
Natural Language Modeling
Unlocking the Hidden Themes of Text with Topic Modeling
Discovering the Key Topics in Text Data with Latent Dirichlet Allocation (LDA) and Latent Semantic Analysis (LSA)
With the daily explosion of text data, it can be difficult to process and make sense of all the information. The sheer size of the data frequently makes it difficult to categorise documents based on their content or find specific documents relevant to a query.
To address these issues, topic modelling can be used to discover suitable texts based on a given topic. This technique entails extracting the important topics from a vast corpus of text data and revealing structural patterns that may not be obvious at first.
Topic modelling not only delivers useful insights, but it can also be used for a variety of activities such as document classification, information retrieval, and data visualisation.
There are several topic modelling algorithms available, each with its own set of advantages and disadvantages. In this blog article, we will look at two of the most commonly used algorithms in the field: Latent Semantic Analysis (LSA) and Latent Dirichlet Allocation (LDA). Both methods have been shown to be extremely effective in organising and analysing text data, and each of them have unique advantages and limitations that will be explained in detail.

Latent Semantic Analysis (LSA)
The Latent Semantic Analysis (LSA) algorithm is a popular topic modelling algorithm. At the core, it is a dimensionality reduction strategy based on the assumption that words used in similar contexts have similar meanings.
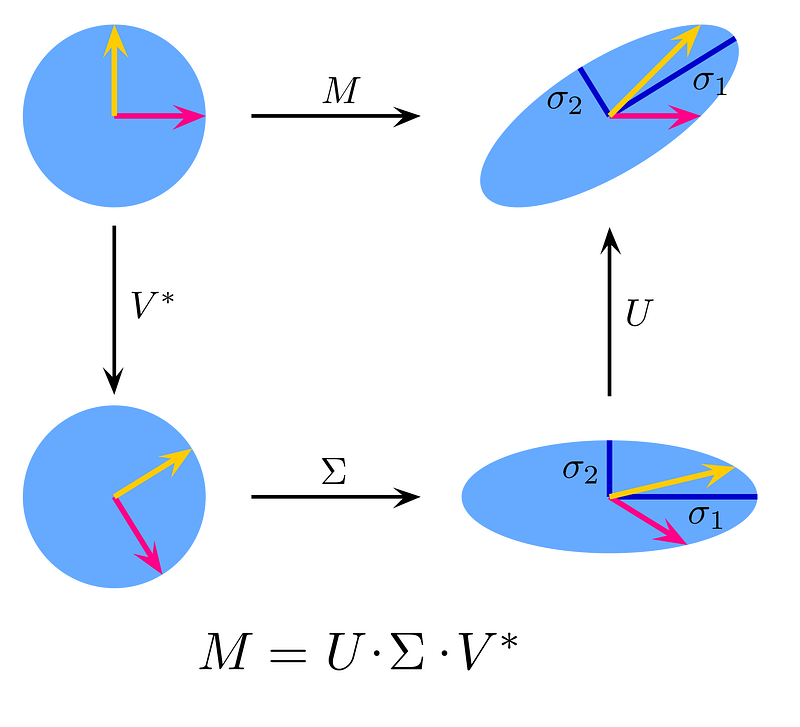
LSA uses document-term matrix for the corpus of texts, where rows correspond to terms and columns respond to document. The goal is to find a low-dimensional subspace that contains the data’s most essential semantic information.
We perform the dimensionality reduction of the document-term matrix using SVD to reduce the matrix into 3 matrices: U, ∑, V*
Where
- U represents distribution of words across the topics
- ∑ represents diagonal matrix of the association among the topics
- V* represents distribution of topics across the different documents
For evaluation, Coherence Models will be used to evaluate the identified subjects. The Coherence Model assesses the semantic similarity of words in a topic and assigns a topic’s coherence score, which quantifies how well the words in a topic fit together semantically.
Here’s an example of how to utilise the LSA algorithm with the Gensim library:
from gensim.models import LsiModel
from gensim.models.coherencemodel import CoherenceModel
# find the coherence score with a different number of topics
for i in range(2,11):
lsa = LsiModel(bow_corpus, num_topics=i, id2word=dictionary)
coherence_model = CoherenceModel(model=lsa, texts=df['clean_text'], dictionary=dictionary, coherence='c_v')
coherence_score = coherence_model.get_coherence()
print('Coherence score with {} clusters: {}'.format(i, coherence_score))Please refer to Kaggle notebook for the full code, including preprocessing of text and evaluation of results.
Advantages of LSA:
- LSA is a simple and easy algorithm that can be easily applied with minimum technical ability.
- LSA is computationally efficient and can handle enormous volumes of text data quickly, making it perfect for real-time applications.
- LSA can recognise similar words and concepts even when they are expressed using different terminology.
Disadvantages of LSA:
- LSA is limited to a bag-of-words approach, which means that it does not consider the sequence of words in a document or the context in which they are used.
- LSA can be affected by stop words, which are commonly used words that have little impact on the meaning of a document.
- LSA can be sensitive to rare terms, which means it may miss the significance of a topic if it is primarily communicated using rare words.
- LSA assumes independence of words, which means it ignores the relationships between words and the context in which they are employed.

Latent Dirichlet Allocation (LDA)
Latent Dirichlet Allocation (LDA) is a widely used method for identifying hidden topics in a big corpus of text data. It is built on the concept of a generative probabilistic model, which assumes that each document in the corpus may be represented as a combination of a small number of latent topics, with each topic representing a mixture of latent words.
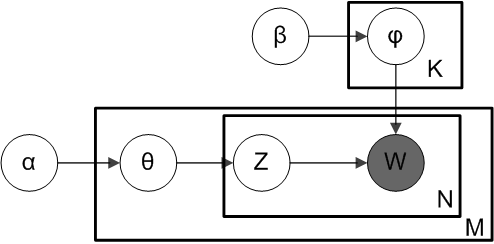
The basic principle behind LDA is to represent each document as a probability distribution over the latent topics, and each topic as a probability distribution over the words in the vocabulary, in order to describe the underlying structure of the text data. The algorithm then attempts to determine the optimal set of topics and words that best explain the observed data by maximising the observed data’s likelihood given the model parameters.
Here’s an example of how to utilise the LDA algorithm with the Gensim library:
# find the coherence score with a different number of topics
num_of_topics = -1
max_coherence = -np.inf
for i in range(2,11):
lda_model = LdaMulticore(corpus=bow_corpus, id2word=dictionary, num_topics=i, passes=4)
coherence_model = CoherenceModel(model=lda_model, texts=df['clean_text'], dictionary=dictionary, coherence='c_v')
coherence_score = coherence_model.get_coherence()
if coherence_score > max_coherence:
max_coherence = coherence_score
num_of_topics = i
print('Coherence score with {} clusters: {}'.format(i, coherence_score))Please refer to Kaggle notebook for the full code, including preprocessing of text and evaluation of results.
Advantages of LDA:
- LDA considers the relationships between words as well as the context in which they are used, resulting in a more accurate representation of the topics in a text corpus.
- LDA can effectively handle sparse data, which means it can detect subjects even when only a limited number of documents express them.
- LDA can be parallelised, which means it can be divided into numerous smaller tasks that can run concurrently, lowering processing time.
Disadvantages of LDA:
- LDA can be computationally demanding, especially when dealing with big amounts of text data, making it difficult to use in real-time applications.
- LDA is susceptible to hyperparameters, which are parameters that govern the behaviour of the algorithm. Choosing the incorrect hyperparameters can result in poor performance.
- LDA presupposes that all documents are connected and can be described as a mix of subjects, which might not always be the case.

Conclusion
To work with massive amounts of text data, topic modelling is a critical technique in data science. The capacity to reveal hidden structure and discover latent subjects within text data quickly and efficiently allows for a better grasp of the information contained within it. This technique can yield useful insights and can be applied to a variety of applications, including text classification and information retrieval.
There are various topic modelling algorithms available, each with its own set of advantages and disadvantages. LDA and LSA are the most often used topic modelling algorithms, and they may be easily implemented in Python utilising libraries such as Gensim and scikit-learn. Each of these methods has specific pros and cons, hence please make sure to evaluate the specific objectives of the project, prior to choosing either.
The following post in the series will delve into the mathematics of Latent Dirichlet Allocation & Top2Vec. If you’re interested in learning more, feel free to follow/subscribe.
References:
- https://stackabuse.com/removing-stop-words-from-strings-in-python/
- https://radimrehurek.com/gensim_3.8.3/auto_examples/tutorials/run_lda.html
- https://radimrehurek.com/gensim/models/coherencemodel.html
- Associated Kaggle Notebook: https://www.kaggle.com/code/azimuthal01/topic-modelling/notebook
If you have read so far, a big thank you for reading! I hope you find this article to be helpful. If you’d like, add me on LinkedIn!
Good luck this week, Pratyush




{kind=link}
{kind=link}