
Unveiling the Future of Media Analysis: Revolutionizing Active Speaker Detection in the Digital Age
Active speaker detection is a crucial tool in the realm of computational media intelligence. By seamlessly integrating audio and visual information, these tools provide valuable insights into the dynamics between speech and visual cues in media content. Whether it’s analyzing character portrayals in movies or studying the impact of character roles on society, accurately identifying the active speaker plays a central role. It unravels the rich tapestry of interactions and expressions that shape our media experiences.
Active speaker detection has practical applications in various domains. In live events like conferences or panel discussions, accurately determining the speaker enhances the audience’s viewing experience, fosters a better understanding of discussions, and facilitates tracking of individual speakers. In recorded interviews, identifying the speaker improves comprehension and helps viewers follow the conversation effectively. In media production, knowing the active speaker streamlines the workflow by enabling efficient organization of footage, synchronization of audio and video, and precise editing decisions.
In summary, active speaker detection is a powerful tool that integrates audio and visual information to provide valuable insights into media content. It has applications in live events, interviews, and media production, enhancing the viewing experience, improving comprehension, and streamlining workflows.

In the field of active speaker detection (ASD) in audio-visual content, there are two main sources of information: i) audio-visual-activity-based information and ii) speakers’ identity information found in speech and faces. The former focuses on modeling visual activities in the lip region and its interaction with audio activity, while the latter examines the co-occurrences of speakers’ identities across modalities. However, both approaches have their limitations. AV-activity-based methods may confuse speaking activity with other similar actions and struggle with extreme poses or occluded lip regions. On the other hand, speakers’ identity-based methods require sufficient information to disambiguate speech-face associations and can struggle in scenarios where all speakers are visible or when speakers are off-screen.
In our ongoing exploration of active speaker detection in media content, we have made significant strides in understanding the intricate relationship between audio-visual activity and speakers’ identities. In our recent research paper titled “Audio-Visual Activity Guided Cross-Modal Identity Association for Active Speaker Detection” we revealed that both av-activity-based features and speakers’ identity-based methods possess unique components that, when combined strategically, yield a comprehensive and robust active speaker detection performance. This groundbreaking approach not only addresses the limitations of existing methods but also unlocks a deeper understanding of the dynamics between speech and visual cues in media content.
CMIA
In one of our papers, “Unsupervised active speaker detection in media content using cross-modal information” we proposed CMIA (Cross-Modal Identity Association). This framework combines speakers’ identity information from audio and visual modalities to accurately detect the active speaker in media content.
Here’s how CMIA works:
- We start by randomly selecting a face track as the active speaker face for each speaker-homogeneous speech segment.
- To capture identity information, we use speaker recognition embeddings and face recognition embeddings.
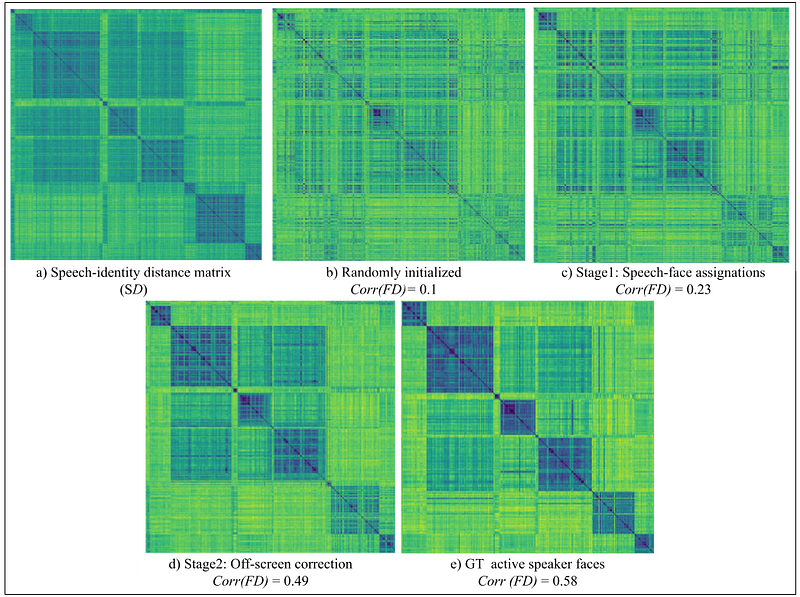
- We construct two matrices: a speech-identity distance matrix (SD) and a face-identity distance matrix (FD). These matrices represent the relative identity structure of speech segments and active speaker faces.
- We compute the resemblance between SD and FD using Pearson’s correlation, establishing the speech-face correspondence.
- Through an iterative process, we select the active speaker faces that maximize the resemblance between SD and FD.
- This framework provides an active speaker face track for each speech segment, even for off-screen speakers.
It’s important to note that SCMIA has limitations. It requires sufficient information to disambiguate characters in the video and may struggle with single-scene videos where all speakers are visible at all times.
Guided-CMIA
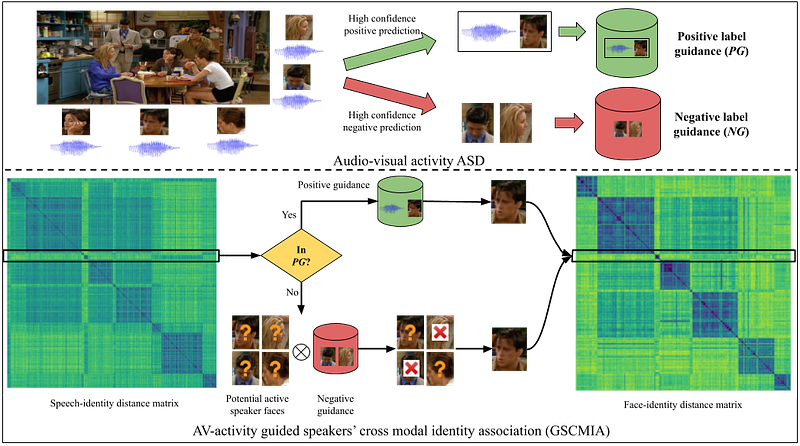
To address the limitations of CMIA, we propose a strategy to incorporate AV-activity information and complement it with speaker’s identity information. We utilize AV-activity-based models such as TalkNet and HiCA by leveraging the predictions from the AV-activity-based system to enhance CMIA. To minimize noise, we only utilize highly confident positive and negative predictions. We employ these predictions in two ways:
- Positive-label guidance: We collect speech segments where AV-activity predictions provide a highly confident speech-face association. For each speech segment, we select the face track with the maximum active speaker posteriors. These selected face tracks form the positive guidance set (PG). We use the AV-activity predictions as the ground truth for these speech segments and assign the selected face track as the active speaker face. By explicitly assigning the selected face track to the speech segment, we replicate scenarios where only the speaker’s face is visible, providing a clear signal for the speech-face association.
- Negative-label guidance: We take advantage of highly confident negative predictions from the AV-activity-based system. We collect face tracks with such negative predictions and form the negative guidance set (NG). We then remove the face tracks in NG from the candidate active speaker faces, as they correspond to non-speaking faces. This simplifies the speech-face association and addresses scenarios with off-screen speakers, where all non-speaking faces are eliminated. We refer to this approach as GSCMIA, which combines AV-activity information with speaker’s identity information.
By combining AV-activity information and speaker’s identity information, we enhance the robustness of active speaker detection, addressing the limitations of SCMIA. This strategy offers a comprehensive and reliable system for identifying the active speaker in media content.
Results
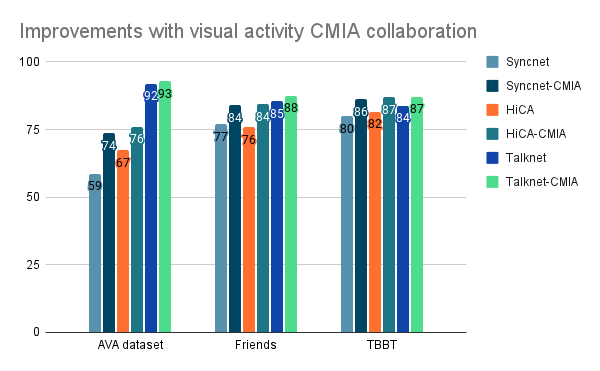
In our study, we compared various visual activity methods against their CMIA (Cross-Modal Identity Association) collaborated versions to evaluate the performance of active speaker detection in media content. Specifically, we examined the performance of Syncnet, HiCA, and Talknet, both individually and in collaboration with CMIA.
We observed that by incorporating CMIA, we were able to complement the visual activity-based methods and achieve improved results across all datasets. This enhancement was consistent across different methods and datasets, highlighting the effectiveness of the audio-visual activity-based guided CMIA approach.
Notably, when collaborating Talknet with CMIA, we achieved state-of-the-art (SOTA) performance in the AVA dataset, surpassing fully-supervised methods. This signifies the power of combining audio-visual activity information with speaker’s identity information in active speaker detection.
Furthermore, our collaboration of HiCA with CMIA demonstrated SOTA performance for weakly supervised methods. This showcases the significance of the guided CMIA approach in improving the accuracy and robustness of active speaker detection, even in scenarios with limited supervision.
Overall, our findings indicate that the audio-visual activity-based guided CMIA method outperforms other approaches in active speaker detection. By integrating audio-visual cues and speaker’s identity information, this framework provides a comprehensive and reliable solution for accurately identifying the active speaker in media content.
We are excited to showcase the impressive capabilities of our audio-visual guided cross-modal identity association system using a video clip from the VPCD dataset, featuring a scene from “The Big Bang Theory”. The faces of the speakers are elegantly outlined in green boxes, while all other faces are visually distinguished with red boxes. This intuitive visualization allows you to effortlessly identify the key speakers in the scene, bringing a new level of understanding to media content.
Here we showcase an example that demonstrates the practical application of our framework in real-world panel discussions, specifically in a TV news scenario. This example serves to highlight the effectiveness and versatility of our active speaker detection system.
We are proud to announce that the code for our innovative framework is publicly available on GitHub. This means that researchers and enthusiasts like you can explore and utilize our advanced system to enhance your own projects and delve deeper into the captivating world of active speaker detection.
Thanks for taking this deep dive with us into the fascinating world of active speaker detection in media content! We appreciate your time and interest in unraveling the dynamics between speech and visual cues. Stay tuned for more groundbreaking advancements and insights as we continue to revolutionize this field. Keep exploring, keep discovering, and keep making your media experiences even more immersive and engaging.
Github repo: https://github.com/rash1993/movie-asd
Paper: https://ieeexplore.ieee.org/abstract/document/10102534