
Utilizing ChatGPT for Enhanced Classification Tasks: An Innovative Algorithmic Approach
I have summarized the results of our experiments and proposed an algorithm for utilizing ChatGPT for classification problems.
Main problems in text classification using GPT
Here’s a brief overview:
1. A significant portion of the tasks in our work that are currently not automated are “classification tasks.”
2. Traditional machine learning models do not provide a sufficient level of efficiency for these tasks.
3. Using ChatGPT in a conventional manner also fails to solve these problems. For instance, ChatGPT provides entirely different classification groups in response to the same prompt in two separate queries.
For example: one prompt — two different results.
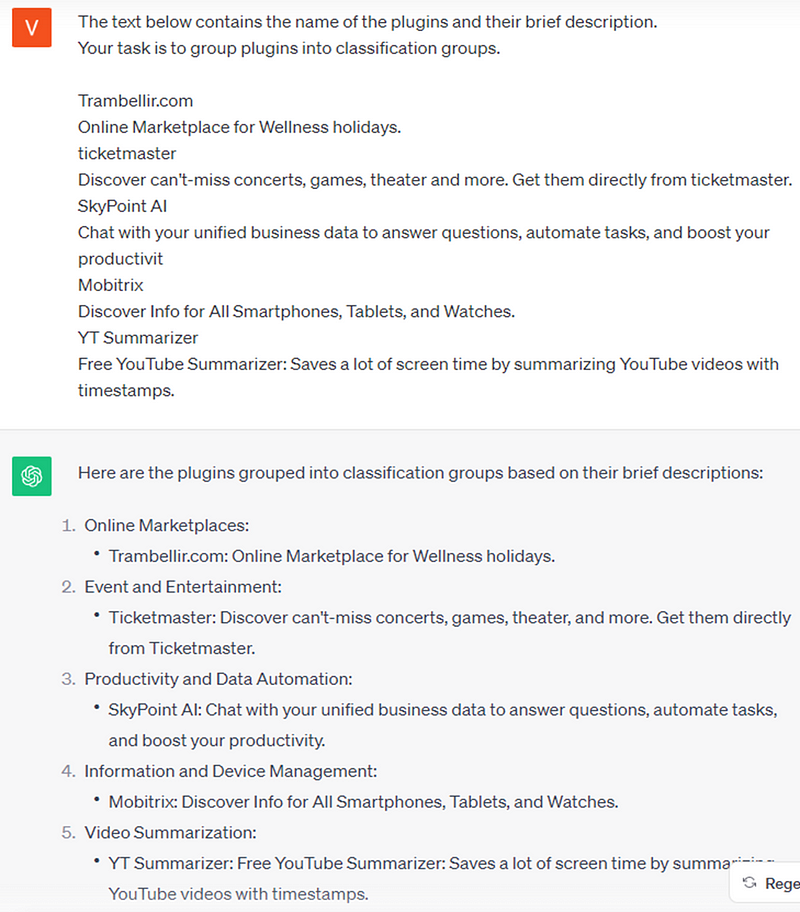
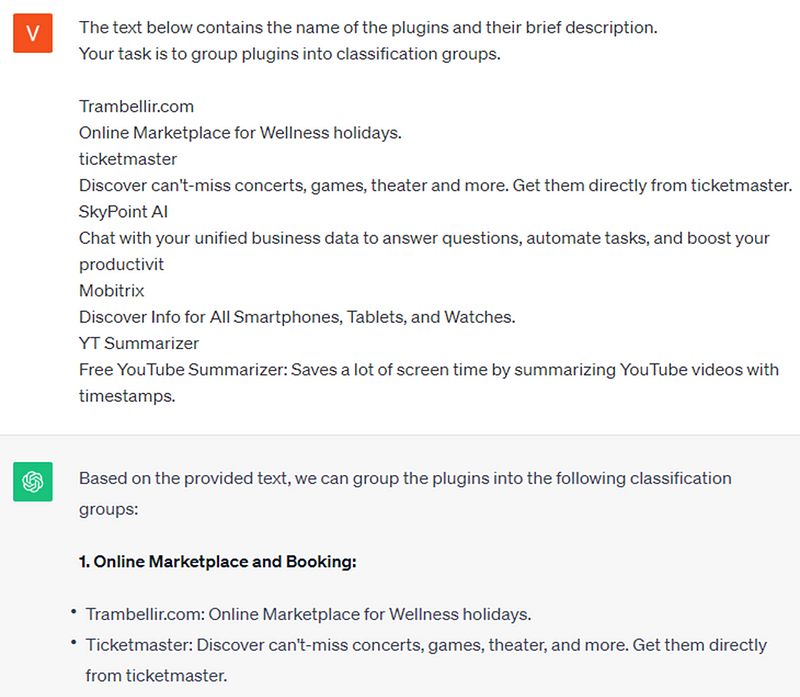

4. Consequently, I have developed an approach to address these issues while maintaining a controlled level of result accuracy.
Suggested approach
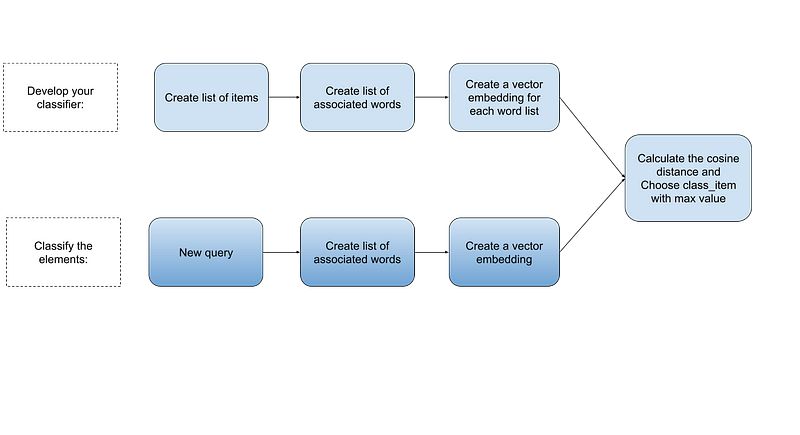
The approach involves the following steps:
Step 1: Develop your classifier, which can be as extensive and hierarchical as needed.
Step 2: Create list of associated words.
Utilize ChatGPT (or another Language Model) to create a “list of words associated with each classifier item or keywords-entities” for each classifier item. This step is crucial as the quality of the future classification process depends on it. The following guidelines should be adhered to during this step:
- The task should be to create a list of “associated” words rather than selecting “keywords.”
- The list should contain between 10 and 20 words.
- Avoid including proper names (unless the proper name is the essence of the classification) and words that are too general in the context of the classifier.
- Strive to ensure that the word list for each classifier element contains unique words.
Step 3: Create a vector embedding for each word list.
Step 4: Classify the elements to the appropriate classification items.
This step involves:
- Creating a list of word-entities associated with the element being classified.
- Calculating the vector embedding for this list of words.
- Calculating the cosine distance between the vector embedding of the element and the vector embeddings of all articles in the classification directory, selecting the article for which this value will be maximum.
The advantages of this approach include:
- Increased classification accuracy.
- Reduced dependency on specific text wording.
- The ability to control the model’s behavior by adding or removing certain words from entity lists and observing changes in classification accuracy.
- The approach is extensible and can be improved by increasing the number of associated words to more accurately account for context, or by adding an additional step to remove frequently repeated words from entity lists.
Let’s illustrate this with an example.
Import:
import os
import openai
import pandas as pd
import time
from openai.embeddings_utils import get_embedding, cosine_similarity
# embedding model parameters
embedding_model = "text-embedding-ada-002"
embedding_encoding = "cl100k_base" # this the encoding for text-embedding-ada-002
max_tokens = 8000 # the maximum for text-embedding-ada-002 is 8191
openai.api_key = 'YOUR KEY'Function:
def prepare_gpt(promt_desc,model,temper):
MODEL = model
response = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "user", "content": promt_desc}
],
temperature=temper,
)
return response.choices[0].message.content
def generate_words(x,pr_1,model):
promt_desc=f"{pr_1} {x}"
temper=0
response=prepare_gpt(promt_desc,model,temper)
return response
def label_score(review_embedding, label_embeddings):
return cosine_similarity(review_embedding, label_embeddings)
def get_class_item(x,dfclass):
dfclass['similarity']=dfclass["embedding"].map(lambda y: label_score(x, y))
return dfclass[dfclass.similarity == dfclass.similarity.max()]['class_item'].squeeze()
def get_max_score(x,dfclass):
dfclass['similarity']=dfclass["embedding"].map(lambda y: label_score(x, y))
return dfclass[dfclass.similarity == dfclass.similarity.max()]['similarity'].squeeze()STEP 1. Create your classifier:
classifier=[
'YouTube Video processing',
'Create Presentation',
'PDF prepare',
'Productivity increase',
'Entertainment and events',
'Web search',
'Creating Images',
'Charts analysis'
]
df_c=pd.DataFrame(classifier, columns=['class_item'])
STEP 2. Using ChatGPT, create for each classifier item a “list of words that are associated with that item or keywords-entities”:
pr_1="""
The following text contains a classifier item for ChatGPT plugins.
Write me a string of 10 comma-separated keywords-entities that define the following text:
"""
model="gpt-3.5-turbo"
df_c['class_words']=df_c['class_item'].map(lambda x: generate_words(x,pr_1,model))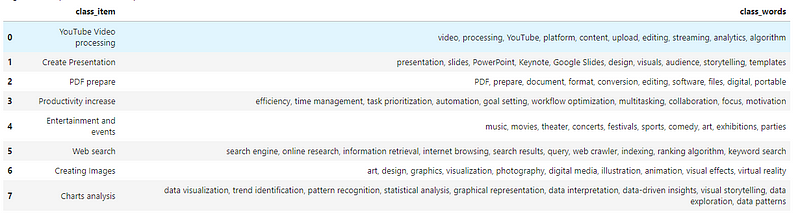
STEP 3. Create vector embedding
df_c["embedding"] = df_c['class_words'].map(lambda x: get_embedding(x, engine=embedding_model))
STEP 4. Classify the elements to the appropriate classification items
elements=[
"Trambellir.com Online Marketplace for Wellness holidays",
"ticketmaster Discover can't-miss concerts, games, theater and more. Get them directly from ticketmaster",
"SkyPoint AI Chat with your unified business data to answer questions, automate tasks, and boost your productivit",
"Mobitrix Discover Info for All Smartphones, Tablets, and Watches",
"YT Summarizer Free YouTube Summarizer: Saves a lot of screen time by summarizing YouTube videos with timestamps"
]
df_e=pd.DataFrame(elements, columns=['element'])
pr_1="""
The following text contains a classifier item for ChatGPT plugins.
Write me a string of 10 comma-separated keywords-entities that define the following text:
"""
model="gpt-3.5-turbo"
df_e['class_words']=df_e['element'].map(lambda x: generate_words(x,pr_1,model))
df_e["embedding"] = df_e['class_words'].map(lambda x: get_embedding(x, engine=embedding_model))
df_e["class_item"] = df_e['embedding'].map(lambda x: get_class_item(x, df_c))
df_e["similarity"] = df_e['embedding'].map(lambda x: get_max_score(x, df_c))
df_e[['element',"class_item","similarity"]]
As a result, for the elements: - We selected the most suitable classification groups from the available options. - The names of these groups align with our classification groups, ensuring no discrepancies or misalignments. - We quantitatively assessed the degree of alignment between each element and its corresponding classification group. - When we run this code again we will get the same expected result.