
Neural Networks
VAE: Variational Autoencoders — How to Employ Neural Networks to Generate New Images
An overview of VAEs with a complete Python example that teaches you how to build one yourself

Intro
This article will take you through Variational Autoencoders (VAE), which fall into a broader group of Deep Generative Models alongside the famous GANs (Generative Adversarial Networks).
Unlike GAN, VAE uses an Autoencoder architecture instead of a pair of Generator-Discriminator networks. So, the ideas used in VAEs should be relatively straightforward to understand, especially if you have used Autoencoders in the past.
Feel free to subscribe to email notifications if you would like to be informed about my future articles on Neural Networks such as GANs.
Contents
- VAE’s place in the universe of Machine Learning algorithms
- The structure of VAEs and an explanation of how they work
- A complete Python example showing you how to build a VAE with Keras/Tensorflow
VAE’s place in the universe of Machine Learning algorithms
The below chart is my attempt to organise the most common Machine Learning algorithms. Although, it is not an easy task since we can categorise them across multiple dimensions based on the algorithm's underlying structure, or the problems they are designed to solve.
I have tried to take both dimensions into account, which led me to placing Neural Networks into their own category. While we typically use Neural Networks in a Supervised manner, it is essential to acknowledge that some examples, such as Autoencoders, are more like Unsupervised/Self-Supervised algorithms.
Despite Variational Autoencoders (VAE) having similar objectives as GANs, their architecture is closer to other types of Autoencoders such as Undercomplete Autoencoders. Hence, you will find VAEs by clicking on the Autoencoders group in the interactive chart below👇.
If you enjoy Data Science and Machine Learning, please subscribe to get an email with my new articles. If you are not a Medium member, you can join here.
The structure of VAEs and an explanation of how they work
Let’s start by analysing the architecture of a standard Undercomplete Autoencoder (AE) before diving into the elements than make VAEs different.
Undercomplete AE
Below is an illustration of a typical AE.
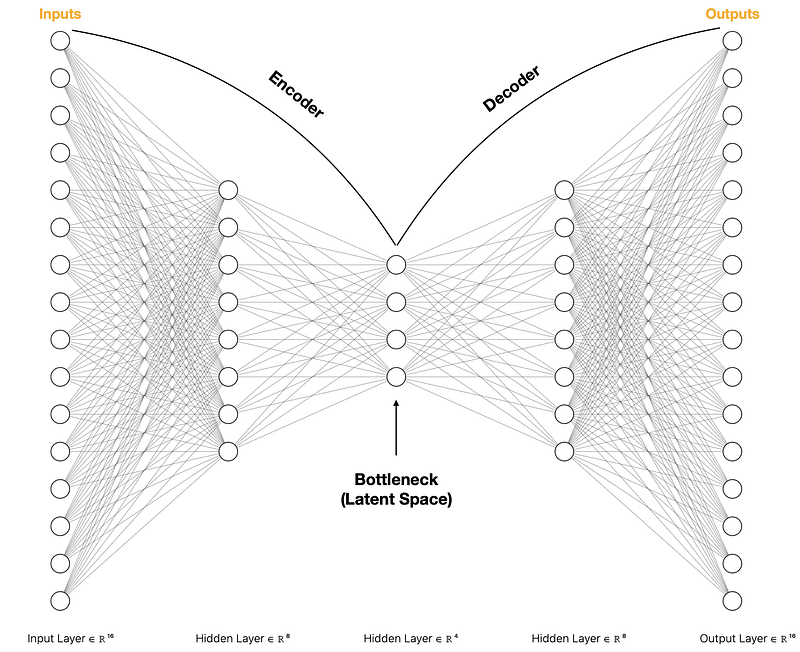
The goal of an Undercomplete AE is to efficiently encode information from input data into a lower-dimensional latent space (bottleneck). We achieve this objective by ensuring that the inputs can be recreated with minimal loss using a decoder.
Note that during training, we pass the same set of data into input and output layers as we attempt to discover the parameter values for an “optimal” latent space.
Variational AE
Now let’s look at how VAE differs from an Undercomplete AE by analysing its architecture:
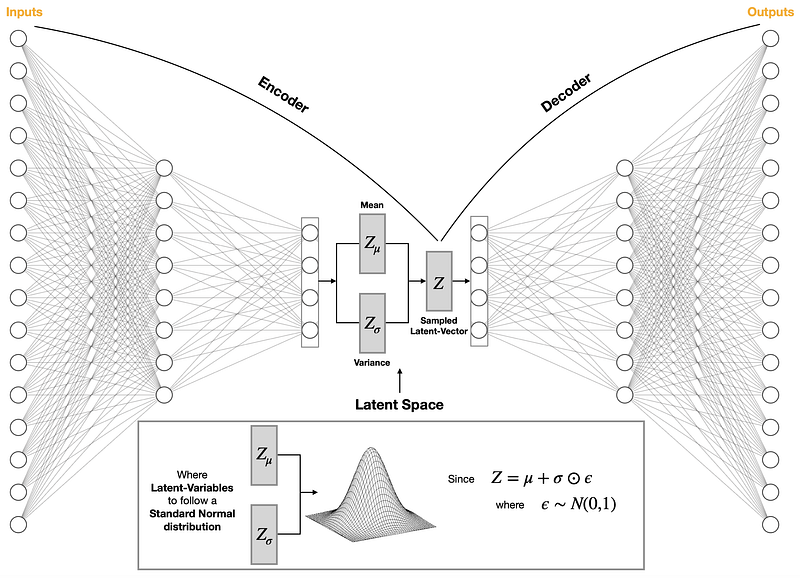
We notice that VAE’s latent space is not made up of point vectors (individual nodes). Instead, the inputs are mapped onto a Normal distribution, where Zμ and Zσ are the mean and variance, the parameters learned during model training.
Meanwhile, the latent vector Z is sampled from a distribution with mean Zμ and variance Zσ and passed to the decoder to obtain the predicted outputs.
It is crucial to understand that by design, the latent space of a VAE is continuous, which enables us to sample from any part of it to generate new outputs (e.g. new images), making VAE a generative model.
The need for regularisation
Encoding inputs into a distribution takes us only halfway to creating a latent space that is suitable for generating “meaningful” outputs.
However, we can achieve the desired regularity by adding a regularisation term expressed as the Kulback-Leibler divergence (KL divergence). We will talk more about it in the Python section later on.
Intuition about the latent space
We can use the following illustration to visualise how the information is spread within the latent space.
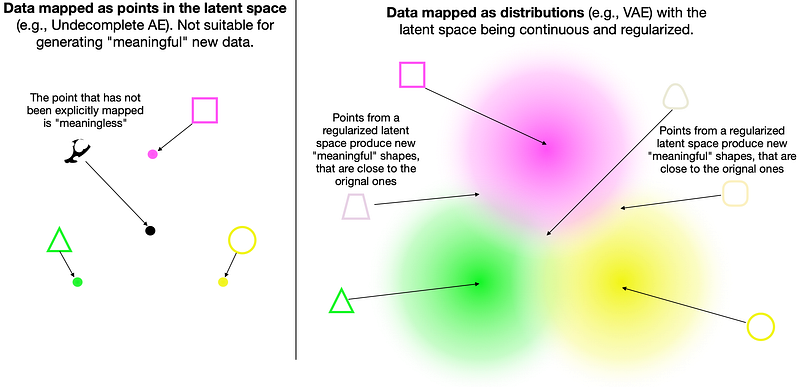
As you can see, mapping data as individual points do not train the model to understand the similarities/differences between those points. Hence, we cannot use such space to generate new “meaningful” data.
In the case of Variational Autoencoders, we have mapped data as distributions and regularised the latent space, which gives us the “gradient” or “smooth transition” between distributions. Hence, when we sample a point from such latent space, we generate new data closely resembling the training data.


A complete Python example showing you how to build a VAE with Keras/Tensorflow
Finally, it’s time to build our own VAE!
Setup
We’ll need the following data and libraries:
- MNIST handwritten digit data (copyright held by Yann LeCun and Corinna Cortes under the Creative Commons Attribution-Share Alike 3.0 license; the source of the data: The MNIST Database)
- Numpy for data manipulation
- Matplotlib, Graphviz and Plotly for visualisations
- Tensorflow/Keras for Neural Networks
Let’s import all the libraries:
The above code prints package versions used in this example:
Tensorflow/Keras: 2.7.0
numpy: 1.21.4
matplotlib: 3.5.1
graphviz: 0.19.1
plotly: 5.4.0Next, we load MNIST handwritten digit data and display the first ten digits. Note that we will only use digit labels (y_train, y_test) in visualisations and not for model training.
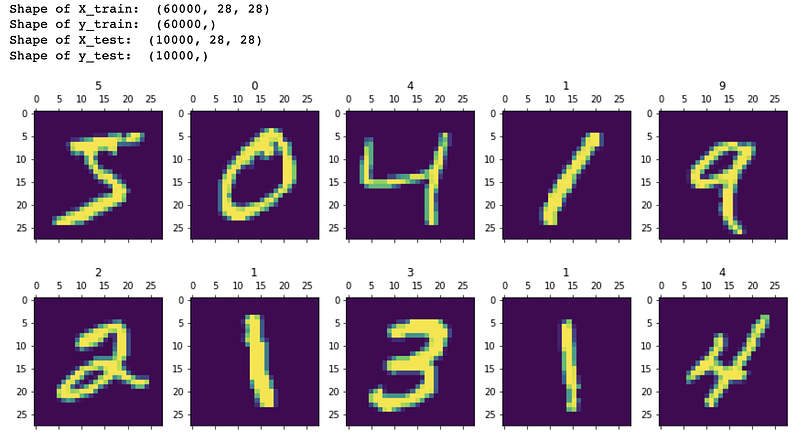
As you can see, we have 60,000 images in the training set and 10,000 in the test set. Note that their dimensions are 28 x 28 pixels.
The final step in the setup is to flatten the images by reshaping them from 28x28 to 784.
Typically, we would use Convolutional layers instead of flattening images, especially when working with larger pictures. However, I wanted to keep this example simple, hence using Dense layers with flat data instead of Convolutional ones.
New shape of X_train: (60000, 784)
New shape of X_test: (10000, 784)Building a Variational Autoencoder model
We will start by defining a function that will help us to sample from a latent space distribution Z.
Here we employ a reparameterisation trick that allows the loss to backpropagate through the mean (z-mean) and variance (z-log-sigma) nodes since they are deterministic.
At the same time, we separate the sampling node by adding a non-deterministic parameter, epsilon, which is sampled from a standard Normal distribution.
Now, we can define the structure of the Encoder model.
The above code creates an encoder model and prints its structural diagram.
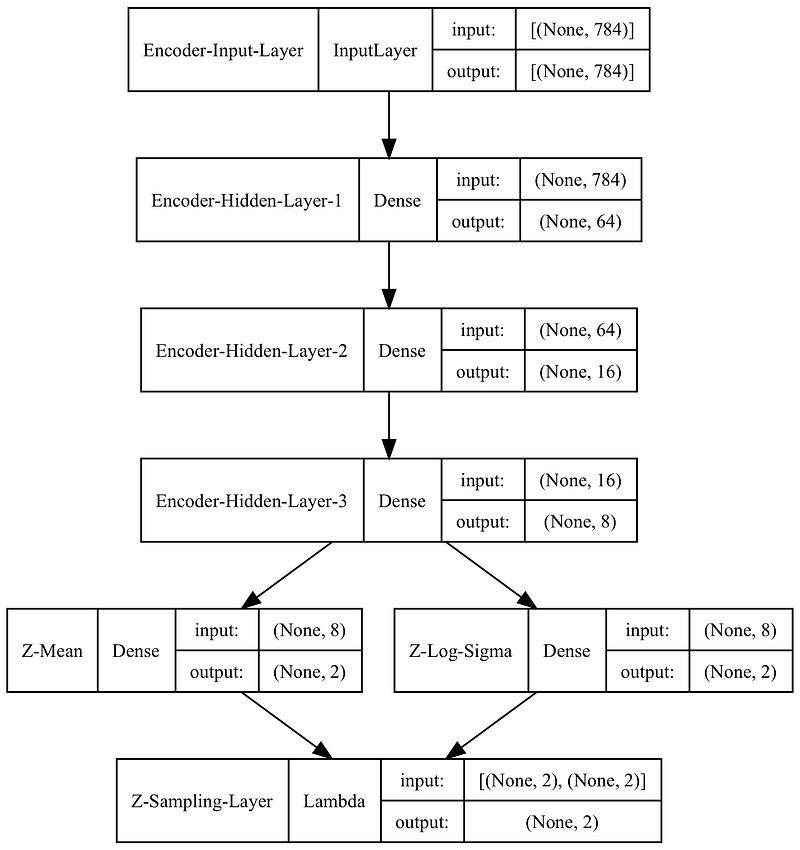
Note how we send the same outputs from the Encoder-Hidden-Layer-3 into Z-Mean and Z-Log-Sigma before recombining them inside a custom Lambda layer (Z-Sampling-Layer), which is used for sampling from the latent space.
Next, we create the Decoder model:
The above code creates a decoder model and prints its structural diagram.
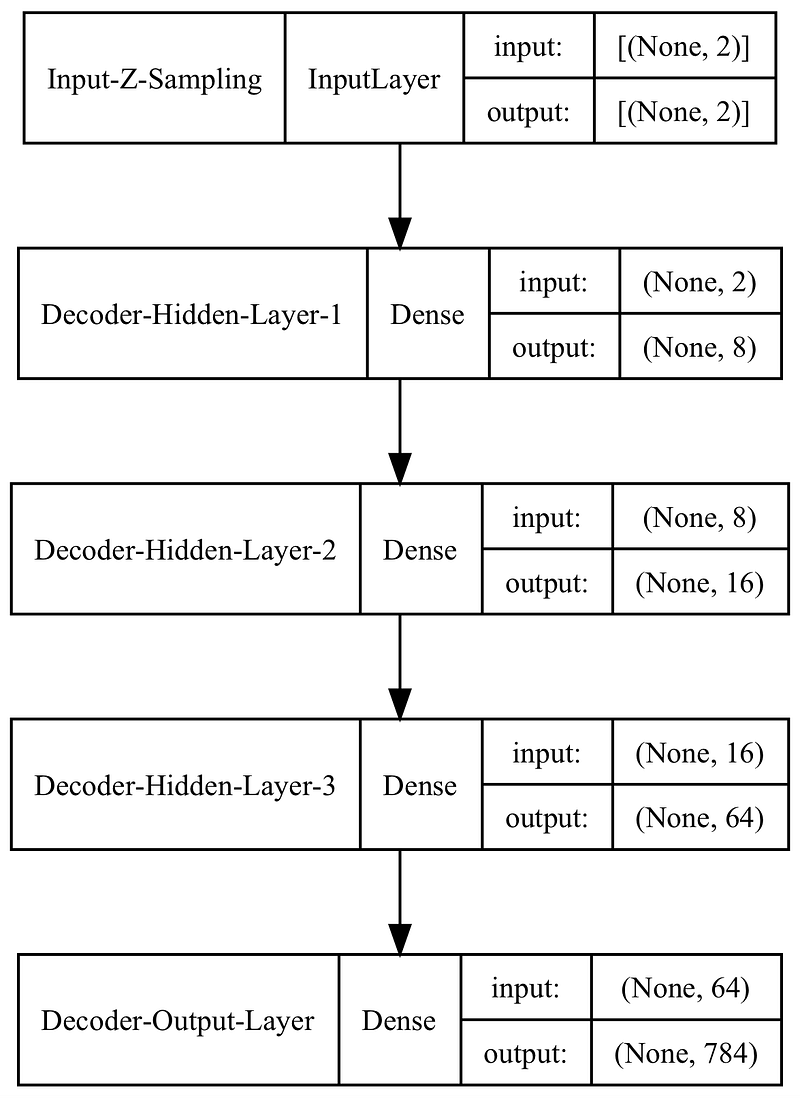
As you can see, the decoder is a pretty straightforward model that takes inputs from the latest space and passes them through a few hidden layers before generating values for the 784 output nodes.
Next, we combine the Encoder and Decoder models to form a Variational Autoencoder model (VAE).
If you paid close attention to the latent space layers in the Encoder model, you would have noticed that the encoder generates three sets of outputs: Z-mean [0], Z-log-sigma [1] and Z [2].
The above code links the models by specifying that the Encoder takes original inputs named “visible”. Then out of the three outputs generated by the Encoder [0], [1], [2], we take the third one (Z [2]) and pass it into a Decoder, which generates the outputs that we named “outpt”.
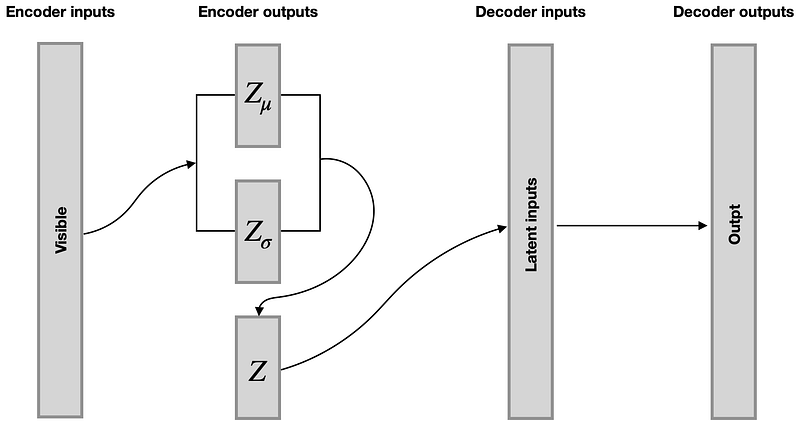
Custom Loss function
Before training the VAE model, the final step is to create a custom loss function and compile the model.
As mentioned earlier in the article, we will use KL divergence to measure the loss between the latent space distribution and a reference standard Normal distribution. The “KL loss” is in addition to the standard reconstruction loss (in this case, MSE) used to ensure that input and output images remain close.
VAE model training
With the Variational Autoencoder model assembled, let’s train it over 25 epochs and plot the loss chart.
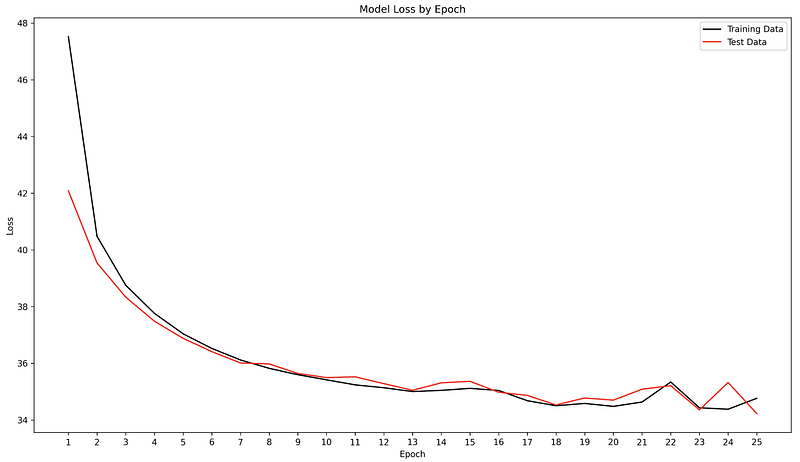
Visualising latent space and generating new digits
Since our latent space is two-dimensional, we can visualise the neighbourhoods of different digits on the latent 2D plane:
Plotting the digit distribution in the latent space gives us the benefit of visually associating different regions with different digits.
Say we want to generate a new image of a digit 3. We know that 3’s are located in the top middle of the latent space. So let’s pick the coordinates of [0, 2.5] and generate an image associated with those inputs.
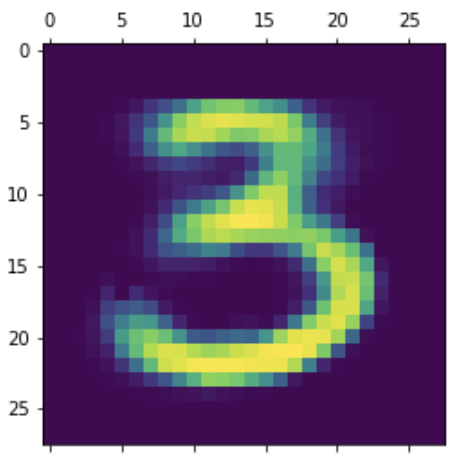
As expected, we got an image of a shape closely resembling a digit 3 because we sampled a vector from a region in the latent space occupied by 3's.
Let’s now generate 900 new digits from across the whole latent space.

The cool thing about generating many images from the entire latent space is that it lets us see the gradual transition between different shapes. This confirms that we were able to regularise our latent space successfully.
Final remarks
It is important to note that we can use Variational Autoencoders to encode and generate much more complex data than MNIST digits.
Hence, I would like to encourage you to take my simple tutorial to the next level by applying it to real-world data relevant to your area.
For your convenience, I have saved a Jupyter Notebook in my GitHub repository containing all of the above code.
If you would like to be informed the moment I publish a new article on Machine Learning / Neural Networks (e.g., Generative Adversarial Networks (GAN)), please subscribe to receive an email.
If you are not a Medium member and would like to continue reading articles from thousands of great writers, you can join using my personalised link below:
Please do not hesitate to get in touch if you have any questions or suggestions!
Cheers! 🤓 Saul Dobilas





