
What Are RBMs, Deep Belief Networks and Why Are They Important to Deep Learning?
In this article, we are going to take a look at what are DBNs and where can we use them.

A Deep Belief Network(DBN) is a powerful generative model that uses a deep architecture and in this article, we are going to learn all about it. Don’t worry this is not related to ‘The Secret or Church’, even though it involves ‘Deep Belief’, I promise!
After you read this article you will understand what is, how it works, where to apply and how to code your own Deep Belief Network.
Here is an overview of the points we are going to address:
- What is a Boltzmann Machine?
- Restricted Boltzmann Machine
- Deep Belief Network
- Deep Boltzmann Machine vs Deep Belief Network
What is a Boltzmann machine?
To give you a bit of background, Boltzmann machines are named after the Boltzmann distribution (also known as Gibbs Distribution and Energy-Based Models — EBM) which is an integral part of Statistical Mechanics and helps us to understand the impact of parameters like Entropy and Temperature on the Quantum States in the field of Thermodynamics. They were invented in 1985 by Geoffrey Hinton and Terry Sejnowski.
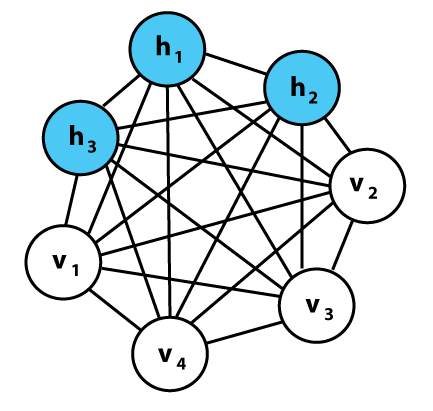
There are no output nodes! This may seem strange but this is what gives them this non-deterministic feature. They don’t have the typical 1 or 0 type output through which patterns are learned and optimized using Stochastic Gradient Descent. They learn patterns without that capability and this is what makes them so special!
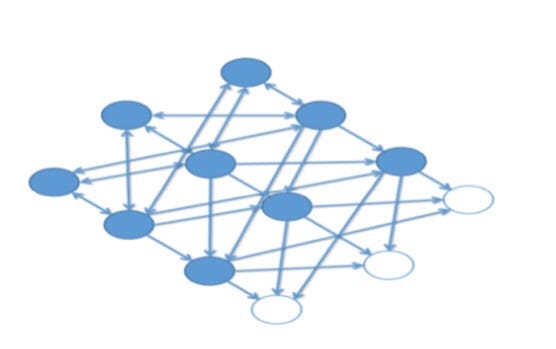
One thing to note, unlike normal neural networks that don’t have any connections between the input nodes, a Boltzmann Machine has connections among the input nodes. We can see from the image that all the nodes are connected to all other nodes irrespective of whether they are input or hidden nodes. This allows them to share information among themselves and self-generate subsequent data. We only measure what’s on the visible nodes and not what’s on the hidden nodes. When the input is provided, they are able to capture all the parameters, patterns and correlations among the data. This is why they are called Deep Generative Model and fall into the class of Unsupervised Deep Learning.
Restricted Boltzmann machine
RBMs are a two-layered generative stochastic building blocks that can learn a probability distribution over its set of inputs features( i.e. image pixels).
Note: First, they aren’t used as much nowadays if at all and second they aren’t themselves neural networks, they are used as building blocks, more on this on the next section.
RBMs were also invented by Geoffrey Hinton and has many uses cases such as dimensionality reduction, classification, regression, collaborative filtering, feature learning, and topic modelling.
As the name implies, RBMs are a variant of Boltzmann machines with a small difference, their neurons must form a bipartite graph, which means there are no connections between nodes within a group(visible and the hidden) which makes them easy to implement as well as makes them more efficient to train them when compared to Boltzmann Machines.
In particular, this connection restriction allows RBMs to use more efficient and sophisticated training algorithms than the ones available for BM, such as the gradient-based contrastive divergence algorithm.
In simpler terms, this means that we basically have fewer connections.
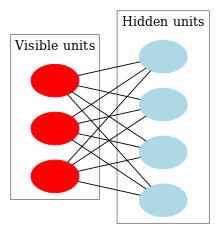
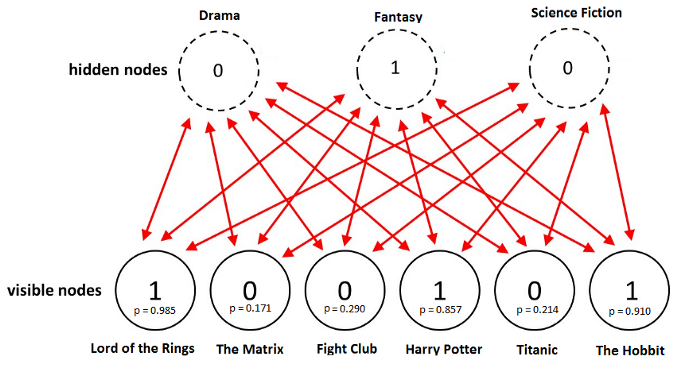
As shown in the figure above. RBMs hold two sets of random variables (also called neurons): one layer of visible variables/nodes(which is the layer where the inputs go) to represent observable data and one layer of hidden variables to capture dependencies(calculate the probability distribution of the features) of the visible variables.
Forward pass
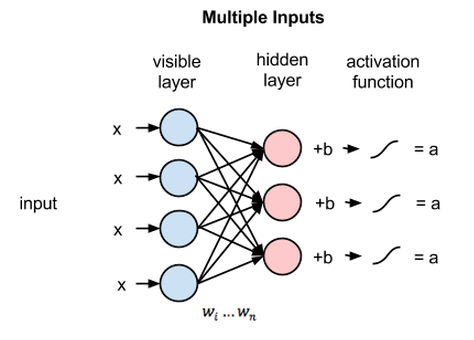
Backward Pass
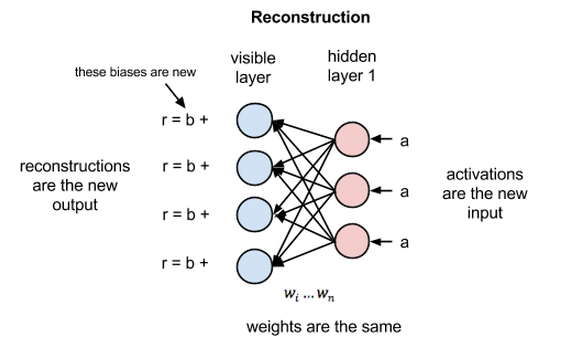
RBM is a stochastic building block (layer) which means that the weights associated with each neuron are randomly initialized then we perform alternating Gibbs sampling: All of the units in a layer are updated in parallel given the current states of the units in the other layer and this is repeated until the system is sampling from its equilibrium distribution.
Now Given a randomly selected training image 𝑣, the binary state ℎ𝑗 of each hidden unit 𝑗, is set to 1 where its probability is:
𝑃(ℎ 𝑗 = 1|𝒗) = ℊ (𝑏𝑗 + ∑i V𝑖 . W𝑖𝑗 ) — (12)
Where ℊ(𝑥) is the logistic sigmoid function ℊ(𝑥) = 1/(1 + exp(−𝑥)). Therefore 𝑑𝑎𝑡𝑎 can be computed easily.
Where 𝑊𝑖𝑗 represents the symmetric interaction term between visible unit 𝑖 and hidden unit j, 𝑏𝑖 and 𝑎i are bias terms for hidden units and visible units respectively.
Since there are no direct connections between visible units in an RBM, it is very easy to obtain an unbiased sample of the state of a visible unit, given a hidden vector
𝑃(𝑣𝑖 = 1|𝒉) = ℊ (𝑎𝑖 + ∑j ℎ𝑗 W𝑖𝑗 ) — (13)
However computing 𝑚𝑜𝑑𝑒𝑙 is so difficult. It can be done by starting from any random state of the visible units and performing sequential Gibbs sampling for a long time. Finally due to impossibility of this method and large run-times, Contrastive Divergence (CD) method is used.
Contrastive Divergence (CD)
Since Gibbs sampling method is slow, Contrastive Divergence (CD) algorithm is used. In this method, visible units are initialized using training data. Then binary hidden units are computed according to equation (12). After determining binary hidden unit states, 𝑣𝑖 values are recomputed according to equation (13). Finally, the probability of hidden unit activation is computed and using these values of hidden units and visible units, 𝑚𝑜𝑑𝑒𝑙 is computed.
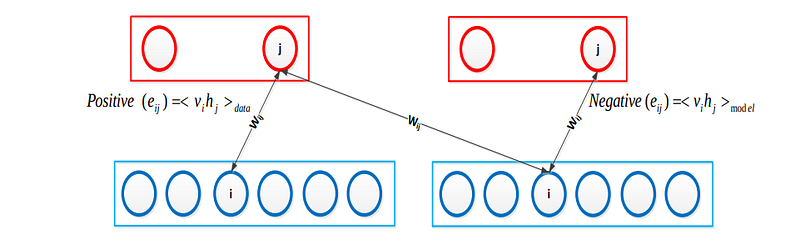
Figure 3: Computation steps in CD1 method.
𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒 (𝑒𝑖𝑗) is related to computing 𝑑𝑎𝑡𝑎 for 𝑒𝑖𝑗 connection.
Negative (𝑒𝑖𝑗) is related to computing reconstruction of the data for 𝑒𝑖𝑗 connection.
Although CD1 method is not a perfect gradient computation method, but its results are acceptable. By repeating Gibbs sampling steps, CDk method is achieved. The k parameter is the number of repetitions of Gibbs sampling steps. This method has a higher performance and can compute gradient more exactly.
This method is great at learning features that are very at modelling/reconstructing data input data.
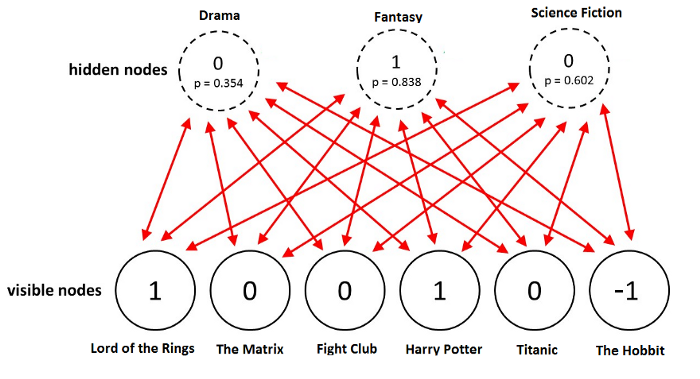
Let’s say you take a binary matrix that is an image of handwritten digit(i.e. number 6), turn it into a binary vector and feed it to trained RBM model, using its trained weights the model will be able to find low energy states compatible with that image and if you give it an image that is not of handwritten digit the model will not be able to find low energy states compatible with that image.
So what is this energy?
An energy function can be defined as a function that we want to minimize or maximize and it is a function of the variables of the system(model weights and bias).
We use energy functions as a unified framework for representing many machine learning algorithms(models).
Deep belief network
A Deep Belief Network(DBN) is a powerful generative model that use a deep architecture of multiple stacks of Restricted Boltzmann machines(RBM).
Each RBM model performs a non-linear transformation(much like a vanilla neural network works) on its input vectors and produces as outputs vectors that will serve as input for the next RBM model in the sequence.
This allows a lot flexibility to DBNs and makes them easier to expand.
Being a generative model allows DBNs to be used in either an unsupervised or a supervised setting. Meaning, DBNs have the ability to do feature learning/extraction and classification that are used in many applications, more on this in the applications section.
Precisely, in feature learning we do layer-by-layer pre-training in an unsupervised manner on the different RBMs that form a DBN and we use back-propagation technique(i.e. gradient descent) to do classification and other tasks by fine-tuning on a small labelled dataset.
Architecture & Fine-tuning
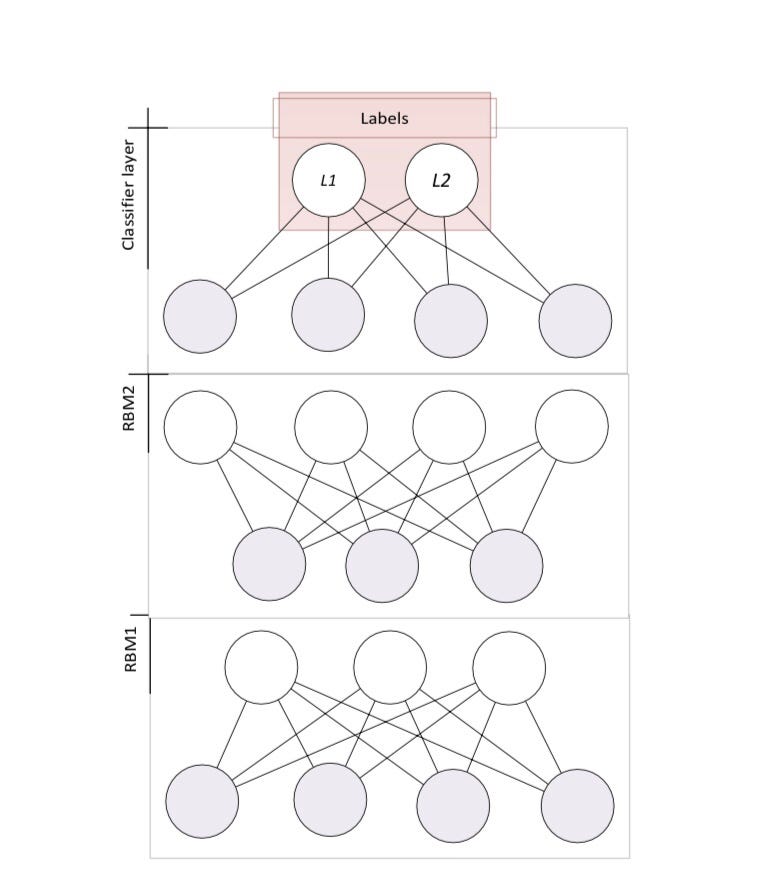
As we already know by now with most of Neural Networks whether CNNs, LSTM, Transformers and etc. Pre-training helps our network generalise better and we can slightly adjust this pre-trained weights to many downstream tasks(i.e. binary classification, multi-class classification and etc) with a small dataset.
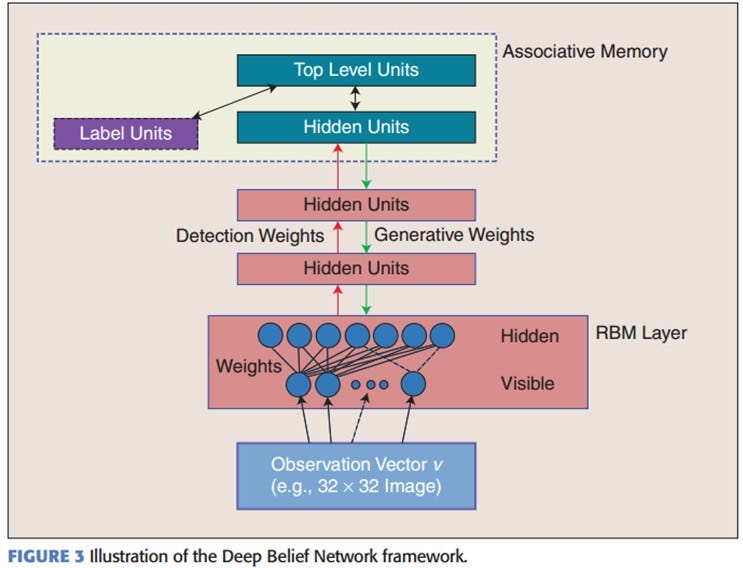
Applications
Here are some of the tasks that this family of networks can be used for:
- Image generation
- Image classification
- Video recognition
- Motion-capture
- And Natural Language Understand(i.e. speech processing), for detailed description, read check out the paper by the creator of DBNs himself Geoffrey Hinton
Deep Boltzmann Machine

After DBNs another moodel called Deep Boltzmann Machine (DBM) was created that trains better and achieves a lower loss, although it had some issues like being hard to generate sample from.
A DBM is a three-layer generative model. They are similar to a Deep Belief Network, but they while DBNs have bidirectional connections in the bottom layer on the other hand DBM has entirely undirected connections.
Now that we are equipped with the theory it is time to dive into the implementation details.
Code implementation
If you looking for a plug and play like implementation of DBN but also Ives lots of flexibility, checkout:
If you a looking for a DIY and step by step tutorial from scratch, checkout:
Conclusion
Deep belief Networks are family of deep architecture networks that uses stacks of Restricted Boltzmann Machines as building blocks. Furthermore, DBNs can be used in a both unsupervised setting for tasks such as image generation and in a supervised setting for tasks such as image classification, and it takes full advantage of great techniques such as unsupervised pre-training and fine tuning on a down stream task.
Acknowledgements
Special thanks to Ms. Esther M Dzitiro for suggesting the topic of this article.
References
Checkout for more detailed explanation: Lecture 12C : Restricted Boltzmann Machines
Lecture 12D : An example of Contrastive Divergence Learning
https://cedar.buffalo.edu/~srihari/CSE676/20.4-DeepBoltzmann.pdf
https://www.cs.toronto.edu/~hinton/absps/fastnc
http://www.robotics.stanford.edu/~ang/papers/icml09-ConvolutionalDeepBeliefNetworks
https://www.cs.toronto.edu/~hinton/absps/ruhijournal.pdf
https://astrostatistics.psu.edu/su14/lectures/CosPop14-2-2-BayesComp-2.pdf
A Tutorial on Energy-Based Learning
Loss Functions for Energy-Based Models With Applications to Object Recognition






{kind=link}