
Using Heuristic to help Search Algorithms
Helping search algorithms to move towards right direction, reducing the number of nodes being explored.
Informed Guesses for Search Algorithms
Search algorithms which we discussed about in earlier post, mostly use heuristic to reduce the number of nodes being explored which eventually reducing the amount of time the algorithm take to produce a solution plan.
Algorithms such as A* and GBFS (Greedy Best-first Search) rely heavily on heuristic whereas Depth-first Search and Breadth-first Search use it when the nodes being compared have equal value, or same length.
Definitions
Starting with a few definitions.
Heuristic is an estimate of the minimum cost from a state to goal state. Usually minimum cost is written as h*(s) and our estimate, the heuristic is written as h(s). Formally written as follows:
h(s)≈h*(s)=min{cost(π)∣γ(s,π) satisfies g}
The heuristic is said to be admissible if the following holds
0 ≤ h(s) ≤ h*(s)
and heuristic of goal node is 0, h(g) = 0.
Trade-off
Heuristic is not a magic, it only uses all the available information to make a guess whether choosing a node is likely to bring the agent closer to the goal state. It helps the algorithms so that they don’t need to explore the entire search space which can be really large.
The trade-off is between the amount of time required to run the heuristic function and the number of nodes that can be reduced by search algorithms.
Domain-specific vs. Domain-independent Heuristic
In some domains, using domain-specific heuristic function provides a big help. For example in path planning where the destination is known from the beginning we can simply use distance as heuristic, such as Euclidean Distance,
dist((sx, sy), (gx, gy)) = √(gx-sx)² + (gy-sy)²
or Manhattan Distance,
dist((sx, sy), (gx, gy)) = |gx-sx| + |gy-sy|
It is more complex for domain-independent problems, to compute the heuristic we need to run some kind of search.
Example: Heuristic for Path Planning Problems
To illustrate heuristic in path planning problems, we add visualisations to our Pacman Agent, dots in green are the chosen nodes and dots in red are the explored nodes.
As usual, the goal is to eat all foods, we use a simple planning problem here for better illustration.
We use A* algorithm to illustrate the differences. Below is without heuristic (heuristic of all nodes are set to zero).
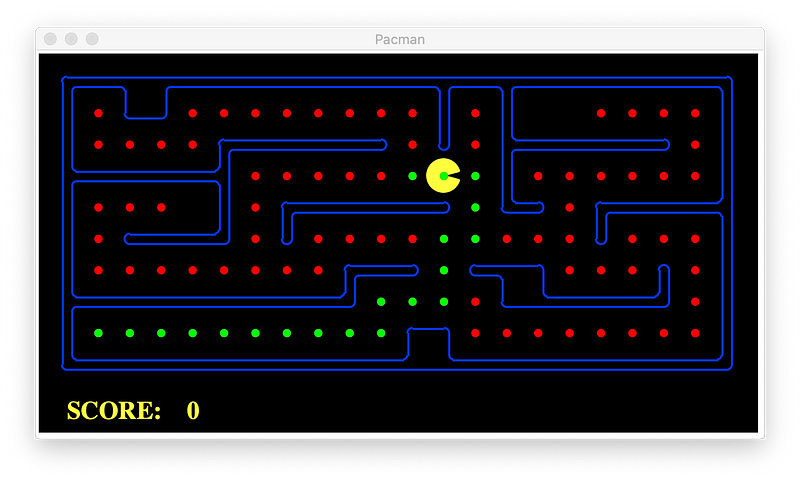
We can see that A* almost explores all available nodes (in red) and selected the optimal path (in green).
Let’s now see A* with Euclidian Distance Heuristic.
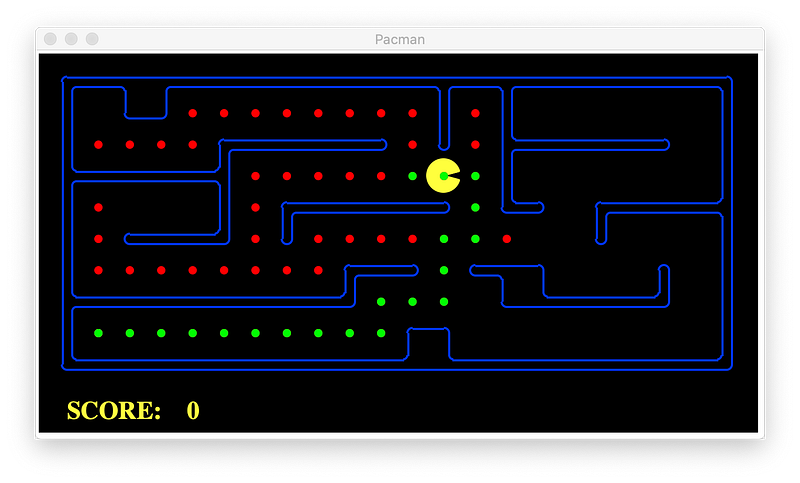
We can see that A* explores less nodes and still select the same optimal path.
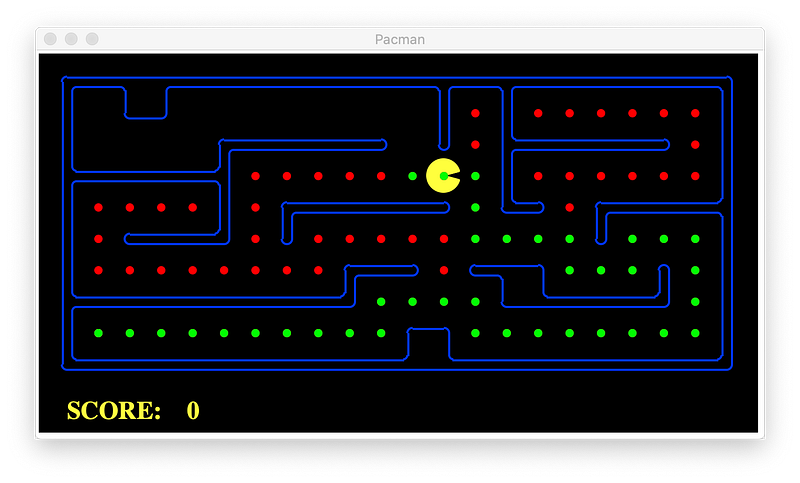
Finally, let’s see Manhattan Distance Heuristic.
For this path planning problem the Manhattan Distance heuristic produces the least number of explored nodes and again selected the same optimal path.
From the illustrations above we can see where the heuristic function helps in cutting the amount of time spent by search algorithms. However, those heuristics are only for domain-specific, in this case path planning problems with known destination (goal).
For domain-independent planning problems, it is more complex.
Domain-independent Heuristic
One way to produce heuristic functions is relaxing Planning Domain and Planning Problem.
For Planning Domain, that means weakening the constraints on what the states, actions and plans are.
For Planning Problem, that means weakening the constraints on when an action is applicable and what the effects are.
In the next post we will look at a few algorithms to compute domain-independent heuristic, they are:
- Max-cost Heuristic
- Additive Heuristic
- Delete-Relaxation Heuristic
Revisit the algorithms with heuristics
Now that we have heuristic, we can revisit our algorithms in earlier post and compare their explored nodes and selected nodes to see how well they perform in terms of the execution time as well as the optimality of the plan.
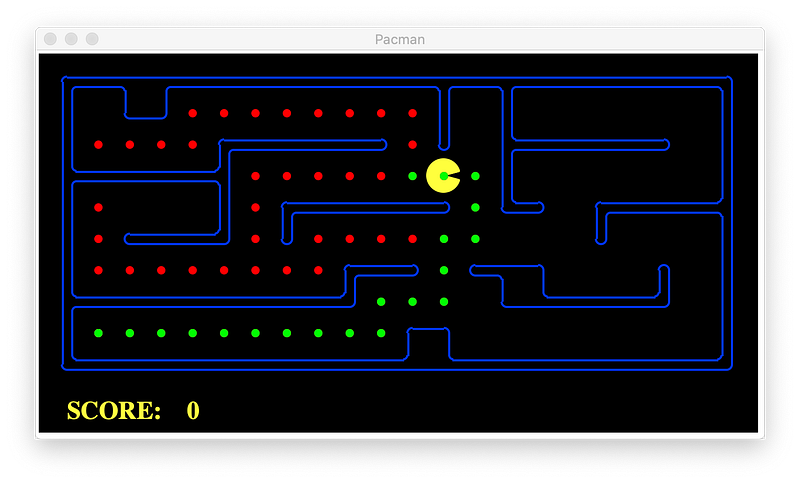
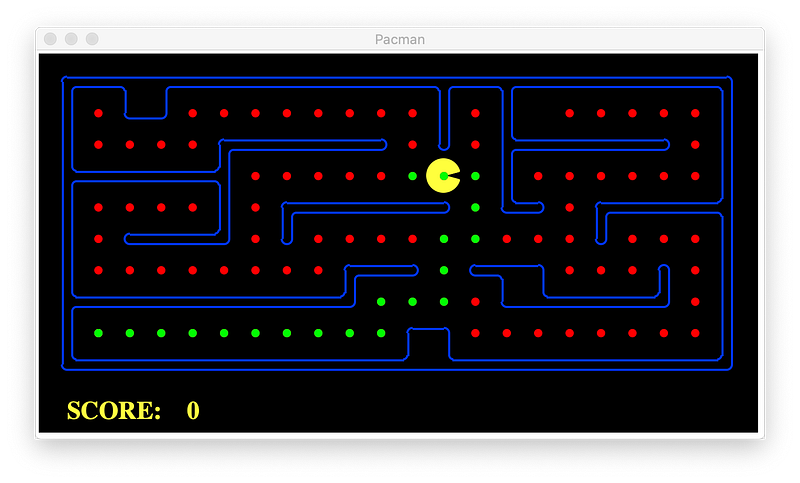
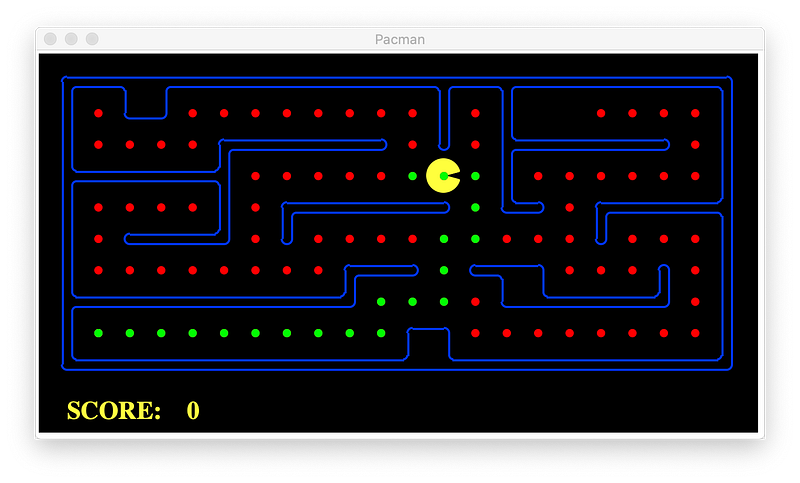
To compare the algorithms we use the planning problem above for simplicity, and we use same heuristic, Manhattan Distance.
BFS
Without heuristic:
With heuristic
DFS
Without heuristic:
With heuristic:
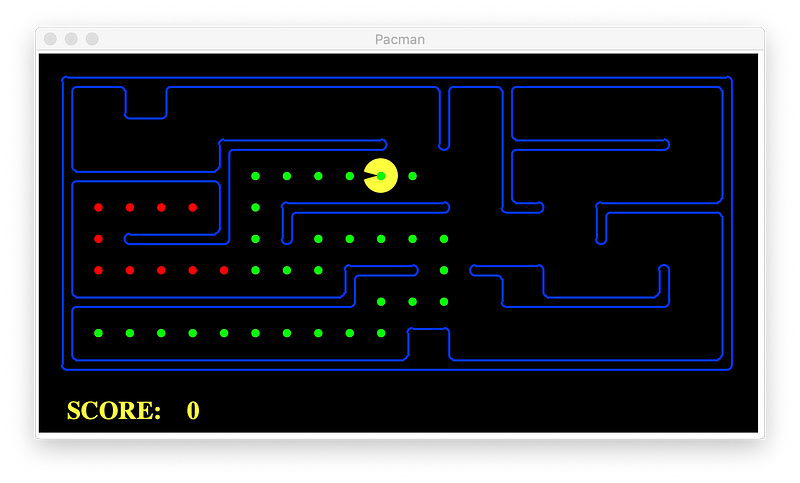
Uniform-cost Search
Uniform-cost search does not use heuristic, here is the result:
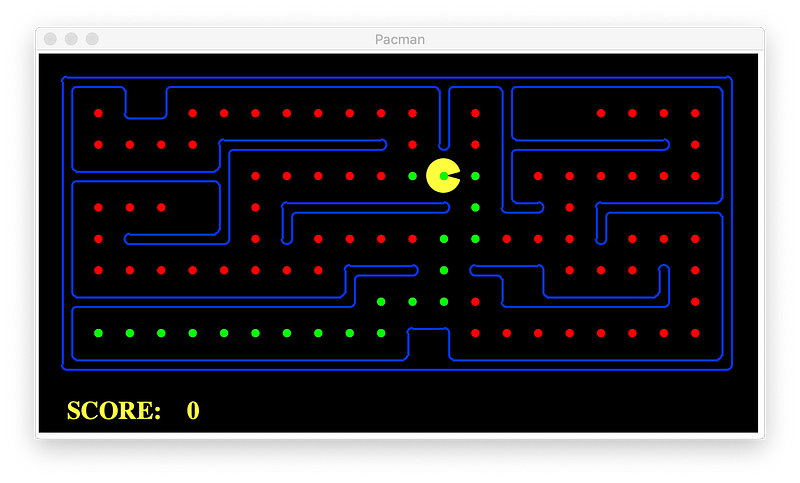
A*
Without heuristic, the result is the same as Uniform-cost Search.
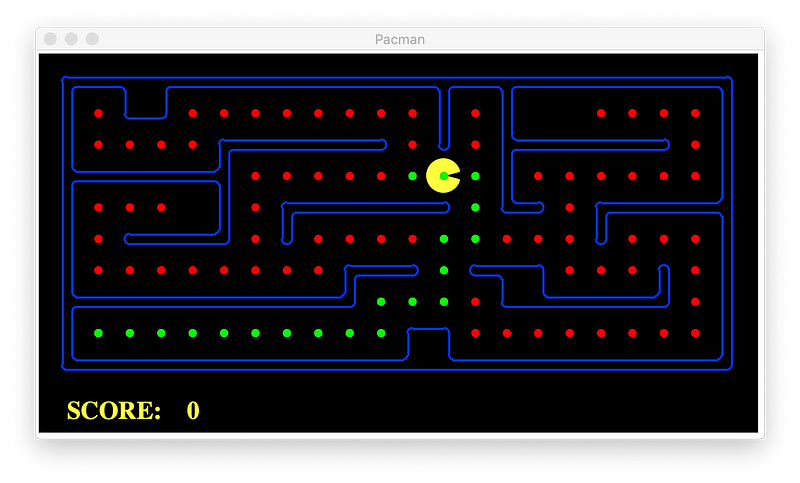
With heuristic:
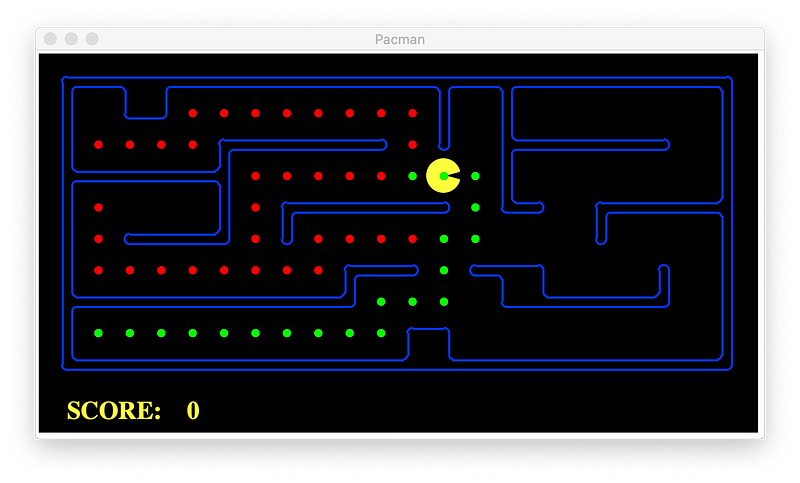
GBFS
Without heuristic (same as Uniform-cost Search):
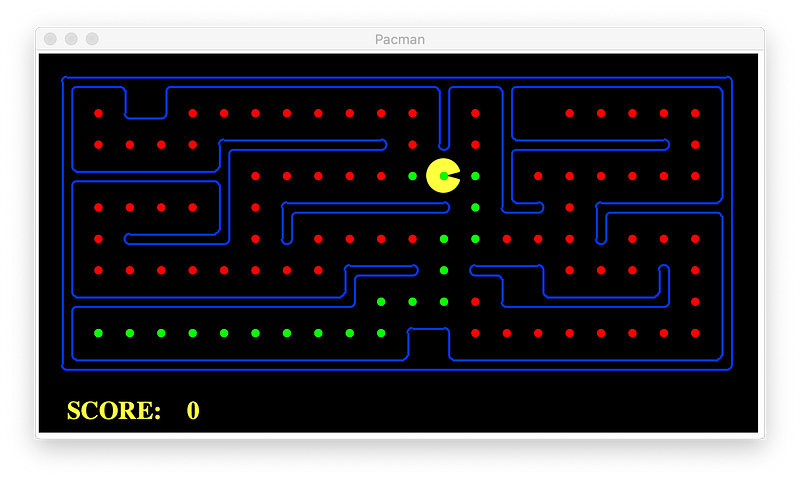
With heuristic:
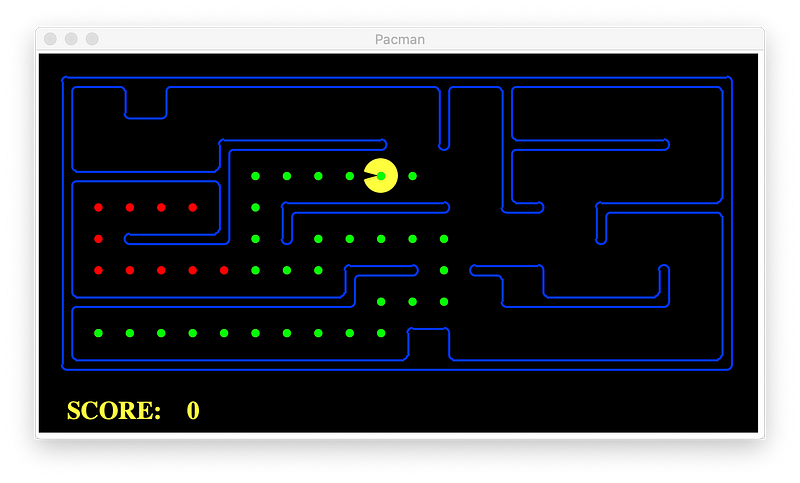
We can now see that A* produces an optimal path and reasonable number of explored nodes when using heuristic. Algorithms like GBFS and DFS are faster but produce less optimal path when using heuristic.
Depending on the type of problems we can choose wisely the right algorithm and heuristic.
The example that we use here is rather simple, because I want to illustrate the concepts. In practice, especially for domain-independent planning problems, we need more complex heuristics. We’ll discuss about that in the next post.




