
What is a cosine similarity matrix?
Cosine similarity and its applications.
Cosine similarity is a metric used to determine how similar two entities are irrespective of their size. Mathematically, it measures the cosine of the angle between two vectors projected in a multi-dimensional space.
When we say two vectors, they could be two product descriptions, two titles of articles or simply two arrays of words.
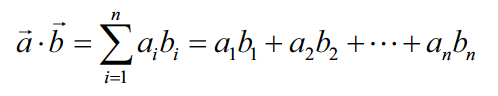
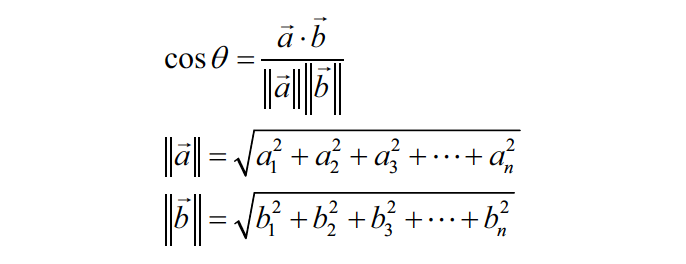
Mathematically, if ‘a’ and ‘b’ are two vectors, cosine equation gives the angle between the two.
Example:

This will give us the depiction below of different aspects of cosine similarity:
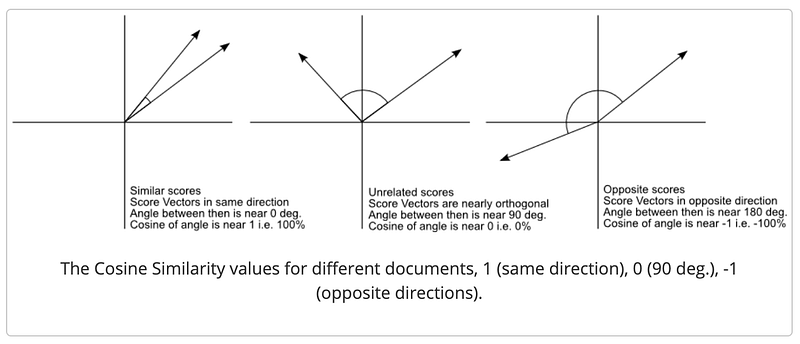
Let us see how we can compute this using Python. We have the following five texts:
#Define Documents
Document_A: Alpine snow winter boots.Document_B: Snow winter jacket.Document C: Active swimming briefs.Document D: Active running shorts.Document E: Alpine winter gloves.
These could be product descriptions of a web catalog like Amazon. To compute the cosine similarity, you need the word count of the words in each document. We use the CountVectorizer or the TfidfVectorizer from scikit-learn.
# Scikit Learn
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
# Create the Document Term Matrix
count_vectorizer = CountVectorizer(stop_words='english')
count_vectorizer = CountVectorizer()
sparse_matrix = count_vectorizer.fit_transform(documents)# Similarity between the first document (“Alpine snow winter boots”) with each of the other documents of the set:from sklearn.metrics.pairwise import cosine_similarity
cosine_similarity(sparse_matrix[0:1], sparse_matrix)
array([[ 0.50305744 , 0.16651513, 0.62305744, 0.13448867]])This is how we can find cosine similarity between different documents using Python.
Applications:
- As shown above, this could be used in a recommendation engine to recommend similar products/movies/shows/books.
- In Information retrieval, using weighted TF-IDF and cosine similarity is a very common technique to quickly retrieve documents similar to a search query.
- The cosine-similarity based locality-sensitive hashing technique increases the speed for matching DNA sequence data.
Important links for reference:
- Understanding TfidfVectorizer: Scikit-learn
- Spatial Distance Cosine: Scipy
- ML Book: ML Solutions
Subscribe to our Acing AI newsletter, I promise not to spam and its FREE!
Thanks for reading! 😊 If you enjoyed it, test how many times can you hit 👏 in 5 seconds. It’s great cardio for your fingers AND will help other people see the story.





