
What is a Star Schema?
In a Nutshell: The OLAP Data Warehouse Standard

The Star Schema has become the standard for mapping multidimensional data structures in relational databases and is used primarily in Data Warehouses and OLAP apps. This article gives you a short overview and what you have to know about it.
Theoretical Background
The Star schema attempts to minimize the large number of tables typical in the relational model. The name Star schema comes from the fact that the tables are arranged in a star shape.
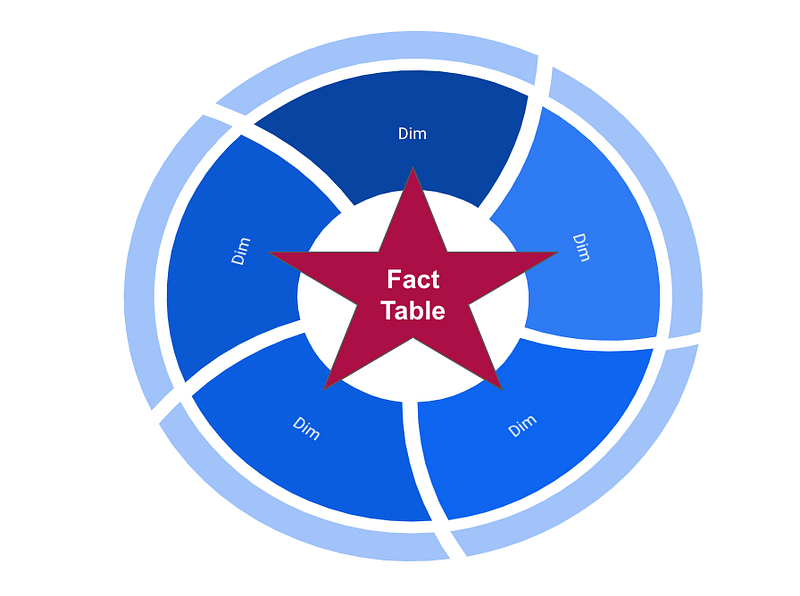
Two different types of tables must be distinguished: The center is the fact table, various dimension tables are grouped around, creating the whole star schema.
Technical Implementation
The fact table is used to store numbers or derived quantities, such as sales or costs. From a cube perspective, it contains the cube core. The dimension tables contain the qualitative data for visualizing the dimensions and dimension hierarchies.

The individual rows of a dimension table are identified by a minimal attribute combination, the primary key. To establish the relationship between the dimension tables and the associated fact tables, the primary keys of the dimension tables are included in the fact table as foreign keys, where they in turn together form the primary key of the fact table.
Relevance in the Field of Data Science
As mentioned before, the Star schema is the schema for classic often OLAP based databases and Data Warehouses, but new technologies like NoSQL Data Beacons and Data Lakes often make these classic approaches obsolete, so the relevance here should decrease. However, Star-based databases are often in operation at companies and will probably remain so for a while, so that at least as a modern data engineer or scientist you should know the basics.
Pros and Cons of Star Scheme
Some of the most important advantages of a star schema are [2]:
- Fast query processing: Analytical queries are typically at higher aggregation levels and by not normalizing the dimension tables, joins are saved.
- Data volume: Dimension tables are very small compared to fact tables. The additional data volume due to a denormalization of the dimension table does not have to be considered.
- Change anomalies can be easily controlled, since there are hardly any changes to classifications.
However, there are also some disadvantages existing [2]:
- Deteriorated response time behavior for frequent queries of very large dimension tables.
- Redundancy within a dimension table due to multiple storage of identical values or facts.
- Aggregation formation is difficult.
Summary
I hope this article gave you some helpful insights regarding the topic of Star Scheme. In the area of OLAP and Data Warehousing it is regarding as a standard and has its advantages especially in terms of speed. Due to newer technologies, this approach will lose its relevance in the future. NoSQL databases and Data Lakes with new approaches are on the rise. Nevertheless, as a data engineer or scientist, you should be aware of this topic, since you will still often find databases with a Star schema as source systems.
Sources and Further Readings
[1] Microsoft, Understand star schema and the importance for Power BI (2021)
[2] Wikipedia, Star schema (2021)





