
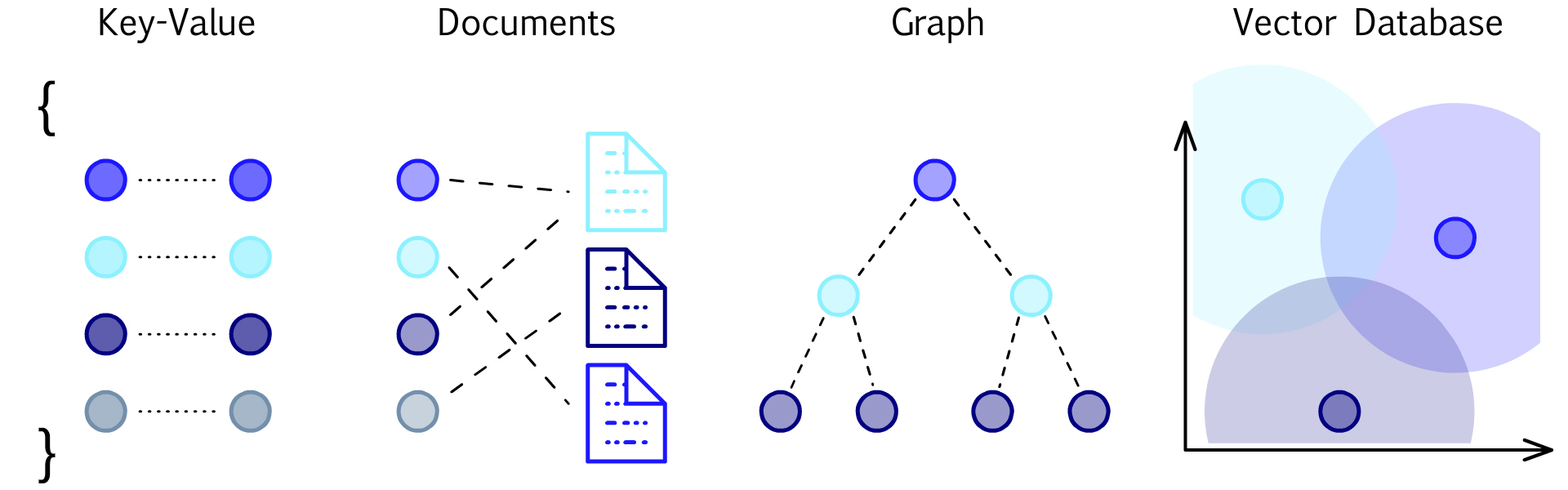
Vector Database — Introduction

First of all, before we start exploring vector databases, it’s important to understand what vectors are in the context of programming and machine learning.
In the context of programming and machine learning, a vector is a one-dimensional array of elements. These elements can be of any type such as integers, floats, strings, and more. Vectors are a fundamental part of many programming languages, including Python, C++, Java, and more. They are used to store data that can be processed in a sequential manner.
For example, to define a vector in Python:
# Define a vector using a Python list
vector = [1, 2, 3, 4, 5]
print(f"Vector: {vector}")Beyond mere numerical arrays, vectors serve a pivotal role within the realm of machine learning. They provide a means to represent and manipulate data within high-dimensional spaces. This capacity allows for the execution of intricate operations and computations that power AI models. Therefore, vectors are more than simple numerical sequences; they are integral components in the functioning and performance of machine learning systems.
What is Vector Database

A vector database is a specialized database that organizes data as high-dimensional vectors, it is optimized for storing and performing operations on large amounts of vector data (Vector database often processing hundreds of millions of vectors per query).
These vectors symbolize the features or attributes of the data and can extend from a few tens to thousands of dimensions, contingent upon the intricacy and detail of the data.
Transformations or embedding functions are typically applied to raw data — which could include text, images, audio, video, among others — to generate these vectors. The process of embedding could leverage a multitude of techniques like machine learning models, word embeddings, or feature extraction algorithms.
In AI applications, vector databases are particularly valuable for their ability to handle similarity search effectively. Given a vector, the database can retrieve the most similar vectors stored in the database efficiently. This feature is essential in many AI-related tasks such as recommendation systems, image or voice recognition, natural language processing, and more.
For example, vector distance:

In a recommendation system, the behavior of a user can be represented as a vector. When this user needs recommendations, the system will find the most similar vectors (representing other users) in the database and suggest items that these similar users have interacted with or liked.
The primary benefit of a vector database lies in its capacity for rapid and precise similarity search, enabling data retrieval based on vector distance or likeness. This deviates from conventional database querying methods that rely on exact matches or preset criteria. Instead, a vector database facilitates the identification of data that is semantically or contextually most similar or relevant, thereby optimizing the search process.
How are vector databases used?
Vector databases are generally employed to facilitate vector search scenarios, such as visual, semantic, and multimodal searches. Increasingly, they are being integrated with generative AI text models to develop intelligent agents capable of facilitating conversational search experiences.
The creation process begins by establishing an embedding model, which is programmed to convert a corpus — such as product images — into vectors. This data import operation is also referred to as data hydration. Once the data is in place, application developers can leverage the database to search for similar products. They achieve this by transforming a product image into a vector and using this vector as a search query for similar images.
Within the model, k-nearest neighbor (k-NN) indexes ensure efficient vector retrieval and utilize a distance function, such as cosine, to rank the results based on their similarity.
Types of Vector Database
Several types of vector databases or software libraries exist that can efficiently handle high-dimensional vectors typical of machine learning and AI tasks. Here are a few examples:
FAISS (Facebook AI Similarity Search)
Created by Facebook’s AI research team, this library is designed for efficient similarity search and clustering of high-dimensional vectors. It contains algorithms that allow quick search over large vector sets and for compressed representation of high-dimensional vectors.
Annoy (Approximate Nearest Neighbors Oh Yeah)
Developed by Spotify, Annoy is a C++ library with Python bindings to search for points in space that are close to a given query point. It also creates large read-only file-based data structures that are mmapped into memory, allowing many processes to share the data.
ElasticSearch
While more known for its full-text search capabilities, Elasticsearch can also handle vector data thanks to its dense_vector data type. It can be used for storing and processing high-dimensional vectors from image, text, or numerical data.
SPTAG (Space Partition Tree And Graph)
Developed by Microsoft, SPTAG is an approximate nearest neighbor search library for both vectors and hybrid-vectors. It supports multi-threaded index building, as well as distributed search.
Milvus
An open-source vector database powered by Faiss, NMSLIB and Annoy, designed for AI and analytics, that supports processing, similarity search, and persistence of vector data.
Vector Database Use Cases
Vector databases play a crucial role in many real-world applications, particularly in fields where handling high-dimensional data and performing fast searches is necessary. Here are some use cases:
- Image Recognition: Given an image, a vector database can be used to find similar images based on the image embeddings. This is useful for applications such as reverse image search, similar product recommendation, or facial recognition.
- Natural Language Processing (NLP): Vector databases can store embeddings of words, sentences, or documents. This is useful in many applications such as information retrieval, document clustering, and text classification.
- Recommendation Systems: Vector databases can store embeddings of user behavior or item features. Given a user or item, the system can quickly find similar users or items to make recommendations. For example, movie recommendations based on user viewing patterns or product recommendations based on browsing history.
- Anomaly Detection: By representing normal behavior as a set of vectors in a vector database, we can identify anomalies by looking for data points that have high distances from the nearest vectors in the database.
- Bioinformatics: In genetics and drug discovery, high-dimensional vectors are used to represent complex bioinformatics data. Vector databases can help in discovering patterns, similarities, or anomalies in these datasets.
- Voice Recognition: Voice samples can be transformed into high-dimensional vectors. A voice recognition system can use a vector database to match an input voice sample with stored voice profiles.
Vector Database Demo in ElasticSearch
Elasticsearch has a dense_vector data type that allows you to store arrays of float values which can be used to represent dense vectors of floats. This can be particularly useful for machine learning use cases where you want to search for similar vectors, calculate the distance between them, or aggregate them.
Let’s consider a use case where you want to find similar products based on their descriptions. You will first convert product descriptions into vector representations using a method like Word2Vec, and then use Elasticsearch to store these vectors and search for similar ones.
Step 1: Create ElasticSearch Index
First, you create an index with the dense_vector field for storing vectors:
PUT my_dense_vector_index
{
"mappings": {
"properties": {
"description_vector": {
"type": "dense_vector",
"dims": 50
},
"description": {
"type": "text"
}
}
}
}Here, dims is the number of dimensions in the vector, which is 50 in this case as assumed by Word2Vec embeddings
Step 2: Indexing Document
Let’s assume you have a product with a description and you’ve converted this description into a dense vector using Word2Vec. You index this product as follows:
PUT my_dense_vector_index/_doc/1
{
"description": "Blue button-down shirt for casual and formal wear",
"description_vector": [...] // 50-dimensional vector
}In the description_vector field, instead of …, you’ll provide the 50-dimensional vector representing the description.
Step 3: Finding Similar Products
Now, suppose you have another product description and you want to find products with similar descriptions. You convert this new description into a vector using the same Word2Vec model and then use the script_score function to calculate the cosine similarity between this new vector and the vectors already in the index:
GET my_dense_vector_index/_search
{
"query": {
"script_score": {
"query": {
"match_all": {}
},
"script": {
"source": "cosineSimilarity(params.query_vector, 'description_vector') + 1.0",
"params": {
"query_vector": [...] // Vector for the new description
}
}
}
}
}Similar to the indexing part, replace … in query_vector with the actual vector values. This will return the products in the index ordered by their similarity to the new product.






{kind=link}
{kind=link}