
Using SQLite with Python
A short tutorial on using sqlite3 in Python

SQLite is a lightweight database that does not require a separate server. SQLite is very popular in web applications and requires no administration. I use SQLite to store structured data that I scrape from the internet, such as cryptocurrency prices.
In this short note, we will go over the key commands to use SQLite with Python.
We will look at:
- Creating a new database on disk
- Creating a new SQL table
- Inserting a Pandas dataframe into the new SQL table
- Extracting data from a SQL table back into Pandas dataframe
We will be using sqlite3.
import sqlite3Creating a new database on disk
First let us create a new SQLite database on disk. This will create a database for you in your current working directory.
con = sqlite3.connect('newDatabase.db')If the filename is :memory: then it will create a new database that resides in RAM instead of on disk.
con = sqlite3.connect(':memory:')Now we have opened up a new connection.
If you want to close your connection, you can use the command:
con.close()Right now, we don’t need to do this, as we’re going to use the connection to create a table in the new database.
Creating a new table
Firstly, let us review the datatypes available to us in SQLite.
- NULL
- INTEGER — the value is a signed integer
- REAL — the value is a floating point value
- TEXT — the value is a text string
- BLOB — the value is a blob of data, stored exactly as it was input
In the example below, we create a simple two column table called tab1 . One column is called “key” and the other column is called “number”.
c = con.cursor()
sql_create_tab1_table = """ CREATE TABLE IF NOT EXISTS tab1 (
key integer PRIMARY KEY,
number integer)
"""c.execute(sql_create_tab1_table)Converting a Pandas DataFrame to SQL table
Let’s generate some random data to insert into our table tab1 .
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(0,100,size=(100, 1)), columns=[ 'number'])
df.insert(loc=0, column='key', value=np.arange(len(df)))
After generating some random numbers, we can insert this into tab1 .
df.to_sql('tab1', con, if_exists='append', index=False)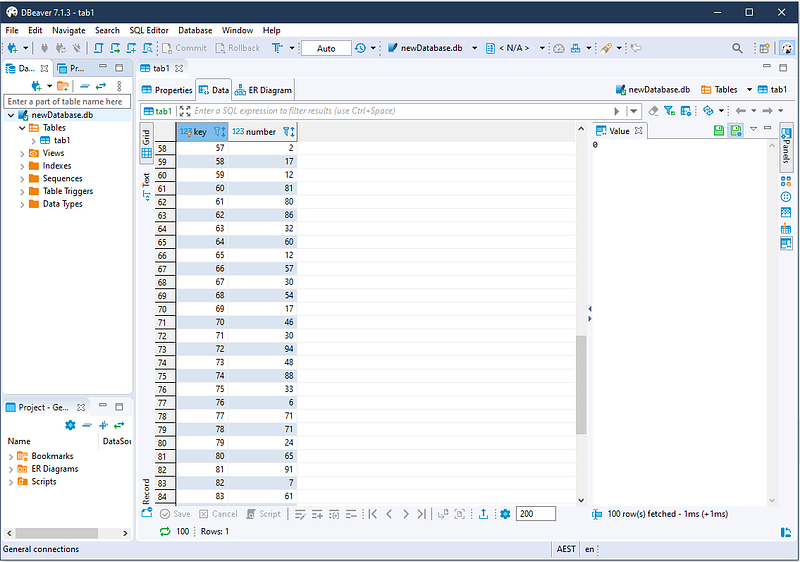
Extracting data from SQLite back to Pandas dataframe
Next, we show that we can extract data from tab1 back into Python. Here we decided to take all the data where the key is greater than 95.
c.execute('select * from tab1 where key > 95')
result = pd.DataFrame(c.fetchall())The output back is a pandas dataframe shown below.
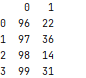
After you’re done you can close the cursor
c.close()And also, close the connection.
con.close()