
Using Customer and Product Features in Recommender Systems

Nowadays, with a massive increase in the number of product variations, many companies rely heavily on Recommender Systems which helps them to narrow down the number of items they present to their customers from the front-end. Think about Netflix that recommends movies to its subscribers.
“A lot of times, people don’t know what they want until you show it to them.” Steve Jobs
The entire idea behind recommender systems is to predict, for the given pair of user and item, whether this user will be interested in this particular item. There are different ways that recommender algorithms learn about the target user and about the available items to make a selection out of a large number of product variations. Depending on the type of data these algorithms use to learn about the users and items, they are classified into the following 3 groups:
Collaborative Filtering Algorithms: use only the product ratings as means for learning about the user preferences
Content-Based Algorithms: use content such as product reviews to learn about the user preferences
Hybrid Algorithms: use both product ratings and reviews to learn about the customer preferences
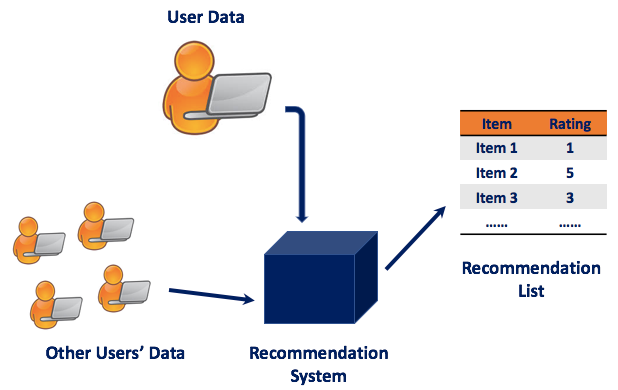
Customer and Product Specific Features
Most of the existing recommender algorithms are of Collaborative Filtering type because of their simplicity, whereas using additional sources of information such as product reviews or information about users and items can help to learn better about the customers and products, which will improve the quality of the recommendations.
The majority of online retailers collect information about their clients, such as (predicted) gender or age/age-group, during the onboarding process. Additionally, sophisticated businesses collect and store metadata about the items or services they sell. For example, movie streaming companies collect detailed information about their films such as the genre or the director of a movie.
Matrix Factorization
This method which is also referred as the Latent Factor Model, is one of the most popular rating-based algorithms that uses dimensionality reduction to predict and fill in the missing ratings in the User-Item rating matrix where each entry corresponds to the rating assigned by a user to an item. The goal of this method is to rotate the axis of this large and sparse matrix so that the pairwise correlations between the dimensions can be removed and it can be decomposed into two smaller and denser matrices with the same rank.
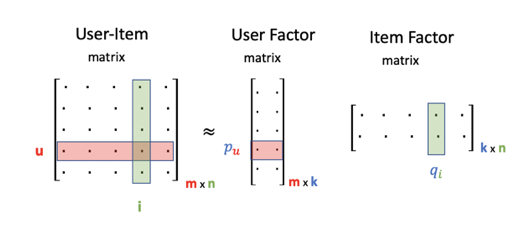
A row in User Factor matrix describes the affinity of a user towards the user-item rating matrix whereas a column in Item Factor matrix describes the affinity of that particular item towards the user-item rating matrix. So, according to the LFM model, the rating of a user assigned to an item can be estimated by obtaining the dot product between the user vector and the transpose of the item column from the User Factor and Item Factor matrices, respectively.
Adding Extra Features to Matrix Factorization
Assuming that extra user features have unique values per user and extra item features have a unique value per item, one can represent each of these user or item-specific features as a one-dimensional vector. For example, if we want to add an extra user feature for age, then we can represent this feature by m x 1 vector where m is the number of users and each entry of this vector contains the age of a specific user.
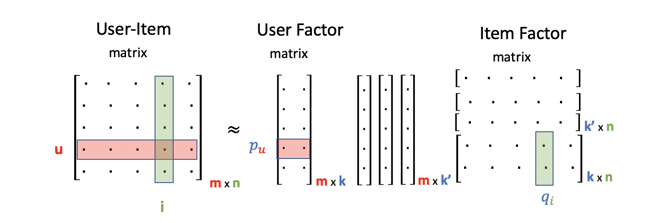
So, if there are 3 extra user characteristics one can represent them in the form of vectors, 3 vectors each with m elements for m customers which will act as additional 3 columns for the User Factor matrix. In the case of item features, 3 vectors with n elements will be added as additional rows to the Item Factor Matrix. When generalizing this idea to random k’ extra features, the idea stays the same, k’ user features can be added as extra columns to the User Factor Matrix and k’ item features can be added as extra rows to the Item Factor Matrix as long as the amount of extra user-features is equal to the extra item-features because of the underlying matrix multiplication between the User Factor and Item Factor matrices where the number of columns of the user matrix needs to be equal to the rows of the item matrix.
This is part of an academic paper with a title Utilizing Textual Reviews in Latent Factor Models for Recommender Systems that will be presented in 36th ACM/SIGAPP Symposium on Applied Computing (SAC 2021) in Web Technologies Track.
For LDA-LFM Recommender System’s Python Code check out the following Github link: LDA-LMF Github
Additional Resources
If you liked this article, here are some other articles you may enjoy:
The Ultimate Data Science Bootcamp by LunarTech
Ready to break into Data Science and AI in 2023? Aspiring to become a job-ready Data Scientist in the shortest amount of time? LunarTech.ai, an online tech education platform, offers all-inclusive BootCamp which also contains A/B Testing complete course, The Ultimate Data Science Bootcamp that is your ticket to success.
The Ultimate Data Science Bootcamp offered by LunarTech is designed to Ignite your Data Science career, transforming you into a world-class job-ready Data Scientist. We offer everything you need in one comprehensive, affordable package. This bootcamp provides a strong foundation in essential theoretical and technical skills, practical experience through real-world projects, and comprehensive career guidance including interview preparation.
We strike the perfect balance between teaching core fundamentals and practical implementation. With LunarTech, you’re not just learning, you’re preparing for a successful career in data science at your own pace. (For the full curriculum of the bootcamp click here)
But we go beyond training. We offer job placement assistance, expert resume building, and a community of ambitious individuals, all striving for success. With LunarTech, you’re not just enrolling in a program; you’re propelling toward a brighter future in Data Science and Artificial Intelligence.
So, are you ready to seize the opportunities of 2023 and become a job-ready Data Scientist? Your future is just a click away. (Enroll to The Ultimate Data Science Bootcamp click here)