.1. Data Partitioning
The first step in sharding is deciding how to partition the data. There are several common partitioning strategies, which we’ll explore in detail in the next section.
The choice of partitioning strategy depends on the application’s requirements and data distribution.
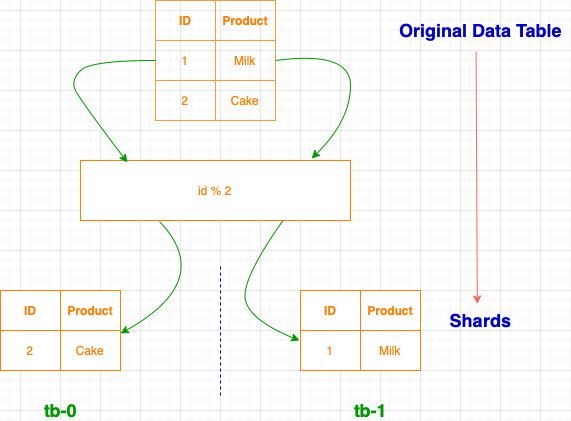
4.2. Shard Key
A shard key is a field or attribute used to determine which shard a particular piece of data belongs to. It’s essential to choose an appropriate shard key that evenly distributes data across shards to prevent hotspots (shards that receive significantly more traffic than others).
4.3. Data Distribution
Once the data is partitioned and a shard key is chosen, data is distributed among the available shards. The distribution process can be automated and typically involves a sharding mechanism or service that routes data to the correct shard based on the shard key.
4.4. Query Routing
When a query or request is made to the database, a query router or coordinator determines which shard or shards to query based on the shard key. Queries that involve multiple shards may require coordination and aggregation of results.
4.5. Aggregation
In some cases, query results from multiple shards may need to be aggregated to produce a final result. This aggregation can happen at the application level or through a dedicated aggregation layer.
4.6. Data Consistency
Ensuring data consistency across shards is a critical aspect of sharding. Techniques like two-phase commit or eventual consistency are used to maintain data integrity.
5. Sharding Strategies
Choosing the right sharding strategy is crucial for the success of a sharded database system. The choice depends on the nature of the data, access patterns, and scalability requirements. Here are some common sharding strategies:
5.1. Range-Based Sharding
Range-based sharding involves partitioning data based on a specific range of values in the shard key. For example, if you are sharding customer data, you might use a range-based strategy where each shard contains customers with last names starting with a specific letter or falling within a specific range.
Range-based sharding is useful when data distribution is not uniform, and you want to keep related data together within a shard.
5.2. Hash-Based Sharding
Hash-based sharding uses a hash function to map the shard key to a specific shard. This approach evenly distributes data across shards and helps avoid hotspots.
Hash-based sharding is particularly effective when data access patterns are unpredictable or when you want to ensure an even distribution of data.
5.3. Directory-Based Sharding
Directory-based sharding maintains a central directory that maps shard keys to their corresponding shards. This directory helps route queries to the appropriate shards efficiently. However, it can introduce a single point of failure.
Directory-based sharding is suitable for scenarios where you need to maintain a high level of control over shard assignment.
5.4. Geographical Sharding
Geographical sharding is relevant when dealing with location-based data, such as users’ locations. Data is partitioned based on the geographic regions associated with the shard key.
This strategy is valuable for applications with geographically distributed users or data.
And as they said, a picture is worth 1000 words, here is a nice diagram from Architecture Notes which explains different types of database sharding
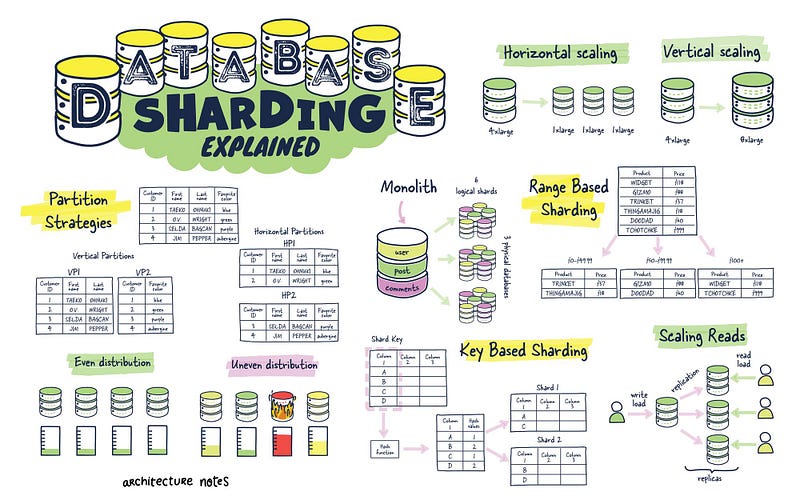
6. Challenges and Considerations
While database sharding offers significant benefits, it also comes with its set of challenges and considerations:
6.1. Data Migration
Migrating data between shards can be complex and time-consuming. Proper planning and tooling are essential to ensure a smooth migration process.
6.2. Backup and Recovery
Managing backups and ensuring data recovery across multiple shards requires careful planning and robust backup solutions.
6.3. Query Complexity
Queries that involve data from multiple shards can be complex to implement and optimize. Application code may need to handle query routing and result aggregation.
6.4. Data Consistency
Maintaining data consistency in a sharded environment can be challenging. Developers need to consider factors like distributed transactions, conflict resolution, and eventual consistency.
6.5. Monitoring and Scaling
Effective monitoring and scaling strategies are essential to ensure the health and performance of a sharded database. Identifying performance bottlenecks and adding new shards as needed is crucial.
7. Real-World Use Cases
Database sharding is employed in various real-world scenarios where scalability and performance are paramount. Let’s explore a few notable examples:
7.1. Social Media Platforms
Social media platforms like Facebook, Twitter, and Instagram handle massive amounts of user-generated content, including posts, images, and videos. Sharding enables these platforms to distribute and manage user data efficiently.
7.2. E-commerce Websites
E-commerce websites face intense traffic fluctuations, especially during sales events. Sharding helps them handle increased loads and deliver a seamless shopping experience.
7.3. Gaming Applications
Online gaming applications often require real-time interaction and low-latency response times. Sharding ensures that game data is distributed for optimal performance.
7.4. Financial Services
Financial institutions process vast amounts of transaction data daily. Sharding allows them to scale their databases to handle the load while maintaining data integrity.
8. Implementing Database Sharding
Implementing database sharding requires careful planning and execution. Here are the steps involved:
8.1. Assessment and Planning
Begin by assessing your application’s scalability requirements and data distribution patterns. Choose an appropriate sharding strategy and shard key.
8.2. Database Design
Design your database schema to accommodate sharding. Define how data will be partitioned and distributed across shards.
8.3. Sharding Implementation
Implement the sharding mechanism or use a sharding database system that suits your chosen strategy. Distribute existing data across shards.
8.4. Query Routing
Develop a query routing mechanism that directs queries to the appropriate shards based on the shard key. Handle query aggregation if necessary.
8.5. Data Consistency
Implement data consistency mechanisms, such as distributed transactions or eventual consistency, to maintain data integrity.
8.6. Testing and Optimization
Thoroughly test the sharded database system, optimize queries, and monitor performance. Scale the system as needed.
9. Best Practices
To make the most of database sharding, consider these best practices:
- Choose the Right Shard Key: Select a shard key that evenly distributes data and avoids hotspots.
- Monitor and Scale: Continuously monitor the health and performance of your sharded database. Add new shards as your data grows.
- Backup and Disaster Recovery: Implement robust backup and recovery procedures to safeguard your data.
- Data Migration: Plan data migration carefully and use efficient tools and processes.
- Query Optimization: Optimize queries for performance in a sharded environment.
- Data Consistency: Understand and implement the appropriate data consistency model for your application.
System Design Interview Resources
If you are preparing for System design interviews and want to learn System Design in depth then you can also checkout sites like ByteByteGo, Design Guru, Exponent, Educative and Udemy which have many great System design courses and if you need free system design courses you can also see the below article.
10. Conclusion
That’s all about Database sharding and how it works. Database sharding is a powerful strategy for achieving horizontal scalability and handling large volumes of data and high workloads.
By distributing data across multiple shards, organizations can improve performance, ensure high availability, and meet the demands of modern applications.
However, sharding is not a one-size-fits-all solution and comes with its own set of challenges and considerations. Proper planning, careful implementation, and adherence to best practices are key to successful sharding.
As data continues to grow in volume and complexity, mastering the art of database sharding becomes increasingly important for businesses and developers alike.
Other System Design Articles you may like
Bonus
As promised, here is the bonus for you, a free book. I just found a new free book to learn Distributed System Design, you can also read it here on Microsoft — https://info.microsoft.com/rs/157-GQE-382/images/EN-CNTNT-eBook-DesigningDistributedSystems.pdf






