

Using a Generalised Translation Vector for Handling Misspellings and Out-of-Vocabulary (OOV) words like Abbreviations
Introduction
In this article, I will be sharing a novel approach on managing misspellings and abbreviations. This idea is not my own but I think it is really interesting and decided to test it out and showcase my own results here.
This idea came from Ed Rushton from a fast-ai forum thread I stumbled upon while doing my own research. I highly recommend you to read his initial tests.
I took additional steps to measure the effects of applying Ed’s approach on a downstream Natural Language Processing (NLP) task to see if it would increase classification accuracy.
The methodologies like using external data sources to create a Generalised Transition Vector or testing the approach on abbreviations/OOV words are my own.
But before I begin, it is important for you to know what word embedding are and why they are important. If you need a quick refresher, please take 3–5 minutes to read through the first part of the series on Out-of-Vocabulary (OOV) word embeddings.
The article link also talks about generating word embeddings for OOV words like Singlish — Local Singapore English. This article is actually an extension of my research on how best to work with Singlish.
With your memories refreshed, let’s begin.
The underlying principle of this approach comes from how word embeddings interact with one another. The classic word analogy example of this “interaction ” can be seen below:
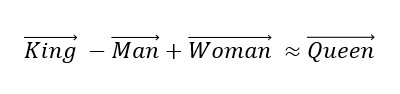
Intuitively, this “equation” in English should make sense to you. In vector space, the math will look like this:
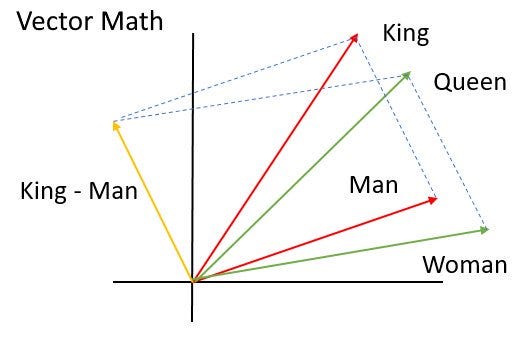
To show you that this is really the case, I have ran some code using the pre-trained word embeddings from Stanford — GloVe. These word embeddings were trained on Wikipedia 2014 + Gigaword to attain 6 billion tokens and 400,000 unique vocabulary words.
Since each word is represented in a 100 dimension space (i.e. 100 numbers), I applied T-distributed Stochastic Neighbor Embedding (T-SNE) to reduce the dimensions to only 2 for visualisation purposes.
Figure 3 below is a visualisation of the words of interest together with the mathematical equation to help you better understand the relationship between the words.
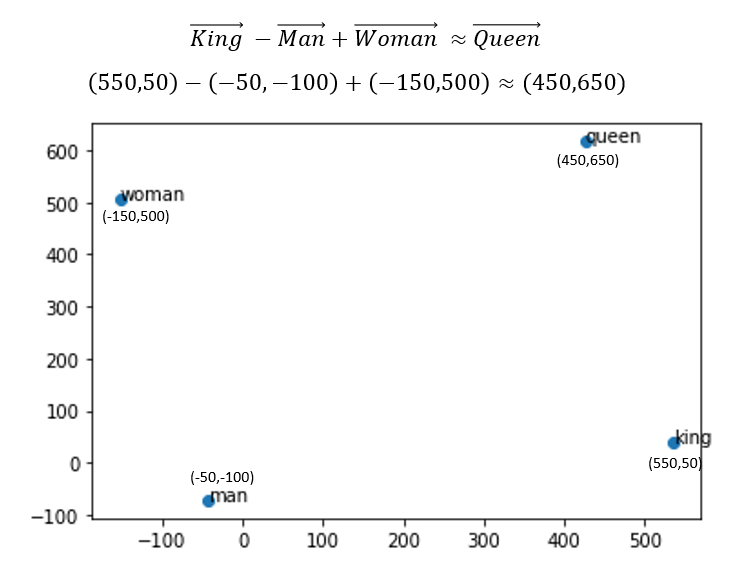
As you can see, properly trained word embeddings can truly represent the relationships between words. The numerical vectors generated by a model isn’t just random. These numbers do hold some meaning.
Unbeknownst to you, what I’ve just mentioned above are implementations of Translation Vectors.
A translation vector is a type of transformation that moves points/figures in the coordinate plane from one location to another.
It is a translation vector that I will be using to move misspelled/abbreviated words towards words that best explain what those words mean.
“Wait a minute... Are you saying that there is a translation vector that could move misspelled words to it’s respective correct spelling of the word in vector space?”
The answer is yes.
To top it all off, this translation vector works even for abbreviations or OOV words. It will move these words closer to words that best represent what the abbreviation or OOV words truly mean.
So how is the Generalised Translation Vector created?
This series of tests were performed using GloVe word embeddings by Stanford.
In this segment, I will first share on the experiments to handle misspelled words. Then, I will move to the experiments I did to handle abbreviations or OOV words. After which, I will attempt to explain why I think this translation vector is working. Before ending off with testing the effects of this approach on downstream NLP task.
Handling misspelled words
To handle misspelled words, I initially thought that the true spelling of the misspelled word should appear somewhere near the misspelled word.
To my surprise, I was wrong. That wasn’t the case at all.
Here are some of the outputs of the misspelled words and their closest neighbours in vector space.
Input word: becuase
Closest 10:
becuase 1.0
becasue 0.768174409866333
beause 0.740034282207489
beacuse 0.7367663979530334
becaue 0.7192652225494385
athough 0.6518071889877319
althought 0.6410444378852844
becuse 0.6402466893196106
inspite 0.631598711013794
beleive 0.6224651336669922Input word: athough
Closest 10:
athough 0.9999999403953552
altough 0.7992535829544067
althought 0.7640241980552673
eventhough 0.7555050849914551
“ 0.7399924993515015
addding 0.7239811420440674
lthough 0.7079077363014221
surmising 0.6986074447631836
howver 0.6851125359535217
aknowledged 0.6843773126602173Input word: aknowledged
Closest 10:
aknowledged 1.0
ackowledged 0.8641712665557861
inisted 0.8378102779388428
admited 0.8242745399475098
annonced 0.81769859790802
avowing 0.7911248803138733
testifed 0.7896023392677307
addding 0.7784746885299683
sasid 0.7712235450744629
acknowleges 0.7595445513725281Notice in all the examples above, none of top 10 neighbours are the correctly spelled word?
I started to run nearest-neighbors on more and more misspelled words till a pattern emerged and I concluded that…
All misspellings seemed to be grouped together in vector space.
Note: BIG emphasis on the word “seemed” here. Cause I don’t really know for sure.
If I were to crudely draw it out, it might look like this:
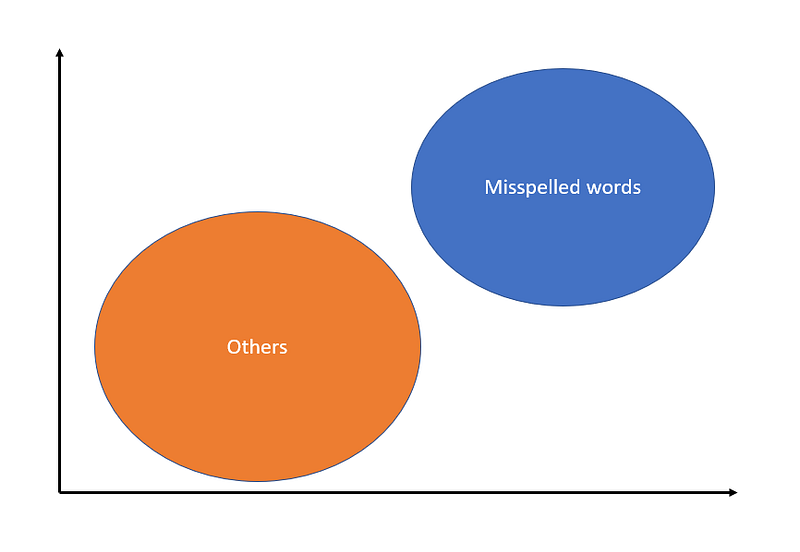
The next step was to create a translation vector that would push misspelled word embeddings closer to their correct spellings like:
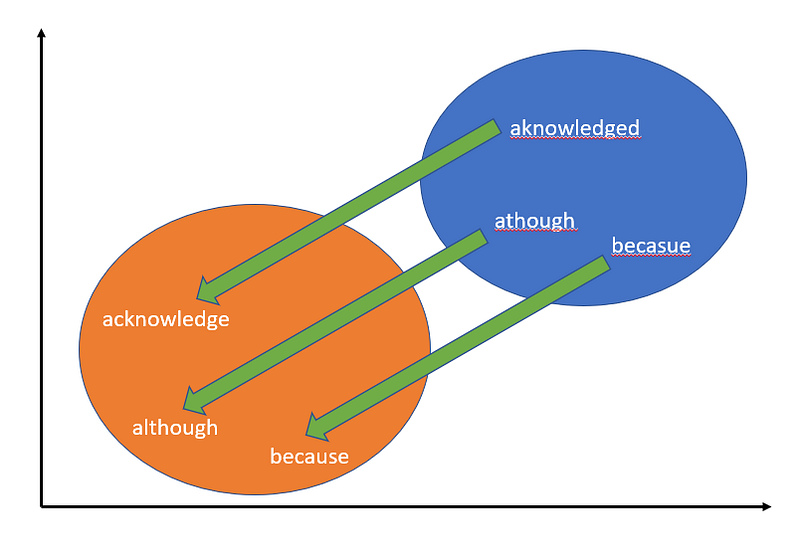
The process is as such:
- Run cosine distance to get nearest 10 words to misspelled word of choice.
- For each of the 10 nearest words, take the word vectors of each and subtract it from the word vector of the correctly spelled word.
- Calculate the average of all of these word vectors in step 2. This becomes the translation vector for the word of choice in step 1.
- Test the translation vector.
STEP 1:
Input word: becuase
Closest 10:
becuase 1.0
becasue 0.768174409866333
beause 0.740034282207489
beacuse 0.7367663979530334
becaue 0.7192652225494385
athough 0.6518071889877319
althought 0.6410444378852844
becuse 0.6402466893196106
inspite 0.631598711013794
beleive 0.6224651336669922STEP 2:
sum_vec = ((glove["because"]-glove["becuase"]) + (glove["because"]-glove["becasue"]) +
(glove["because"]-glove["belive"]) + (glove["because"]-glove["beause"]) +
(glove["because"]-glove["becaue"]) + (glove["because"]-glove["beleive"]) +
(glove["because"]-glove["becuse"]) + (glove["because"]-glove["wont"]) +
(glove["because"]-glove["inspite"]) + (glove["because"]-glove["beleive"])
)STEP 3:
translation_vec = sum_vec / 10STEP 4:
real_word = glove["becuase"] + translation_vecClosest 10:
because 0.9533640742301941
but 0.8868525624275208
though 0.8666126728057861
even 0.8508625030517578
when 0.8380306363105774
if 0.8379863500595093
so 0.8338960409164429
although 0.8258169293403625
that 0.8221235871315002
. 0.8172339797019958Take a look at the results in Step 4 above. Notice how the translation vector works? The misspelling of the word “becuase” has been pushed to the true spelling “because”.
Now that we know a translation vector for handling misspelling is possible…
The question now is:
Could we create a Generalised Translation Vector for ALL misspelled words?
Yes you can.
Creating the Generalised Translation Vector
I first took a list of commonly misspelled English words from Wikipedia — https://en.wikipedia.org/wiki/Commonly_misspelled_English_words.
There were 257 misspelled words in total.
Next, I ran each word through the steps mentioned above (Steps 1 to 4). Of 257 words, only 101 appeared in GloVe. Hence, 101 translation vectors were computed.
The next step was simple, to get the Generalised Translation Vector, simply get the average of all 101 translation vectors.
Now, test the Generalised Translation Vector on unseen misspelled words. i.e. words not in the “commonly misspelled English words” list.
Below are some results:
TEST 1:
real_wd = word2vec["altough"] + generalised_translation_vector
Closest 10:
although 0.6854726149933246
though 0.6850398829597103
fact 0.6601790765388513
however 0.6519905808301287
moreover 0.6505953960788824
unfortunately 0.6351817153852294
why 0.6347064566357319
neither 0.6276211965351607
because 0.626889292147095
there 0.6217807488951306TEST 2:
real_wd = word2vec["belive"] + generalised_translation_vector
Closest 10:
belive 0.7508078651443635
believe 0.6821138617649115
we 0.6761371769103022
think 0.6593009947423304
i 0.6531635268562578
suppose 0.6463823815449183
know 0.643466951434791
why 0.6394517724397308
n't 0.6282966846577815
there 0.6273096464496348TEST 3:
real_wd = word2vec["howver"] + generalised_translation_vector
Closest 10:
moreover 0.6818620293021886
nevertheless 0.6726130620400201
neither 0.6667918863182073
unfortunately 0.6568077159269134
though 0.6563466579691621
indeed 0.6555591633099542
nor 0.6473033198348439
noting 0.6457127023810979
fact 0.6423381172434424
however 0.639381512943384As you can see, on only 101 translation vectors, the Generalised Translation Vector does not perform too badly.
However since it was only modeled on 101 translation vectors, it did not perform well on the word “howver”. This should easily be rectified if we averaged in more translation vectors.
How does this Generalised Translation Vector perform on abbreviated OOV words?
To test this, I keyed in an abbreviation “ftw” to find it’s nearest neighbours without applying the Generalised Translation Vector.
The results were as such.
Closest 10:
ftw 1.0
ftg 0.6485665440559387
ccts 0.6331672072410583
srw 0.6109601855278015
efts 0.6108307242393494
cmtc 0.6050553321838379
tfts 0.6022316217422485
okl 0.6015480756759644
jrtc 0.597512423992157
cacs 0.5950496196746826As you can see, all abbreviations seem to have been grouped together in the same vector space. No true value from this yet.
Let’s apply the Generalised Translation Vector and see what happens.
real_wd = word2vec["ftw"] + generalised_translation_vectorClosest 10:
ftw 0.6879674996316458
training 0.5672708687073991
wing 0.5443954733951136
) 0.5178717182506045
fighter 0.4847256601149461
flying 0.4701913180805779
tactical 0.4680302804591241
combat 0.4674059145693783
squadrons 0.4593665765485848
foot 0.459181622011263Notice something interesting here? If you Google “ftw combat”, you will realise that “ftw” stands for “Flying Training Wing”.
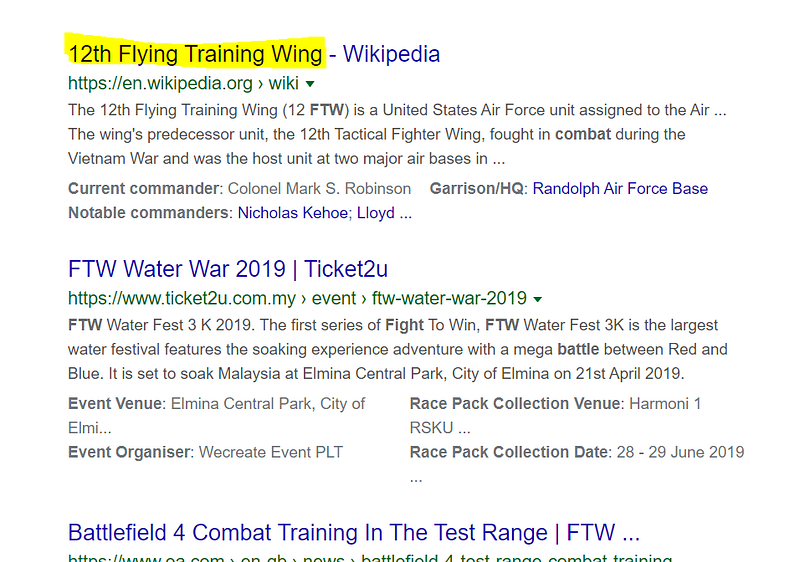
This shows that the Generalised Translation Vector works even for abbreviation and is not just limited to misspellings.
It managed to translate the abbreviation of “ftw” to what it truly represents in the text. i.e. Military words.
Now that you have seen the results, if you are like me, you’d be asking yourself how this is possible. The next section is my hypothesis on what I think is happening.
Why I think the Generalised Translation Vector works
This segment is purely a hypothesis. I do not claim any of this to be true. Everything I say here is based solely off reviewing the results and inferring what I think is happening.
Recall figure 4 and figure 5 above.
What I think is happening kind of looks like this:
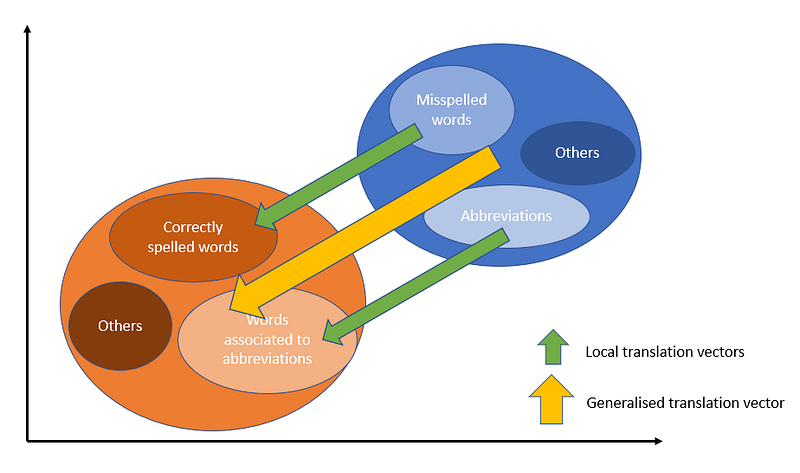
First off, based on my testing, localised translation vectors seem to work best i.e. better accuracy.
Localised translation vectors refer to vectors of the cluster with abbreviations or misspelled words.
But I think the Generalised Translation Vector works because it is simply the average of all local translation vectors. It is simply pushing everything in that blue circle back into the orange circle.
This on the assumption that ALL misspelling, abbreviation or OOV words are clustered together in the blue circle.
And because every misspelling, abbreviation or OOV words are together, having a Generalised Translation Vector simply pushes these words closer to the words that truly represents that they actually mean.
Important Notes:
- Translation Vectors only work for the words it was trained on. I have tried to take a Generalised Translation Vector made from GloVe and try to apply it to a completely different dataset but with no avail.
- For misspellings to be corrected, the correctly spelled word has to exist in the corpus to begin with.
Having seen the results so far, what do you think was learned by the model? Does my hypothesis make sense? What are your hypotheses?
Application of the Generalised Translation Vector
After all that is said and done, the next question you’re probably wondering is:
“So what? What can I do with this knowledge?”
In this segment, I will share the results of two sets of codes ran on a simple multi-classification task on toxicity of comments. i.e. Toxic, severely toxic, obscene, threatening, insulting or personal attacks.
Here’s a glimpse at how the training set looks like:
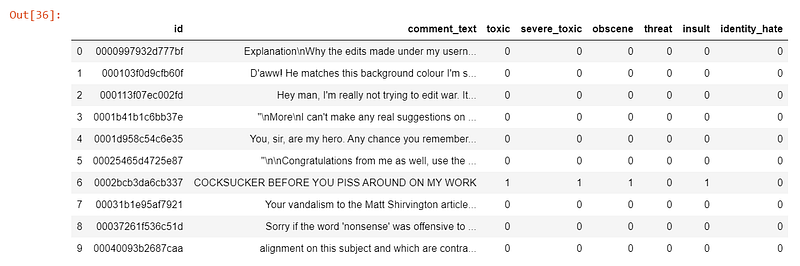
The training set was split into 127,656 training samples and 31,915 validation samples.
I trained a simple bidirectional LSTM model using a binary cross entropy loss function and Adam optimiser with Keras.
In this first case, I used the pre-trained word embeddings from GloVe without applying the Generalised Translation Vector.
Here are the results:
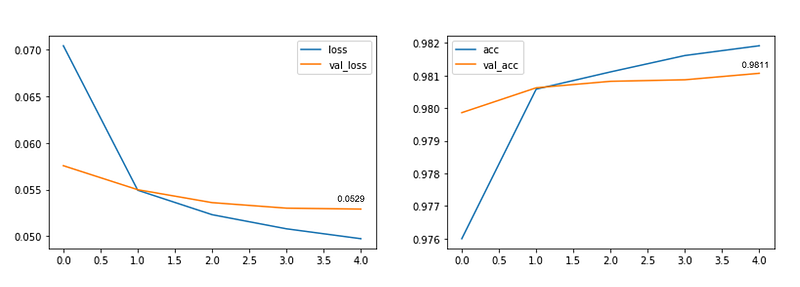
On a test set of 153,164 samples, model accuracy was: 93.7687%
Using the same configuration above, I changed out the GloVe word embeddings to the embeddings where I applied the Generalised Translation Vector.
To ensure that I only translated vectors that needed translation, I ran the GloVe embeddings through an existing vocabulary list from the 20Newsgroup data set.
I only translated vectors that did not appear in the vocabulary list of 61,118 correctly spelled words.
Here are the results:
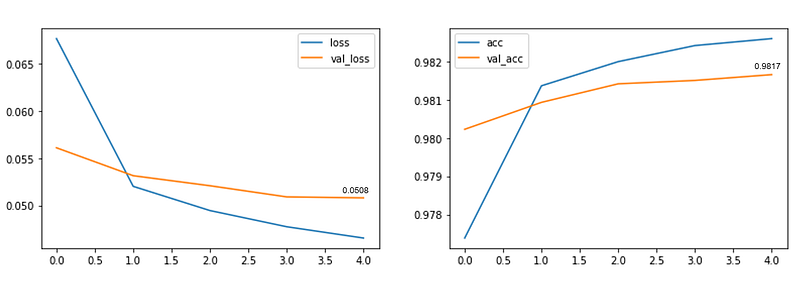
On the same test set above, model accuracy was: 93.8267%
The difference in accuracy was only a marginal 0.058%.
From this experiment, it was inconclusive as to whether applying a Generalised Translation Vector on misspelled or OOV words helps in improving accuracy for any downstream NLP tasks.
Intuitively, however, I believe it does help. Perhaps not for this task per se but other NLP tasks?
Quick Summary
- I found a thread on fast.ai interesting and decided to test out someone’s (Ed Rushton) novel approach to handle misspellings.
- I took it a step further by testing this approach on abbreviations/OOV words and concluded that it does work on these words as well.
- I took it even further to see if it helps to improve accuracy on a downstream NLP task like classification and found my experiment to be inconclusive.
Ending Notes
I definitely found this exercise to be extremely interesting and would most likely be using it for my other NLP projects in the future.
All praise and thanks goes to Ed Rushton for coming up with such a novel approach.
What I would want to try in the future would be this:
Instead of creating a General Translation Vector, perhaps run Localised Translation Vectors depending on which cluster a word falls into.
For example, if the word is a misspelling, run the Local (misspelling) Translation Vector. If the word is an abbreviation, run the Local (abbreviation) Translation Vector.
I strongly believe this localised approach is the next step to make this approach more robust.
I hope my experiments on this has helped you gain deeper insights into how word embeddings work and perhaps, piqued your interest enough for you to do your own testing.
Till next time, adios amigos!
If you are looking for NLP datasets to work with, click here for a curated list I created! :)
LinkedIn Profile: Timothy Tan