
Unlock the Power of LangChain to Summarize Text
A Simple Guide to Summarize Lengthy PDFs, Docs, and URLs with LangChain
Explore the latest in the LangChain series! Dive into seamless techniques for integrating LangChain to extract and summarize content from diverse formats like PDFs, DOCs, plain text, or even directly from a URL.
How LangChain Makes Large Language Models More Powerful: Part 1
How LangChain Makes Large Language Models More Powerful: Part 2
Vector Database: Empowering Next-Gen Applications
Imagine you are researching a complex topic. You find a number of relevant articles and books, but you don’t have time to read them all. You think LLMs would be a quick help, but then token limits and outdated training data get in the way!!!


But wait…with LangChain, it’s possible!!!
LangChain can help resolve the issue of limited token size or summarizing content from the web URL that the LLM is not trained on.
LangChain is a powerful text summarization library that uses large language models (LLMs) to generate summaries of text in a variety of formats, including PDFs, Docs, and web pages.
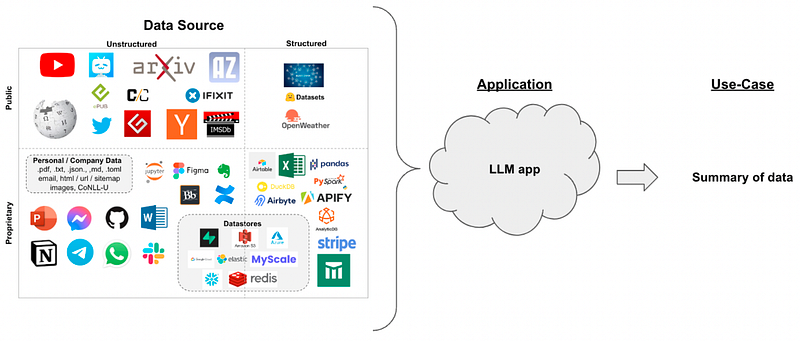
With LangChain and LLMs, you can instantly summarize any text, regardless of its length or complexity, even if the LLM is not trained on that data.
so, how to pass large PDFs or documents or URLs into the LLM’s context window?
Stuff
One way to summarize multiple documents with LangChain is to “stuff” or “fill” all of the document contents into a single prompt in case the document content fits within the size of the prompt.
This is done using the load_summarize_chain() function with the chain_type="stuff" parameter. This function takes a list of documents or text as input, inserts all of the text contents into a prompt, and passes that prompt to the LLM. The LLM then generates a final summary of the documents based on the prompt.
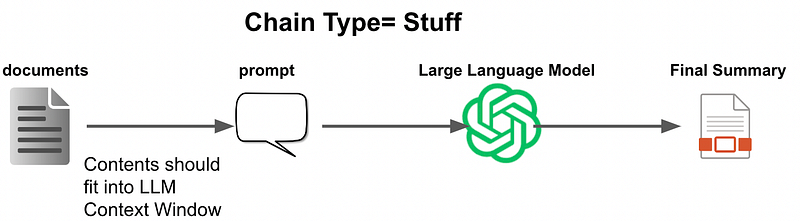
It is important to note that the content of all documents should not exceed the LLM’s context window. The context window is the maximum number of tokens that the LLM can process at a time.
For example, the ChatGPT model gpt-3.5-turbo-16k has a context window of 16K tokens, and the Anthropic Claude-2 model has a context window of 100K tokens.
Install the following libraries.
pip install python-dotenv langchain openai pypdf pymupdf
The code below uses LangChain to summarize a document using Docx2txtLoader The large text is loaded and split using load_and_split(). The text chunks are stuffed in the prompt, which is summarized using LangChains’s load_summarize_chain passing it to the LLM and using the chain_type as stuff
from dotenv import load_dotenv
from langchain.document_loaders import Docx2txtLoader
from langchain.llms import OpenAI
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import CharacterTextSplitter
from langchain.prompts import PromptTemplate
import textwrap
import os
# API Keys for OPENAI
LLM_KEY=os.environ.get("OPENAI_API_KEY")
# Reading all the pages of the PDF file using PyPDFLoader
filename="./downloads/CAP Theorem.docx"
text=""
#Docx2txtLoader loads the Document
loader=Docx2txtLoader(filename)
#Load Documents and split into chunks
text = loader.load_and_split()
# Define prompt
prompt_template = """Write a concise summary of the following:
"{text}"
CONCISE SUMMARY:"""
prompt_template = PromptTemplate(template=prompt_template,
input_variables=["text"])
#Define the LLM
# here we are using OpenAI's ChatGPT
llm=OpenAI(temperature=0)
#Generating the document summary by stuffing the contents intot he prompt
chain = load_summarize_chain(llm, chain_type="stuff", prompt=prompt_template)
summarized_text=chain.run(text)
summarized_text = textwrap.fill(summarized_text,
width=100,
break_long_words=False,
replace_whitespace=False)
print(summarized_text)
Advantages of Stuff Chain:
- Cost-Effective: Require a single call to the LLM, making them cost-effective in contrast to other methods, such as the Refine chain and Map-Reduce, which require multiple calls to the LLM.
- Comprehensive Summaries: With access to all data at once, LLM can generate a more comprehensive and informative summary than it would be able to generate if it were only given access to a subset of the data
Limitation of Stuff Chains:
- Token Constraint: The LLM’s token limit can hinder the summarization of larger texts, making single-call methods less ideal for large-text summarization.
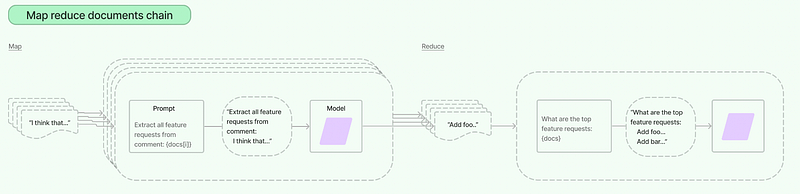
Map Reduce
Another method for text summarization in LangChain is a multi-stage summarization approach called Map-Reduce.
Map-Reduce works by first mapping each document or document chunk to an individual summary. This is done using a separate LLM call for each document or text chunk.
Once all of the individual summaries have been generated, they are then reduced to combine them into a single global summary. This is also done using a separate LLM call.
The code below uses LangChain to summarize the PDF document- Man’s Search for Meaning by Viktor Frankl. It first loads the PDF file using PyPDFLoader and then extracts the text from the PDF. The large text is then split into smaller chunks using LangChain’s CharacterTextSplitter . If there are multiple texts from different documents, then create_documents() create documents from a list of texts. The text chunks are finally summarized using LangChains’s load_summarize_chain passing it to the LLM and using map_reduce as the the chain_type
from dotenv import load_dotenv
from langchain.document_loaders import PyPDFLoader
from langchain.llms import OpenAI
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import CharacterTextSplitter
import os
from langchain.llms import OpenAI
# API Keys for OPENAI
LLM_KEY=os.environ.get("OPENAI_API_KEY")
# Reading all the pages of the PDF file using PyPDFLoader
filename="./Documents/Reading Material/Mans Search For Meaning.pdf"
text=""
#PYPDFLoader loads a list of PDF Document objects
loader=PyPDFLoader(filename)
pages = loader.load()
for page in pages:
text+=page.page_content
text= text.replace('\t', ' ')
print(len(text))
#splits a long document into smaller chunks that can fit into the LLM's
#model's context window
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=100
)
#create_documents() create documents froma list of texts
texts = text_splitter.create_documents([text])
#Define the LLM
# here we are using OpenAI's ChatGPT
llm=OpenAI(temperature=0)
#Generating the document summary using Map reduce
chain = load_summarize_chain(llm, chain_type="map_reduce")
summarized_text=chain.run(texts)
Advantages of Map-Reduce Chain:
- Handles Large Texts: Map-Reduce can summarize multiple documents as well as large texts as it breaks down large documents into smaller chunks and processes each chunk separately.
- Speed: Processes documents or text chunks in parallel, significantly accelerating the summarization process.
Limitations of Map-Reduce Chain:
- Cost: Each text or chunk requires an individual LLM call, which can get expensive with high-end models.
- Information loss: When combining the individual summaries into the final summary, some information may be lost due to LLM's ability to process a limited number of tokens at a time.
Refine
Text in PDFs, Docs, and URLs can also be summarized using LangChain’s Refine method.
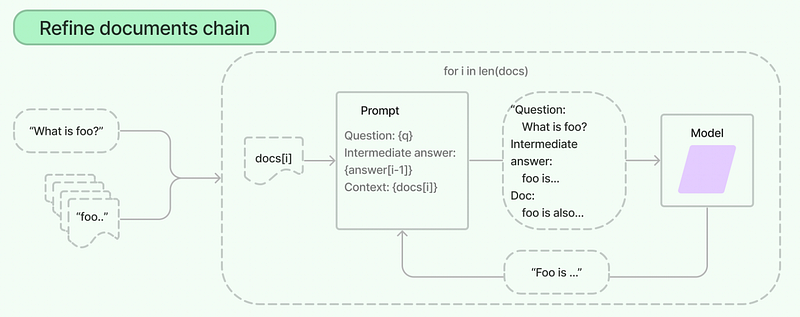
Refine chain iterates over all the input documents one by one. It summarizes the content of one document and then uses this intermediate summary, along with the next document, as a prompt for the LLM to create a new summary.
The code below uses LangChain to summarize the podcast-rethinking-with-adam-grant. It first reads the content of the URL using WebBaseLoader The large text is then split into smaller chunks using LangChain’s CharacterTextSplitter . If there are multiple texts from different documents, then create_documents() create documents from a list of texts. The text chunks are finally summarized using LangChains’s load_summarize_chain passing it to the LLM and using the chain_type as refine.
Here, we have supplied the prompts as well as returned the intermediate steps.
from dotenv import load_dotenv
from langchain.document_loaders import WebBaseLoader
from langchain.llms import OpenAI
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import CharacterTextSplitter
from langchain.prompts import PromptTemplate
import fitz
import os
from langchain.llms import OpenAI, GPT4All
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# API Keys for OPENAI
LLM_KEY=os.environ.get("OPENAI_API_KEY")
# Reading URL and creating a summary of the podcast
url="https://www.ted.com/podcasts/rethinking-with-adam-grant/life-lessons-from-sports-with-jody-avirgan-transcript"
text=""
#WebBaseLoader loads text from HTML webpages into a document format
loader=loader = WebBaseLoader(url)
pages = loader.load()
for page in pages:
text+=page.page_content
text= text.replace('\t', ' ')
print(len(text))
#splits a long document into smaller chunks that can fit into the LLM's
#model's context window
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=100
)
#create the documents from list of texts
texts = text_splitter.create_documents([text])
prompt_template = """Write a concise summary of the following:
{text}
CONCISE SUMMARY:"""
prompt = PromptTemplate.from_template(prompt_template)
refine_template = (
"Your job is to produce a final summary with key learnings\n"
"We have provided an existing summary up to a certain point: {existing_answer}\n"
"We have the opportunity to refine the existing summary"
"(only if needed) with detailed context below.\n"
"------------\n"
"{text}\n"
"------------\n"
"Given the new context, refine the original summary"
"If the context isn't useful, return the original summary."
)
refine_prompt = PromptTemplate.from_template(refine_template)
#Define the LLM
# here we are using OpenAI's ChatGPT
llm=select_llm()
refine_chain = load_summarize_chain(
llm,
chain_type="refine",
question_prompt=prompt,
refine_prompt=refine_prompt,
return_intermediate_steps=True,
)
refine_outputs = refine_chain({'input_documents': texts})
print( refine_outputs['output_text'])
Advantages of Refine Chain:
- Tailored for Large Sets: Refine chain works well for summarizing multiple documents that exceed the LLM’s token limit since it processes one text chunk or document at a time.
Limitations of Refine Chain:
- Costly: Refine chain makes multiple calls to the LLM to summarize the contents, making them expensive.
- Cross-Referencing Issues: The Refine chain may not be effective at summarizing documents that frequently cross-reference one another because the LLM may not be able to keep track of all of the references.
- Missed Details: Refine chains are also not suitable for tasks needing detailed insights from multiple documents because the LLM is only able to process a limited number of tokens at a time
Conclusion:
To summarize a text with LangChain:
- Stuff-Chain: Simply input the entire text into a prompt that fits within the LLM’s token limit and generate the summary.
- Map-Reduce: Break the large text into smaller chunks, summarize each chunk separately, and then combine those chunk summaries for an overall summary.
- Refine Chain: Break the large text into smaller chunks, and start by summarizing the first chunk. Review the summary and give feedback to the LLM to refine the summary. Repeat the process for each chunk and keep refining the summary.
The best method depends on the size of the text, its complexity in terms of referencing ideas, and your available time and budget.





