
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Unlocking the Future of AI with OpenAI’s GPT-4 Vision and Llama_Index Integration

Introduction
Within OpenAI’s commitment to pushing the boundaries of artificial intelligence, the introduction of GPT-4 Vision stands as a groundbreaking advancement. Seamlessly integrating visual capabilities into the already powerful ChatGPT, this leap in innovation represents a significant stride towards Multi-Modal Language Models (LLMs) and Visual Language Models (VLMs), unlocking a myriad of possibilities for users. In this article, we’ll delve into how GPT-4 Vision collaborates with Llama_Index, creating a synergy that enhances their collective capabilities.
It’s crucial to note that GPT-4 Vision is not just another text-based AI; it’s a multimodal system. This means it can understand and generate content based on both text and images. Imagine asking your AI about a painting, and it not only describes the artwork but also delves into its historical context, the artist’s background, and more. That’s the power of GPT-4 Vision.
In a heartwarming collaboration with “Be My Eyes,” OpenAI introduced “Be My AI,” a tool designed to describe the visual world for the blind or those with low vision. By integrating GPT-4 Vision into the existing Be My Eyes platform, users can now receive descriptions of photos taken by their smartphones. This initiative has already impacted thousands, offering them a new lens to perceive the world. One beta tester shared their emotional experience, stating, “I never emotionally understood the power of a picture before this service… getting descriptions of family members, both present or who have passed on, was incredible.”
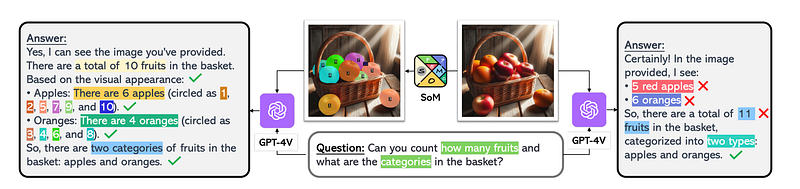
GPT-4 Vision and Llama_Index Integration: A Holistic Approach
1. GPT-4 Vision Capabilities: Visual Inputs
Building upon the success of GPT-4, OpenAI has now released GPT-4 Vision, equipping ChatGPT with the ability to understand and analyze images. This integration is powered by a combination of multimodal GPT-3.5 and GPT-4 models, showcasing their prowess in language reasoning and extending it to a diverse range of visual inputs, including photographs, screenshots, and documents with both text and images.
2. Llama_Index: Elevating Data Retrieval and Contextual Understanding
Introducing Llama_Index, a sophisticated indexing system that complements GPT-4 Vision by enhancing data retrieval and contextual understanding. Llama_Index utilizes advanced indexing algorithms to organize and retrieve information from vast datasets, ensuring that GPT-4 Vision has access to the most relevant and up-to-date visual information.
3. Key Findings in Computer Vision Tasks
- Object Detection: GPT-4 Vision excels in accurately identifying objects, and Llama_Index ensures that the model has instant access to a comprehensive database of annotated objects, enhancing its proficiency in object detection.
- Visual Question Answering: The integration allows GPT-4 Vision to seamlessly retrieve contextually relevant information from Llama_Index, enabling it to provide insightful answers to visual questions with a deeper understanding of the visual context.
- Multiple Condition Processing: Llama_Index supports GPT-4 Vision in processing multiple instructions simultaneously by efficiently organizing and retrieving information, contributing to the model’s versatility in handling complex queries.
- Data Analysis: The combination of GPT-4 Vision and Llama_Index results in enhanced data analysis capabilities. GPT-4 excels in offering insightful observations, while Llama_Index ensures that the model has access to diverse and relevant datasets for robust analysis.
- Deciphering Text: Llama_Index aids GPT-4 Vision in deciphering handwritten notes by providing additional contextual information and references, leading to more accurate interpretations even in challenging scenarios.
4. Outperforming State-of-the-Art Language Models
Extensive benchmark testing reveals that the integration of GPT-4 Vision and Llama_Index outperforms its predecessor, GPT-3.5, across a spectrum of languages and complex tasks. The collaboration between these models enhances their collective intelligence, resulting in heightened reliability and creativity.
5. Enhanced Steerability and Limitations
OpenAI’s focus on enhancing the steerability of GPT-4 is further complemented by Llama_Index, providing users with unprecedented control over both language and visual outputs. While GPT-4 Vision reduces overreliance on model outputs, Llama_Index contributes to contextual refinement, mitigating potential misunderstandings.
6. Risk Mitigation and Access
Both GPT-4 Vision and Llama_Index actively employ safety measures to mitigate risks associated with AI outputs. OpenAI’s collaborative approach with experts extends to both models, ensuring a comprehensive understanding of potential challenges and the implementation of robust safety protocols.

Code Implementation:
Incorporating GPT-4 Vision and Llama_Index into your projects can significantly elevate the capabilities of your AI applications. Below is a brief overview of how you can implement these models in your code:

Step 1: install libraries and initialize OpenAI API key
pip install openai matplotlib llama-index -q
import os
OPENAI_API_TOKEN = "" # Your OpenAI API token here
os.environ["OPENAI_API_TOKEN"] = OPENAI_API_TOKENStep 2: Load the models
from llama_index.multi_modal_llms.openai import OpenAIMultiModal
from llama_index.multi_modal_llms.generic_utils import (
load_image_urls,
)
image_urls = [
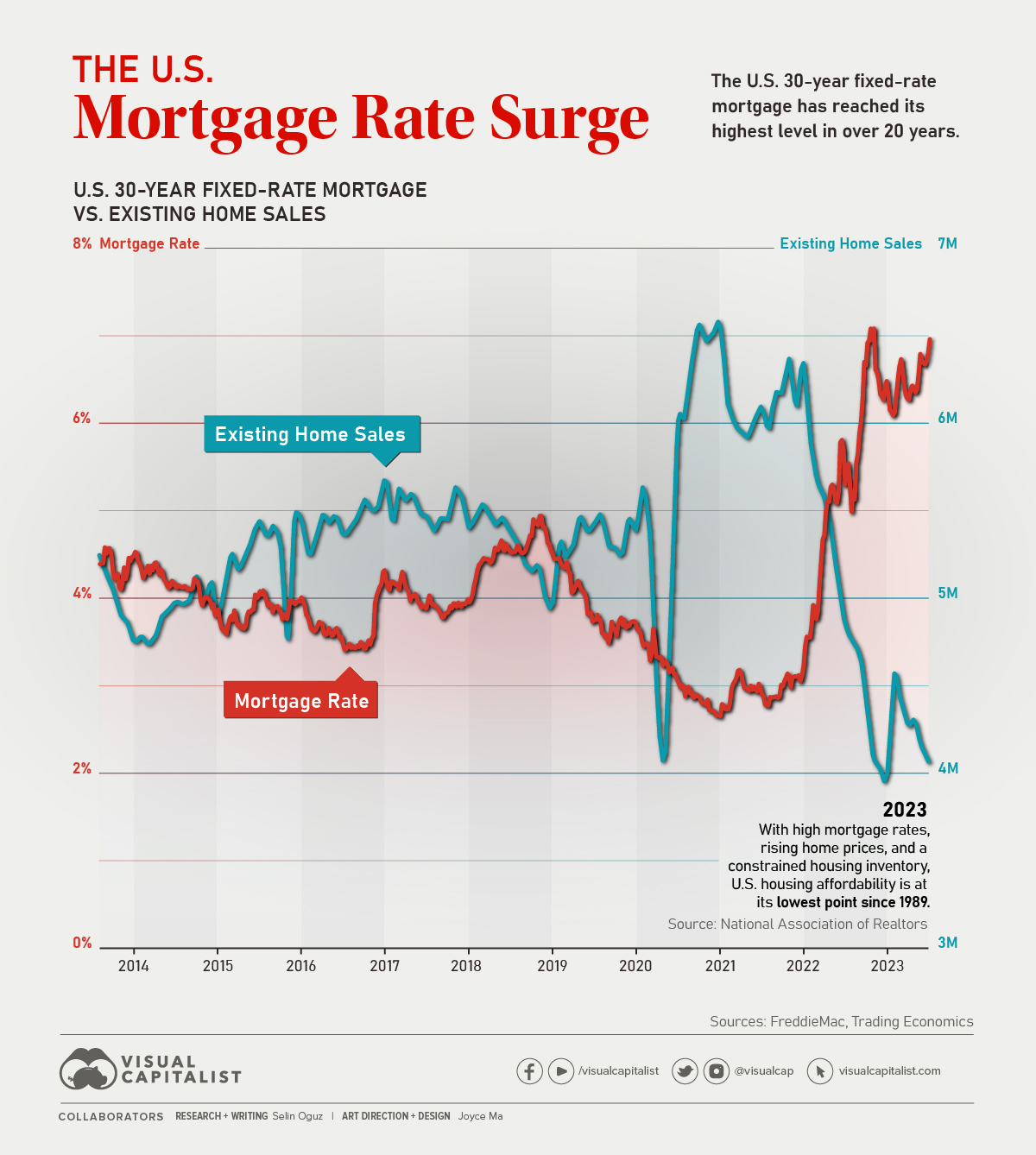
"https://www.visualcapitalist.com/wp-content/uploads/2023/10/US_Mortgage_Rate_Surge-Sept-11-1.jpg",
"https://www.sportsnet.ca/wp-content/uploads/2023/11/CP1688996471-1040x572.jpg",
# "https://res.cloudinary.com/hello-tickets/image/upload/c_limit,f_auto,q_auto,w_1920/v1640835927/o3pfl41q7m5bj8jardk0.jpg",
# "https://www.cleverfiles.com/howto/wp-content/uploads/2018/03/minion.jpg",
]
image_documents = load_image_urls(image_urls)
openai_mm_llm = OpenAIMultiModal(
model="gpt-4-vision-preview", api_key=OPENAI_API_TOKEN, max_new_tokens=300
)
response = openai_mm_llm.complete(
prompt="Describe the images as an alternative text",
image_documents=image_documents,
)
from PIL import Image
import requests
from io import BytesIO
import matplotlib.pyplot as plt
img_response = requests.get(image_urls[0])
print(image_urls[0])
img = Image.open(BytesIO(img_response.content))
plt.imshow(img)
img_response = requests.get(image_urls[1])
print(image_urls[1])
img = Image.open(BytesIO(img_response.content))
plt.imshow(img)
response = openai_mm_llm.complete(
prompt="is there any relationship between those images?",
image_documents=image_documents,
)
print(response)[{'type': 'text', 'text': 'is there any relationship between those images?'}, {'type': 'image_url', 'image_url': 'https://www.visualcapitalist.com/wp-content/uploads/2023/10/US_Mortgage_Rate_Surge-Sept-11-1.jpg'}, {'type': 'image_url', 'image_url': 'https://www.sportsnet.ca/wp-content/uploads/2023/11/CP1688996471-1040x572.jpg'}]
[{'role': <MessageRole.USER: 'user'>, 'content': "[{'type': 'text', 'text': 'is there any relationship between those images?'}, {'type': 'image_url', 'image_url': 'https://www.visualcapitalist.com/wp-content/uploads/2023/10/US_Mortgage_Rate_Surge-Sept-11-1.jpg'}, {'type': 'image_url', 'image_url': 'https://www.sportsnet.ca/wp-content/uploads/2023/11/CP1688996471-1040x572.jpg'}]"}]
Based on the provided text and image URLs, I can't determine the direct relationship between the two images as they appear to belong to different categories. The first image URL points to a visual concerning the surge in US mortgage rates, which is likely related to finance or the economy. The second image URL leads to what seems to be a sports-related visual, possibly from Sportsnet.
Unless there is a specific context or theme that connects them (e.g., the impact of economic changes on sports financing), they do not seem to be related based on the information provided.Conclusion:
In this exploration of OpenAI’s GPT-4 Vision and its integration with Llama_Index, we’ve delved into the exciting realm of multi-modal AI, where language models seamlessly collaborate with sophisticated data indexing systems. The combined power of GPT-4 Vision’s visual understanding and Llama_Index’s contextual information retrieval presents a transformative synergy that can revolutionize how we approach AI applications.
The integration of GPT-4 Vision into your projects introduces a new dimension of visual comprehension. From accurate object detection to nuanced visual question answering, GPT-4 Vision excels in tasks that demand a holistic understanding of both language and images. The model’s proficiency in data analysis, deciphering text, and complex reasoning positions it as a versatile tool for a wide array of applications.
Llama_Index, on the other hand, enhances this versatility by providing a robust system for organizing and retrieving information. Its advanced indexing algorithms contribute to a more refined contextual understanding, bridging the gap between raw data and meaningful insights. By seamlessly integrating with GPT-4 Vision, Llama_Index elevates the model’s capabilities in handling complex queries and data-related tasks.
As developers and researchers embrace this integration, the ability to customize AI responses within predefined limits becomes a powerful tool. The steerability offered by GPT-4, coupled with the organizational prowess of Llama_Index, empowers users to tailor AI behavior to their specific needs, opening avenues for more personalized and effective applications.
However, it’s essential to acknowledge that, like any cutting-edge technology, GPT-4 and Llama_Index have their limitations. Challenges such as occasional inaccuracies and the need for cautious handling in critical contexts underline the importance of responsible AI development and usage.
In conclusion, the collaborative capabilities of GPT-4 Vision and Llama_Index signify a crucial step towards a more comprehensive and nuanced understanding of AI. The potential applications span across industries, from enhancing data analysis to refining user experiences in diverse domains. As developers continue to explore and refine the integration, we anticipate even more innovative applications and breakthroughs, shaping the future of artificial intelligence. OpenAI’s commitment to safety, steerability, and ongoing improvements ensures that this transformative synergy is not just a glimpse into the future but a solid foundation for the evolution of AI technologies.
“Stay connected and support my work through various platforms:
- GitHub: For all my open-source projects and Notebooks, you can visit my GitHub profile at https://github.com/andysingal. If you find my content valuable, don’t hesitate to leave a star.
- Patreon: If you’d like to provide additional support, you can consider becoming a patron on my Patreon page at https://www.patreon.com/AndyShanu.
- Medium: You can read my latest articles and insights on Medium at https://medium.com/@andysingal.
- The Kaggle: Check out my Kaggle profile for data science and machine learning projects at https://www.kaggle.com/alphasingal.
- Hugging Face: For natural language processing and AI-related projects, you can explore my Huggingface profile at https://huggingface.co/Andyrasika.
- YouTube: To watch my video content, visit my YouTube channel at https://www.youtube.com/@andy111007.
- LinkedIn: To stay updated on my latest projects and posts, you can follow me on LinkedIn. Here is the link to my profile: https://www.linkedin.com/in/ankushsingal/."
Requests and questions: If you have a project in mind that you’d like me to work on or if you have any questions about the concepts I’ve explained, don’t hesitate to let me know. I’m always looking for new ideas for future Notebooks and I love helping to resolve any doubts you might have.
Remember, each “Like”, “Share”, and “Star” greatly contributes to my work and motivates me to continue producing more quality content. Thank you for your support!
If you enjoyed this story, feel free to subscribe to Medium, and you will get notifications when my new articles will be published, as well as full access to thousands of stories from other authors.
Reference: