
Web Scraping a Wikipedia Table into a Dataframe
How do you convert a Wikipedia table into a Python Dataframe ?

“It is a capital mistake to theorize before one has data.” — Sherlock Holmes
Many of you Data Science enthusiast out there who are thinking of starting a new project, be it for enhancing your skills or a corporate level project need “data” to work with. Thanks to the internet, today we have hundreds of data sources available. One of the places where you can find data easily is the Wikipedia. Here is an example of a data source : https://en.wikipedia.org/wiki/List_of_cities_in_India_by_population
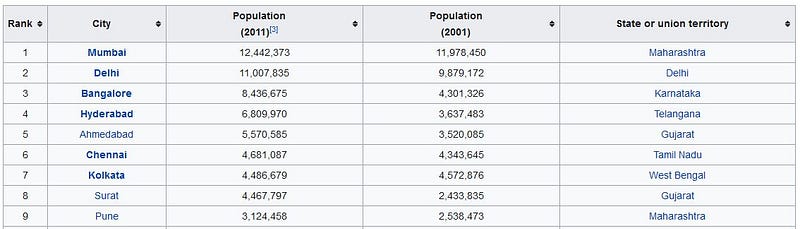
We have the data which we need to work with. Lets say I need the names of the Indian cities, their states and their population.Now there are many ways you can extract this data like copy and pasting the content on a new excel sheet or using the Wikipedia API. But what if i tell you that this table can directly be converted to a Python Dataframe so it becomes easier for further analysis and processing. Interesting, isn’t it?
The task of extracting data from websites is called Web Scraping.It is one of the most popular methods of collecting data from the internet along with APIs. Some websites do not provide APIs to collect their data so we use data scraping technique. Some of the best programming languages for scraping purpose are Node.js, C , C++, PHP and Python.
We use Python for this particular task. But why Python?
- It is the most popular language for web scraping.
- BeautifulSoup is among the widely used frameworks based on Python that makes scraping using this language such an easy route to take.
- These highly evolved web scraping libraries make Python the best language for web scraping.
You need to have some basic knowledge of HTML pages to understand web scraping. We also need some python libraries like BeautifulSoup, Requests and Pandas.
Following are the steps to scrape a Wikipedia table and convert it into a Python Dataframe.
- Install BeautifulSoup : pip install beautifulsoup4 (Go to the terminal and use this pip command to install it)
- Import required libraries : Requests, Pandas, BeautifulSoup.
Requests is a Python module that you can use to send all kinds of HTTP requests. It is an easy-to-use library with a lot of features ranging from passing parameters in URLs to sending custom headers and SSL Verification.
Pandas is a data analysis tool for the python programming language. We use Pandas Dataframe is a 2-dimensional labeled data structure with columns of potentially different types. You can think of it like a spreadsheet or SQL table, or a dict of Series objects. It is generally the most commonly used pandas object.
import pandas as pd # library for data analysis
import requests # library to handle requests
from bs4 import BeautifulSoup # library to parse HTML documents3. Request for the HTML response using the URL : We send a GET request to the Wikipedia URL whose table needs to be scraped and store the HTML response in a variable. It is not legal to scrape any website, so we check the status code. 200 shows that you can go ahead and download it.
# get the response in the form of html
wikiurl="https://en.wikipedia.org/wiki/List_of_cities_in_India_by_population"
table_class="wikitable sortable jquery-tablesorter"
response=requests.get(wikiurl)
print(response.status_code)4. Inspect page : In order to scrape the data from the website, we place our cursor on the data ,right click and Inspect. This gives us the HTML content through which we can find the tags inside which our data is stored. It is obvious that a table is stored inside the tag in HTML.
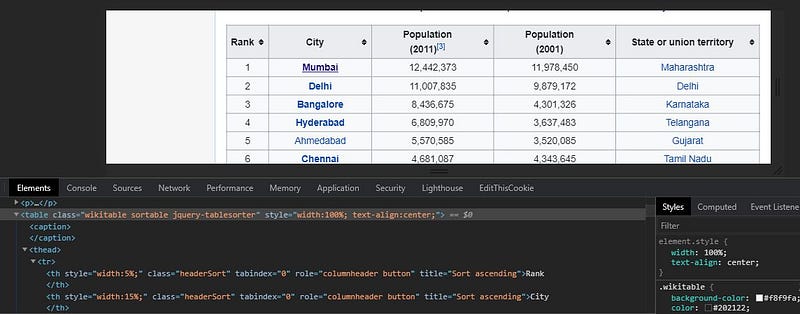
5. Parse data from the HTML : Next we create a BeautifulSoup object and using the find() method extract the relevant information,which in our case is the tag. There can be many tables in a single Wikipedia page, so to specify the table we also pass the “class” or the “id” attribute of the
# parse data from the html into a beautifulsoup object
soup = BeautifulSoup(response.text, 'html.parser')
indiatable=soup.find('table',{'class':"wikitable"})Output :

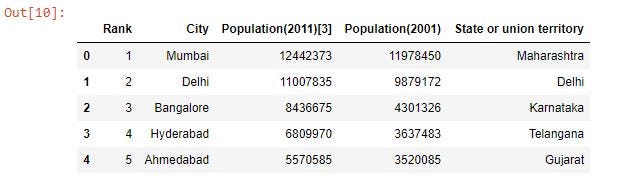
6. Convert Wikipedia Table into a Python Dataframe : We read the HTML table into a list of dataframe object using read_html(). This returns a list. Next we convert the list into a DataFrame.
df=pd.read_html(str(indiatable))
# convert list to dataframe
df=pd.DataFrame(df[0])
print(df.head())Output:
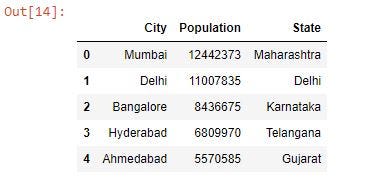
7. Clean the Data : We only need the city name,state and population(2011) from this dataframe. So we drop the other columns from the dataframe and rename the columns for a better understanding.
# drop the unwanted columns
data = df.drop(["Rank", "Population(2001)"], axis=1)
# rename columns for ease
data = data.rename(columns={"State or union territory": "State","Population(2011)[3]": "Population"})
print(data.head())Output :
And that’s it!!
You have your Wikipedia table converted into a dataframe which can now be used for further data analysis and machine learning tasks.That’s the beauty of using Python for web scraping. You can have your data in no time using just a few lines of code.

Refer to my GitHub Code
Note : All the resources that you will require to get started have been mentioned and their links provided in this article as well. I hope you make good use of it :)
I hope this article will get you interested in trying out new things like web scraping and help you add to your knowledge. Don’t forget to click on the “clap” icon below if you have enjoyed reading this article. Thank you for your time.




