
Unveiling Manifold learning
What a neural network is really doing?

Deep neural networks seem almost magical in their ability to solve complex problems like image recognition, language translation and game playing. They appear as mystic layers of matrix multiplications and non-linear activations. However, peering into their true essence through the lens of manifold learning unveils the mystery and sheds light on the genuine workings beneath the surface.
Neural Networks as Function Approximators
At its core, a neural network is deemed a function approximator. The Universal Approximation theorem boldly states that, armed with sufficient data, a neural network can model ANY function. This revelation is monumental!
A Geometric-Topological Perspective
An alternative lens, akin to my past life in Geometric Modeling, offers a geometric-topological perspective. Here, neural networks endeavor to grasp the ‘Manifold.’ But what exactly is a Manifold?
A Manifold represents a latent, domain-specific, smooth data surface in lower dimensions. Data points distant from it become incoherent, improbable, or impossible in that domain. The Manifold has its parametric coordinate system. Learning the manifold, at least approximately, is the goal of deep learning through a neural network. It involves discovering the underlying hypersurface function of the manifold. More technically, a manifold is a term used to classify spaces of arbitrary dimension. For every whole number, there exists a flat space known as Euclidean space, sharing characteristics similar to the Cartesian plane.
For instance, the Pythagorean theorem holds, ensuring the shortest distance between points is a straight line (unlike on a circle or sphere). The dimension of a Euclidean space is essentially the number of independent degrees of freedom, representing the directions one can move inside the space. A line has one dimension, an infinite plane has 2, and an infinite volume has 3, and so forth. Essentially, a manifold is a generalization of Euclidean space, where locally (in small areas) it approximates Euclidean space, but the entire space deviates from Euclidean properties when observed in its entirety.
Decoding Manifolds: A Technical Dive
Technically, a Manifold is a space of arbitrary dimension, a generalization of Euclidean space. Locally, it behaves like Euclidean space, but holistically, it deviates.
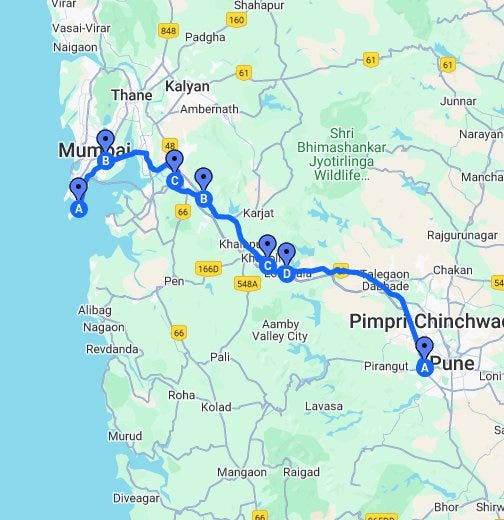
The map exists in 2D (for now, let’s assume a flat world, a planar surface), thus possessing x-y coordinates for all points. However, only specific points constitute the road.
For the driver, there’s a single variable while navigating — let’s call it ‘t.’ Even with bends and turns, the driver’s only moving variable is ‘t.’ This ‘t’ represents the manifold, specifically a road manifold. It’s one dimension less than the 2D x-y coordinates; now, we have a 1D variable ‘t.’ Moreover, the road must maintain continuity. Gradations of continuity exist, denoted as degrees like ‘0’ (C0/G0) indicating no road breakage — it shouldn’t have undriveable spots. Moving up, ‘1’ (C1/G0) signifies tangent continuity for constant velocity, providing a smooth feel. Higher degrees like ‘2’ (C2/G2) ensure smooth acceleration, and so forth.

All other data points on the map are undriveable, rendering them useless for a journey from Pune to Mumbai. The objective is to discover the road manifold using all the map’s data point coordinates. Theoretically termed ‘The Manifold Hypothesis,’ it posits that natural data forms lower-dimensional manifolds in its embedding space.
Neural Networks in Action
We wish to model or approximate the Manifolds using Neural Networks. The manifolds have to be flexible, continuous and smooth. Thus, merely relying on linear weighted summations does not inherently provide the required smoothness across neural network layers. This limitation prompts the introduction of activation functions to incorporate the necessary non-linearity. Activation functions prove to be highly effective in manipulating manifolds within the network architecture.
In the technical intricacies of neural networks, the fundamental objective of a classification algorithm is to disentangle and distinguish a set of interconnected manifolds.
LLMs: Language and Manifolds
Language, too, in my opinion (anyone to verify or counter?), serves as a manifold, and any expression deviating from it sounds linguistically odd and incorrect. Language Models (LLMs) delve into the intricacies of these manifolds with remarkable granularity, utilizing billions of parameters to achieve a remarkably human-like proficiency in speech.
However, the question arises: Is there a much smaller neural network, with significantly fewer parameters, capable of representing the linguistic manifold almost as effectively?

This question sparks a competitive race, in my opinion. Imagine a perfect SLM, a Small Language Model, designed specifically for linguistic intricacies. On the other hand, envision an SLLM, a Small Large Language Model, trained on an extensive and meticulously curated corpus, yet yielding a compact resultant model. The knowledge aspect can be supplemented with additional add-ons, such as adopters, whether generic or domain-specific. This pursuit aims to strike the optimal balance between model size and linguistic representation prowess.
Conclusion
In conclusion, the Manifold Hypothesis elucidates why machine learning excels in finding features and making accurate predictions from high-dimensional datasets. The realization that datasets exist in low-dimensional spaces means models need to focus on key features. These features, though, can be intricate functions of the original variables, prompting algorithms to uncover these embedding functions.
References
Click pic below or LinkedIn profile to know more about the author




