
What exactly happens when you new() an object
All you need to know about memory
The story
“Today I was asked about what happens when new() an object during the interview.” my friend said.
“Ok looks like a basic question, how did you answer,” I said.
“Yes, basic but not easy to answer”. he said.
“I talked about heap, object lifecycle, GC, reference counting,” he said.
“Well that should be good enough for a junior position. You do not have to mention virtual memory, swap, pages all those”.
“Yes but then that’s what my interviewer asked. ‘Do you know what exactly happens on the heap? And what will happen when there is not enough RAM on the heap?’ and I was stuck there”.
“Maybe he wants to touch the limit, should not affect your interview result,” I said.
Let’s discuss it today.
Memory structure
Before we talk about new() let’s look at memory structure when a process starts.
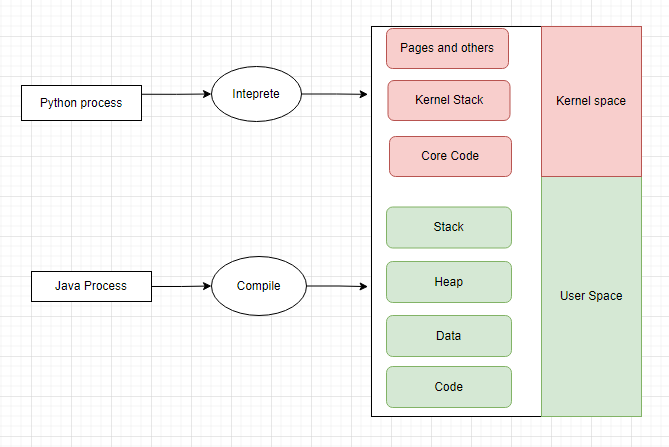
As we can see. after the code has been compiled or interpreted. It will be loaded into RAM. the RAM is located in the user space. 4 parts.
Code. binary code after compilation or interpretation.
Data. static variables(already initialized). for not initialized variables, will be loaded into BSS.
Heap. dynamic RAM allocation. yes, this is where new() object goes.
Stack. when we execute a function, the context (parameters, nested function call) will be loaded here and executed.
So It means that’s all? the heap is located on physical RAM? no.
Virtual Memory
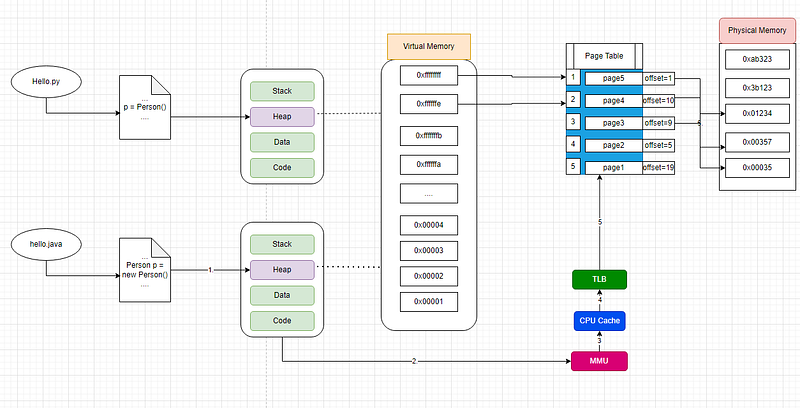
Okay couple of points. before the new() statement we can see 3 things.
- As we can see, every process has its stack, heap, data, and heap located in Virtual memory.
- Virtual memory, Page table, and Physical memory are shared by all processes
- Page table holding the mapping between virtual and physical memory. using these 3 pieces of information: virtual page number, physical page number, and physical address offset
when new() happens:
- RAM is dynamically allocated on the heap (user space) then MMU (one of the important units focused on memory mapping as we discussed here: from code execution to CPU instruction)
- It looks up in the CPU cache (as we discussed here) then TLB (Translate lookaside buffer), and if missed then query Page table.
- Get the exact physical address using page number mapping and offset
So will there be a waste to store all the mappings in one table? yes, a lot. so actually it is a multi-level table. below is a sample of the 2-level page table.
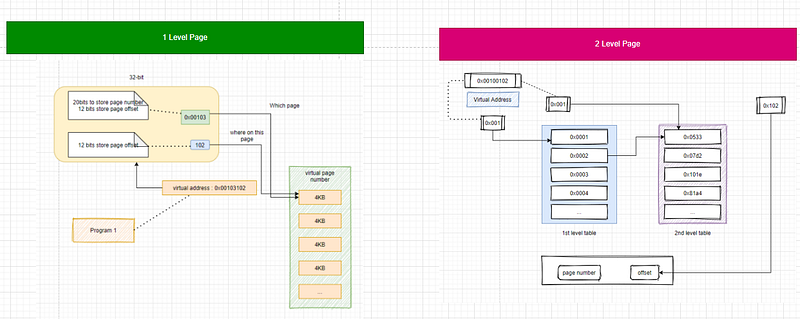
Before: using single page table. to server a process that needs 4GB Virtual RAM, and we assume every page size is 1KB.
total_space~(4,000,000 entries)~16MB(4000000 entries * 4bytes per entry)
using a 2-level page. page1_total_space~(1000 entries)~4KB(1000*4)=page_2_total_space. total=page1_total_space+page2_total_space=8KB
16MB VS 8KB. saved a lot. and to 64-bit OS. there will be 4-level pages (structure similar to above).
let’s move on to the next question.
What will happen to new() when there is not enough RAM
Before we talk about this case. think about this analogy.
Let’s say today you study at University, and there is a lecture for you to attend in class, so you go; in the middle of class, some other students come in (claim that there is a more urgent class) and ask you to continue this lecture next Wed.
This is what will happen in the swap.
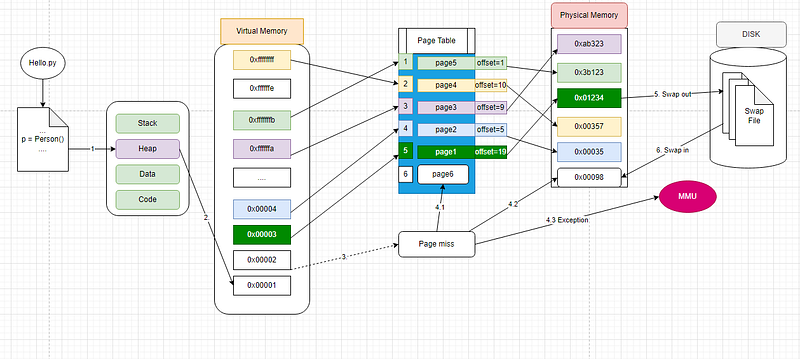
6 steps.
- when new() happens, allocate RAM on the heap
- virtual RAM mapping. page entry record missing in the page table
- A new page entry record was added to the page table
- Page miss exception triggers MMU
- Swap out the RAM data which is not being used at the moment
- Swap in RAM data for the current process
Wait, when will the trigger swap?
2 cases. when the system has pressure on RAM allocation, swap out the unused and swap in the being used; when the threshold setting is being triggered.
Since we do not want a swap to happen (I/O is slower than RAM), does it mean a swap threshold setting higher is better?
Generally yes. when your machine has enough RAM, and yes we do not want a swap to happen, set it higher. but when we have a busy server, or a stingy customer, which does not allow us to have a dedicated machine to run every service. The swap setting still makes sense, if the swap is not avoidable, SSD could be another optimization point.
But most importantly, write memory-efficient code and avoid memory leaks.
Wait. what does the SHR value mean from the top command?
What does the shared memory mean (SHR in top command)
Shared memory means “shared”. imagine you working in a startup, and there is a “shared office” like WeWork. and 1–2 days you need to return to the office, the rest you can WFH.
On the days when you return to the office, the meeting room, toilet, and pantry are shared.
Similarly, when we write 2 Python programs. both open and write files. so the Python libraries are shared.
To other memory outputs from the top command. RES means physical memory, VIRT is virtual memory, and yes SWAP is the swap space size.
As we talked about earlier, the “swap” value indicates the size of the swap space, which is a reserved area on the disk used when the physical RAM is fully utilized. When the system needs more memory than the RAM can provide, it swaps less-used data to the disk to free up RAM for more critical processes.
The final point.
GC
When an object is not being used, we want to release the RAM ASAP.
For programming like C or C++, we need to free it by ourselves. but if we use Python, c#, java, or golang. we have built-in GC. GC is not new, there are enough articles covering this topic well. here I highlight a few points for a quick summary.
Reference counting (Mark and delete), Generation based, Parallel. Reference counting is also known as mark and delete: a graph model, count in-coming edges (reference), remove the not-used objects (has zero references);
Generation-based (python, earlier version of C# or Java 6), it will first collect the younger ones, it turns to believe that the older generations will be more likely to live longer;
Roots and unreachable graphs. starts from every root, we can traverse a graph. so we need to store a root list. but what if some roots are unreachable? memory leak. a full scan of object graphs is very costly, so Java introduced Rset to solve this problem. to keep this post short, let's dive into it in another post.
For newer version GCs (.Net Server GC, java G1, golang), parallel execution is being used to speed up the process, they all aim to minimize pause times.
Those programming languages also provided something called “WeakReference”. The purpose is to maintain the reference counting manually and lower the GC load. generally, I am not recommended unless you know exactly what you are doing. instead of spending time to find a use case for WeakReference, why not spend time to cut the unnecessary usage (e.g. lazy loading, generate replace array) or avoid a full GC.
Last
That’s all. Hope it helps you answer the “new() question” in your programming language. Thanks for reading! see you in the next post.





