
Visual chatGPT — Send, Receive, and Edit Images
Recently, the creation of large language models (LLMs), such as T5, BLOOM, and GPT-3, has advanced significantly. Because ChatGPT is trained to hold on to conversational context, reply appropriately to follow-up questions, and provide accurate responses, it represents a significant advancement. Even though ChatGPT is amazing, it can only process visual data because it was only trained using one linguistic modality.
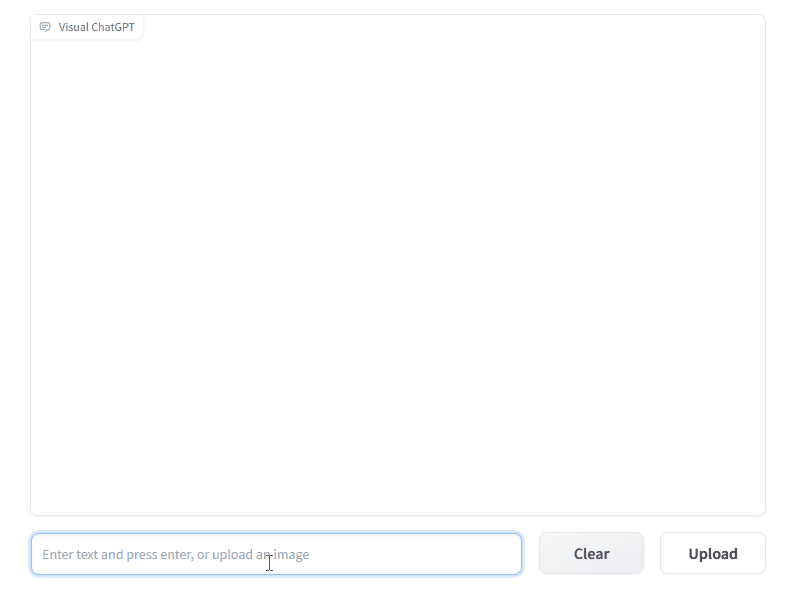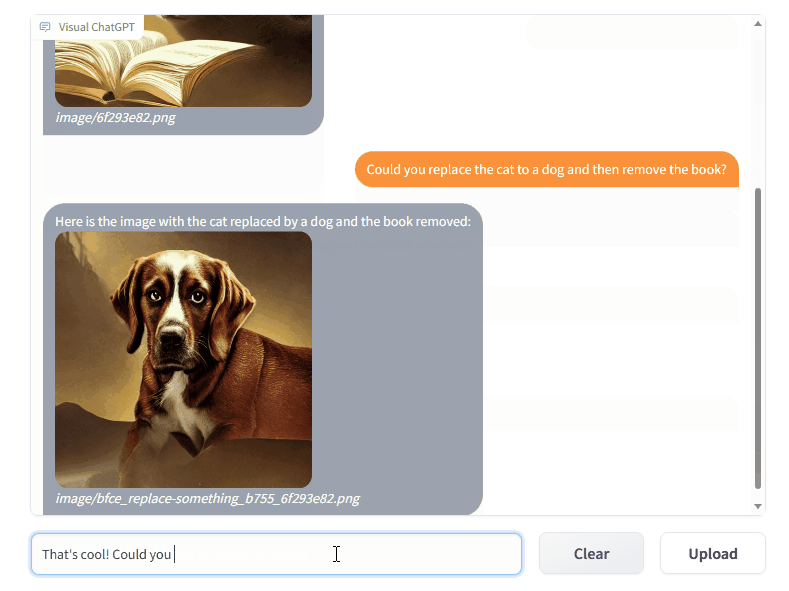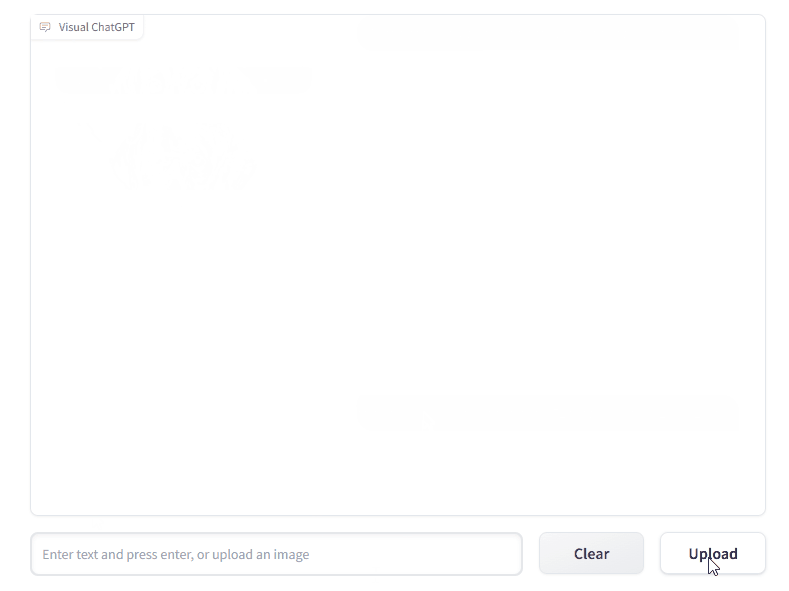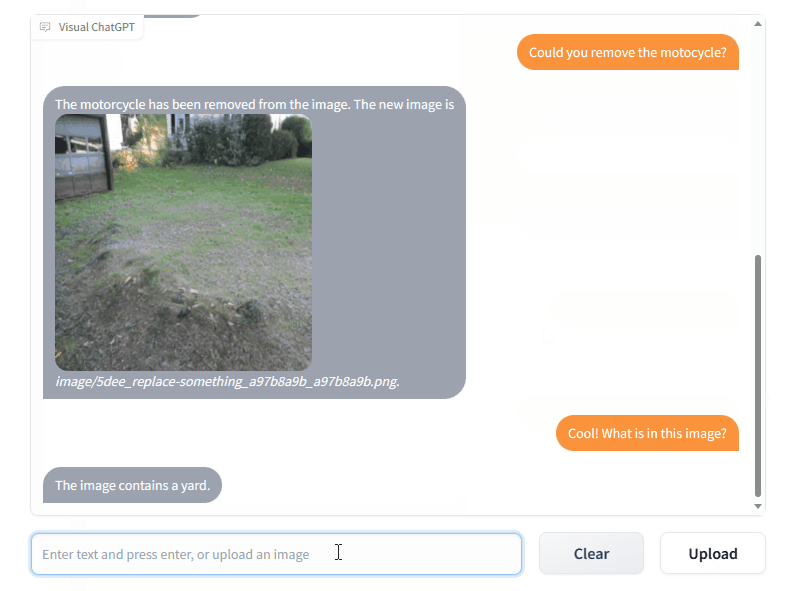
The ability of Visual Foundation Models (VFMs) to interpret and create complex pictures has demonstrated tremendous potential for computer vision. Due to the limitations imposed by the nature of task specification and the predetermined input-output formats, VFMs are less adaptive than conversational language models in human-machine interaction.
Join the Medium Membership Program for only 5$ to continue learning without limits. I’ll receive a small portion of your membership fee if you use the following link, at no extra cost to you.
A natural solution to developing a ChatGPT-like system that can understand and produce visual content is to train a multimodal conversational model. Nevertheless, building such a system would require a large amount of data and computing power.
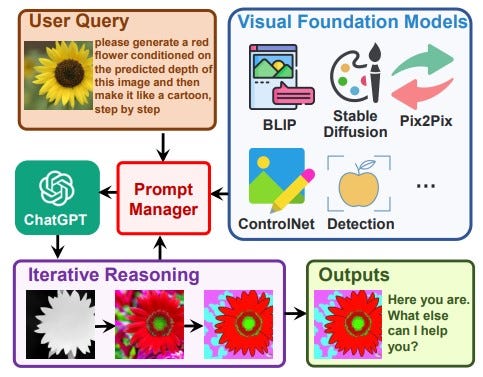
A recent Microsoft study suggests a solution for this problem in the form of Visible ChatGPT, which communicates with vision models using text and prompt chaining. Instead of building a brand-new multimodal ChatGPT from scratch, the researchers built Visual ChatGPT on top of ChatGPT and included various VFMs. To fill the gap between ChatGPT and these VFMs, they introduce a Prompt Manager with the following features —
- Specifies the input and output formats and informs ChatGPT on the capabilities of each VFM
- Handles the histories, priorities, and conflicts of various Visual Foundation Models
- Turns various visual information, such as png images, depth images, and mask matrix, into language format to aid ChatGPT in understanding.
ChatGPT may use these VFMs iteratively and learn from their replies by integrating the Prompt Manager, which allows it to do so until it either fully meets the needs of the users or reaches the end state.
Consider this scenario: A user uploads a picture of a yellow flower along with a complex language request, such as “please build a red flower conditioned on the predicted depth of this image and then construct it like a cartoon, step by step.” With the Prompt Manager, Visual ChatGPT starts the execution of connected Visual Foundation Models. To be more specific, it uses a depth estimation model first to identify the depth information, a depth-to-image model next to create a figure of a red flower using the depth information, and finally a style transfer VFM based on a Stable Diffusion model to turn the appearance of this image into a cartoon.
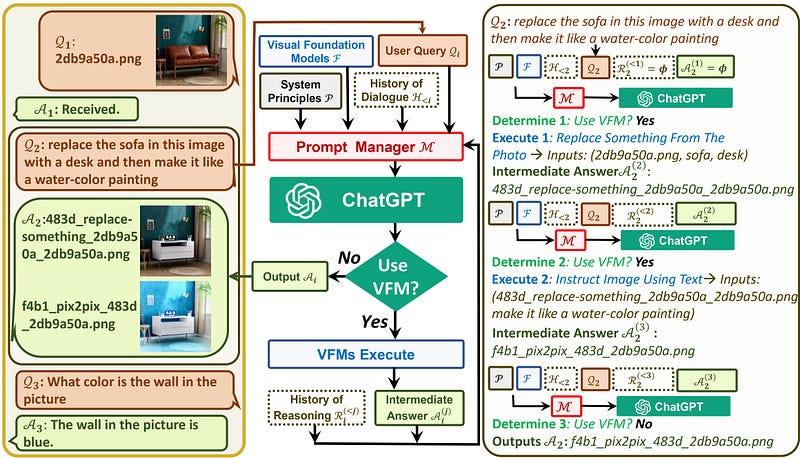
The Prompt Manager serves as a dispatcher for ChatGPT in the processing chain described above by providing the visual representations and monitoring the information transformation. Visual ChatGPT will suspend the pipeline’s execution after gathering “cartoon” hints from Prompt Manager and displaying the results. By choosing “god model” from a number of different small models, with text serving as the universal interface, it would be able to implement multimodality while running the source using Pyreverse.
Some highlights that stood out to me are —
- Provide responses that are coherent and relevant to the topic at hand.
- When talking about images, Visual ChatGPT is very strict to the file name and will never fabricate nonexistent files.
- Visual ChatGPT is able to use tools in a sequence, and is loyal to the tool observation outputs rather than faking the image content and image file name.
- Visual ChatGPT should use tools to finish following tasks, rather than directly imagine from the description.
- Very strict to the filename correctness and will never fake a file name if it does not exist. You will remember to provide the image file name loyally if it’s provided in the last tool observation.
So, what do you think about Visual chatGPT? Let’s discuss in the comments section :)

Paper — Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
GitHub — Visual ChatGPT
My other writings —
https://medium.com/@smraiyyan/list/awesome-chatgpt-prompts-6b5f19244ab3
More content at PlainEnglish.io. Sign up for our free weekly newsletter. Join our Discord community and follow us on Twitter, LinkedIn and YouTube.
Learn how to build awareness and adoption for your startup with Circuit.