
What is a Smart Contract ABI anyways? — A guide to understand client-blockchain communication
As you step into Smart Contract development for EVM-compatible chains such as Ethereum or Binance Smart Chain, one of the most difficult tasks to do is getting familiar with how things actually work, and while researching, one of the worst explained concepts and that carries a lot of questions are the Smart Contract’s ABIs.
This section is almost never explained because the fun thing is to create Smart Contracts in Solidity or to use Web3.js to connect an interface to it, but there’s a great reason for it to exist.
For Smart Contract and DApps development things are usually different from the well-known and hardly used client-server model, right? There are no API and database models. Also, you don’t have anywhere to call with a fetch call, isn’t it?
All you have to do is instantiate a Smart Contract using Web3 (or any equivalent) like this:
const Contract = require('web3-eth-contract');Contract.setProvider('http://localhost:8546');
const contract = new Contract(abi, address);
contract.methods.somFunc().send({from: ....})Well, turns out things are not exactly the same, but, once you understood its principles, is more familiar than what you might think, and the Smart Contract’s ABI is a fundamental piece of the client-blockchain communication puzzle.
Let’s revisit some basics.
How does a UI communicate with a blockchain node?
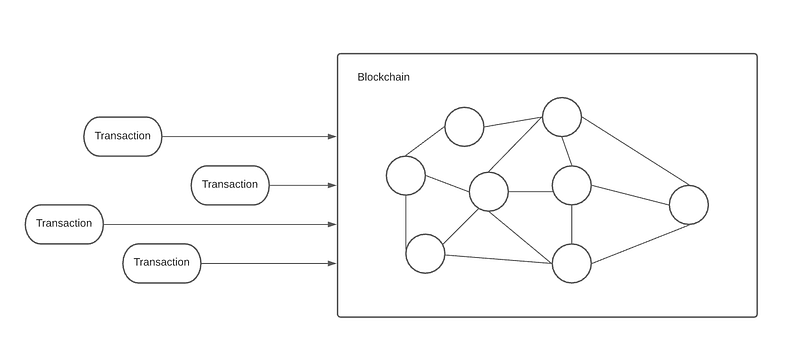
As you may know, blockchain is composed of its nodes, the so-called clients, that are basically just infrastructure of computers connected P2P on the network and each one has ideally the copy of the entire blockchain.
These clients communicate with each other and send information about transactions and blocks, including function calls and contract execution, but they receive those function calls and executions from the outside.
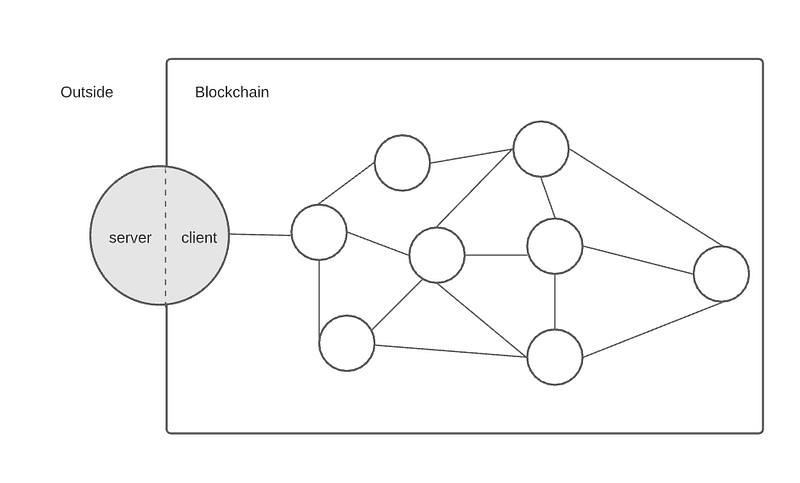
Under this model, any client becomes an actual server, because those transactions need to be received somehow in order to be processed, which is in fact an HTTP endpoint that each one of the nodes can decide to expose or not depending on their interests.
If you’ve programmed a DApp before, you might’ve used Infura, which is an Infra-as-a-service platform that provides you a connection to the Ethereum blockchain in just a few clicks, and it provides an HTTP endpoint to use as a provider within the web3 library of your preference.
This HTTP endpoint is a JSON-RPC server that responds to a set of calls that can be sent to any client with it enabled, and it has a lot of RPC methods available to get relevant information about the node such as the block_number or the latest_block just to mention some of them.
One of these JSON-RPC methods is the endpoint that receives and processes transactions. eth_sendTransaction is the method used when you’re sending ETH to somebody else’s account, but, more importantly, it is also the same method used when you interact with any smart contract, as every function call or contract interaction is a transaction as well.
This means that, when interacting with any EVM blockchain, if you pay attention, every UI such as Metamask will show you the transaction details for every time you use a Smart Contract.
The key to understand how the ABI works is to understand how these types of transactions really work.
How do we call a function using a transaction?
The main difference between a normal transaction and a function call to a Smart Contract is that one is just a plain from-to state change and the other includes an extra attribute called data that has enough information for the node to process it and execute the function at the contract.
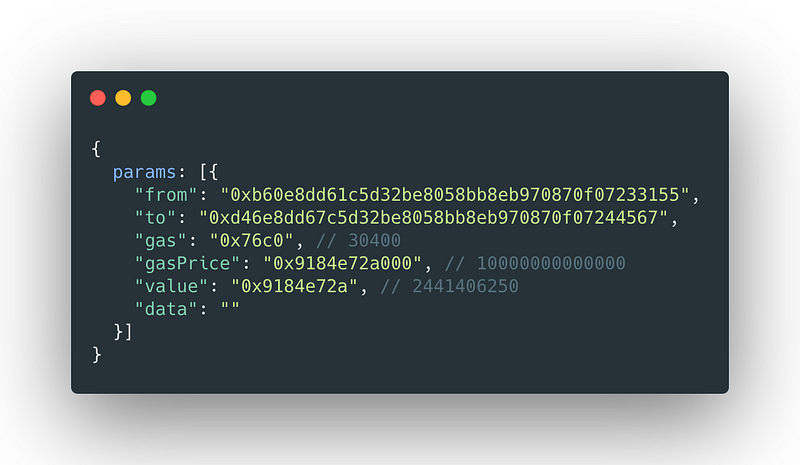
The data field is completely empty for transactions that only send ether from account to account, but how data is constructed for method calls is the interesting part, and it's the way to understand the ABI’s role.
In order to construct a transaction that calls a function, it is needed to follow the ABI specification, which is the guide to construct the data field of a transaction based on the function of the contract you want to call and the parameters you’re providing.
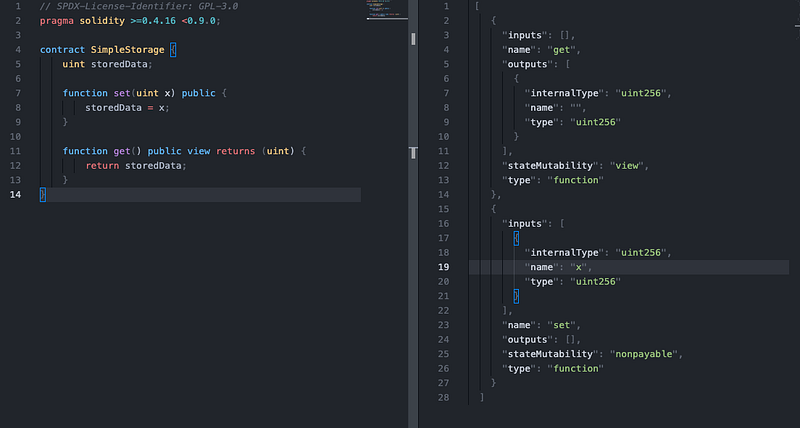
Let’s say you have a basic ERC20 transfer function like this:
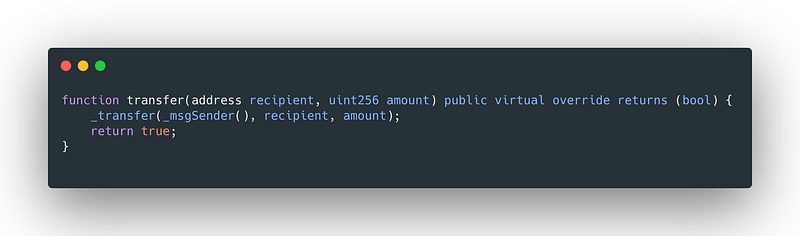
According to the ABI spec, the data should include the following information:
- A function selector: This is a unique identifier for the function of the contract you want to call, which in this case corresponds to transfer, but is not provided like that for a reason. I’ll go further into that later.
- Arguments encoded: That includes the list of arguments provided to the function. In the case of the transfer, they’ll just be recipient and amount
The way data is constructed to send with the transaction is this:

And it usually looks like this:
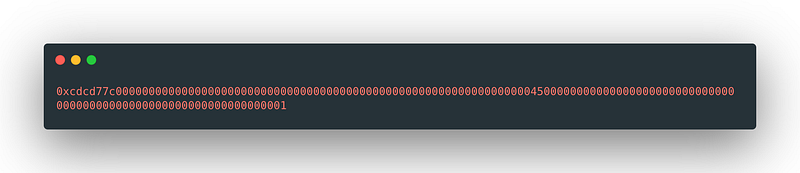
There are two fundamental problems with this approach:
- How is the MethodID constructed? How does the EVM knows that the MethodID corresponds to the function we’re trying to call?
- How does the EVM know when does the MethodID ends? What about the first param? Actually, how does it knows that there are no 2 or 3 params in that
datacall?
Let’s see:
Calculating the MethodID
Probably the first thing you may think that can be used to identify a function is its name, but in Object Oriented languages such as Solidity, there are functions with the same name but with different parameters, this is a way of function polymorfism.
As an example, you can have something like this in Solidity:

This allowance of Solidity to declare multiple same-named functions will screw up the EVM if we decide to identify functions just by its name, so we need something else, and that’s where the function signature enters.
According to the docs, the function signature:
… is defined as the canonical expression of the basic prototype without data location specifier, i.e. the function name with the parenthesised list of parameter types. Parameter types are split by a single comma — no spaces are used.
In plain English, it means that the signature is the name and its parameter types, so for our example, the signatures will look like this:

That’s enough to differentiate them, but we need an extra step. What if somebody decides to write a huge function signature? Wouldn’t that be unfeasible? Yes, especially if we think that a Smart Contract is space written on the blockchain, thus, it may get expensive in terms of gas.
According to the ABI specification, the method ID is:
…the first 4 bytes of the Keccak hash of the ASCII form of the signature
Since this is how it’s stored and identified on the EVM memory, it is also a great way to generate a unique identifier for different functions even though its name is the same.
So, getting back to our transfer function, the process would look like this:
- We get the signature for the function which is transfer(address, uint256)
- We take that string and hash it using Keccak256 hashing algorithm. The result should be a9059cbb2ab09eb219583f4a59a5d0623ade346d962bcd4e46b11da047c9049b
- From that hash, we use only the first 8 digits (4 bytes since the hash is in HEX) and the result would be a9059cbb
a9059cbb is the well know function identifier for every ERC20 transfer, and actually this is how Metamask or other services know that you’re transferring a token and show you a slightly different interface.
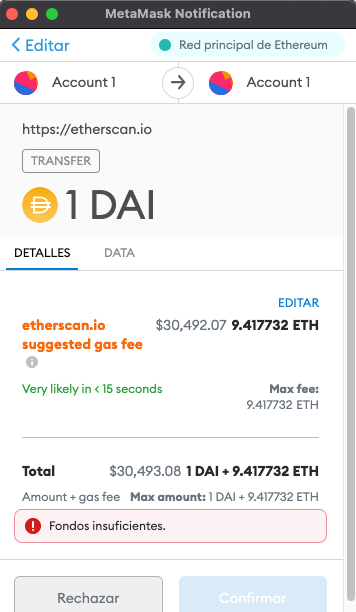
Now that you have the methodID, the way to solve the problem of knowing the size of the params is automatically done by the EVM, but it needs some help from our side.
As you might know, if you’ve been playing around with Solidity, there are different sizes for data types like uint (8, 16, 32). This is a well-known feature of Solidity and is commonly used to save some gas while interacting with the contracts, that means that our transactions should reflect that difference in size.
That means that even though we’re sending only 1 DAI in our example with metamask, this is an integer of 256 bites (32 bytes), so we should provide the actual size of the integer in order to make the EVM to process correctly the parameter we’re providing, so, our 1 DAI (with 18 decimals) will look like this:

Note that it adds extra padding at the left to the number so its size it what a uint256 should be in bytes.
That means that at the end, our entire data chunk should look like this once constructed using the methodID and its params with their respective sizes (address is always 32 bytes in size):

Now that you know that a client is also a server that exposes an HTTP endpoint to receive JSON-RPC calls that include sending transactions with data encoded to call Smart Functions, then it’s time to answer…
What’s the ABI for?
It’s basically a representation of the function and returns types of your Smart Contract, and, as you can see, it includes the main needed information to construct the function signatures, and therefore, the data needed.
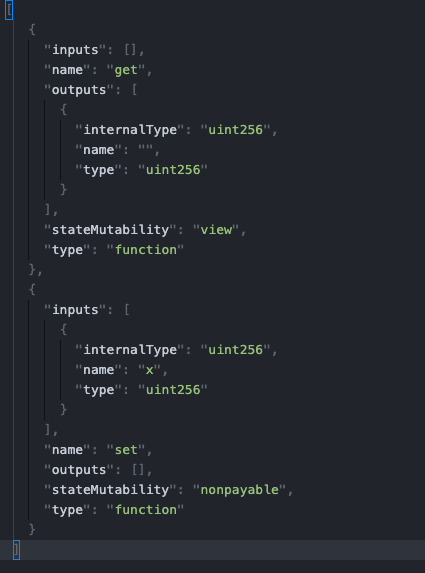
As its name states, it is an Application Binary Interface that tells web3 how to construct the data to send in the call of an eth_sendTransaction JSON-RPC call.
Since we don’t have traditional REST APIs, JSON RPC is the equivalent for a web application, and it requires you to know how to communicate with it, which includes the transformation of the function calls into transactions with the correct data encoded.
It is used inside of web3 to construct the functions needed with the same names and internally translates to the actual Ethereum client calls.
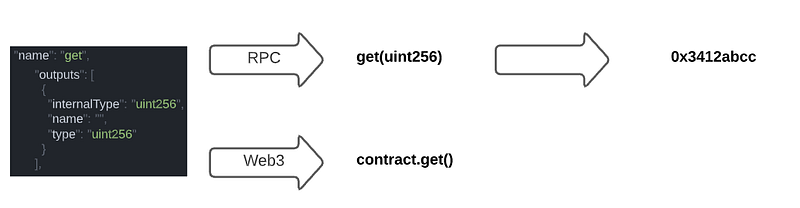
Also, you may notice that it includes the return type of the function, and this is because a server can return your data but it is also HEX encoded, so before Web3 returns you the actual value, it has to know whether if what it returned is a uint, address, string or whatever.
Conclusion
While using web3 to interact with Smart Contracts in our applications, it may look too easy to just instantiate the contract and call some methods with it, but there are a lot of processes happening under the hood that enables the applications to send data to an Ethereum client with its JSON-RPC endpoint enabled.
The ABI is a JSON interface that serves the only purpose of representing a smart contract in a standard way that is understandable for any Web3 client and also parseable to an eth_sendTransaction RPC call that any node can understand as well to retranslate values gotten back from the node.
Many of these processes happen under the hood, and they’re allowed to be done because the ABI is the standard tool to abstract the complexity of communicating from the client to the blockchain..




