
Computer Vision, Deep Learning, Natural Language Processing
Video to Text Description Using Deep Learning and Transformers | COOT
This new model published in the NeurIPS2020 conference uses transformers to generate accurate text descriptions for each sequence of a video, using both the video and a general description of it as inputs.

It understands what’s happening in the video at each clip, just like a human would do. Let’s see how they’ve achieved that.
As many of you guys may already know, we are approaching the date of the Neural Information Processing Systems conference, also referred to as the NeurIPS conference. Where many awesome papers will become publicly available and shared with a wider audience. I will certainly be covering the most interesting ones, just like the one in this video.

Which is called COOT: Cooperative Hierarchical Transformer for Video-Text Representation Learning. As the name states, it uses transformers to generate accurate text descriptions for each sequence of a video, using both the video and a general description of it as inputs.
Before continuing, if you are not familiar with the transformer’s architecture, I invite you to watch the video I made explaining it. It will help you understand the rest of the video where I won’t get into the details of this architecture.
Before diving into this network, we also need to review an important concept. Granularity.
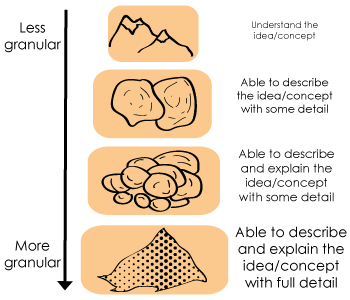
It’s extremely important to understand granularity and how it applies to our work. Especially when it comes to generating a text description from a video. Granularity refers to the size of a specific entity. In our case, it refers to both the videos and the text where there are many levels of granularity. The video can be referred to either as frames, clips, or directly the full video. Where words can also be seen as sentences, paragraphs, and even letters. They each have different semantics and meanings. For example, generate a general description of a video is a much simpler task than generating multiple, more in-depth, descriptions throughout the whole video as they achieved in this paper.
They’ve achieved that by modeling the interactions between these different levels of granularity to better understand the context of the video frames and clips together. Their method basically consists of three major components. The first part of this architecture works within a clip. It leverages the local temporal context, being the information inside each clip relevant to understand the context, by using an attention-aware feature aggregation layer.
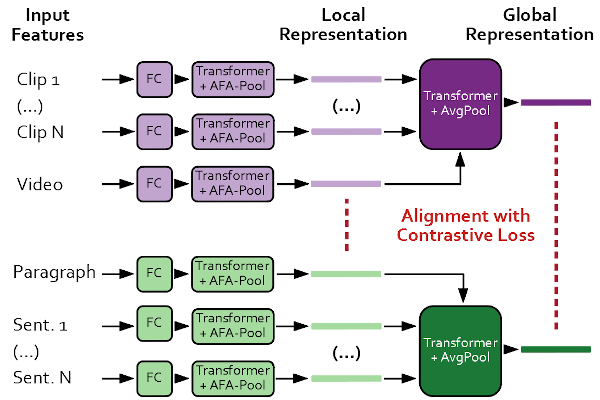
Then, there’s a contextual transformer that learns how each clip, sentence, paragraphs interact together to produce the final video/paragraphs using this temporal transformer as a basis.
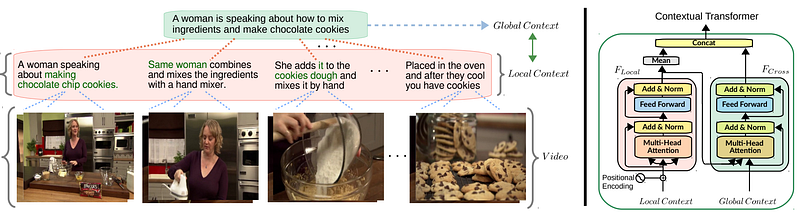
In short, this contextual transformer encourages the model to optimize the representations with respect to interactions between both local and global contexts. It is important to use both the global and local context together to understand what’s happening throughout the whole video, just like humans do. This way, the model knows that each clip is connected together and the next clip is a continuation of the current clip. In this example, the model understands that it’s still the same person in the whole video doing the same thing with multiple steps, which is a chocolate cookie recipe.
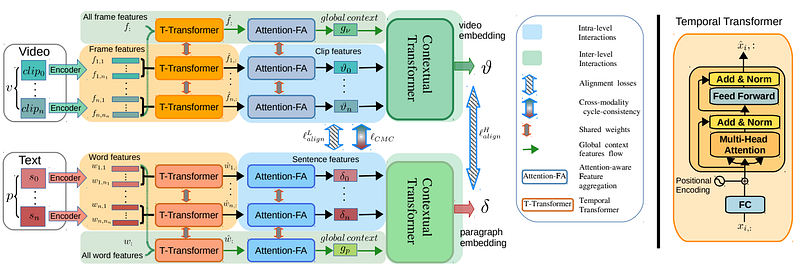
This section consists of two branches, one for the video input, and one for the text input. Given a specific video and a general text description of it, they encode them to the smallest granularity possible, which is the frame and word levels. Then these encoded inputs are sent to these temporal transformers and attention feature aggregation modules to obtain the clip-level and sentence-level features from the frames and words information. Using attention that focuses on interactions between these low-level entities, which I repeat, are the words of the general description and frames of the video in our case.
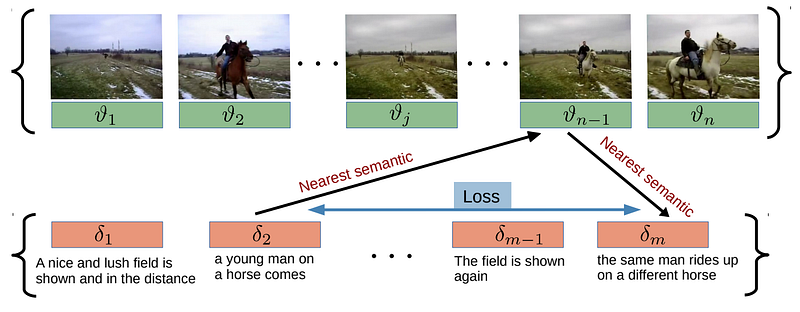
Finally, just like in every deep learning model, there’s a loss function. In this case, it is a cross-modal cycle-consistency loss to connect the video to the text and improve the results. Using a joint embedding space, they find the nearest neighbor in the clip sequence for each sentence and do the same thing the other way around.
Here’s what their model outputs when trying to randomly caption the clips of a video and put it together. Watch this video for a better explanation and more examples:
Of course, this was just a simple overview of this new paper, I strongly invite you to read the paper linked below in my references. You can find their code publicly available on GitHub linked below as well!
If you like my work and want to support me, I’d greatly appreciate it if you follow me on my social media channels:
- The best way to support me is by following me on Medium.
- Subscribe to my YouTube channel.
- Follow my projects on LinkedIn
- Learn AI together, join our Discord community, share your projects, papers, best courses, find Kaggle teammates, and much more!
References:





